 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuppeteer: Rig and Animate Your 3D Models
Aug 14, 2025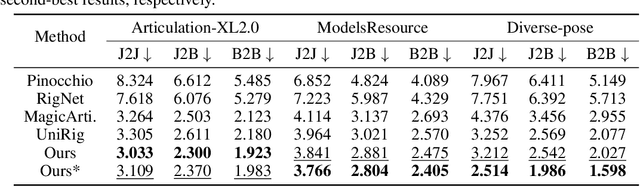

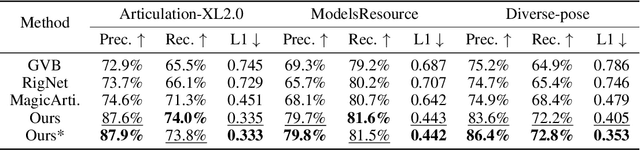

Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
MagicArticulate: Make Your 3D Models Articulation-Ready
Feb 18, 2025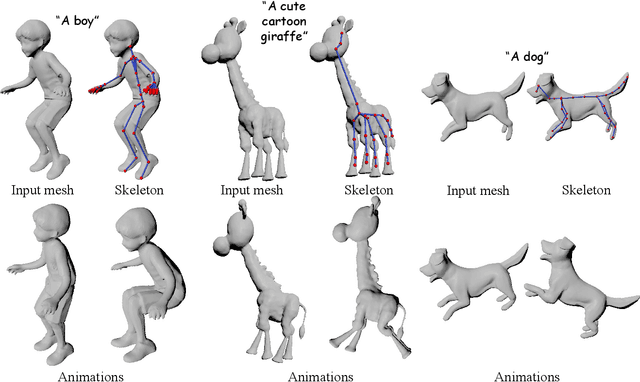
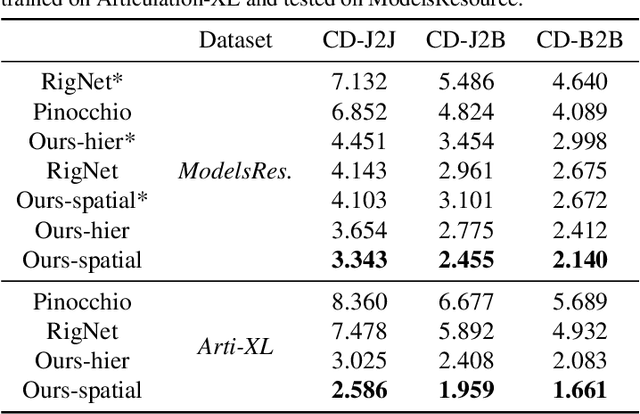
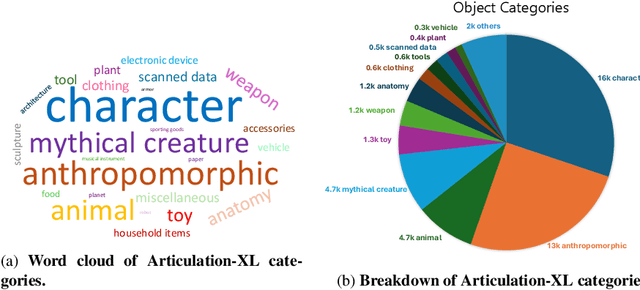
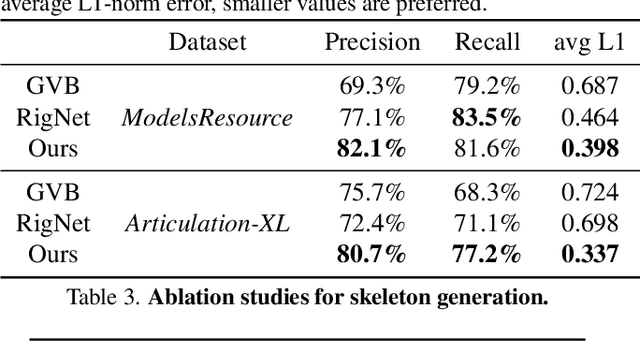
With the explosive growth of 3D content creation, there is an increasing demand for automatically converting static 3D models into articulation-ready versions that support realistic animation. Traditional approaches rely heavily on manual annotation, which is both time-consuming and labor-intensive. Moreover, the lack of large-scale benchmarks has hindered the development of learning-based solutions. In this work, we present MagicArticulate, an effective framework that automatically transforms static 3D models into articulation-ready assets. Our key contributions are threefold. First, we introduce Articulation-XL, a large-scale benchmark containing over 33k 3D models with high-quality articulation annotations, carefully curated from Objaverse-XL. Second, we propose a novel skeleton generation method that formulates the task as a sequence modeling problem, leveraging an auto-regressive transformer to naturally handle varying numbers of bones or joints within skeletons and their inherent dependencies across different 3D models. Third, we predict skinning weights using a functional diffusion process that incorporates volumetric geodesic distance priors between vertices and joints. Extensive experiments demonstrate that MagicArticulate significantly outperforms existing methods across diverse object categories, achieving high-quality articulation that enables realistic animation. Project page: https://chaoyuesong.github.io/MagicArticulate.
High Quality Human Image Animation using Regional Supervision and Motion Blur Condition
Sep 29, 2024



Recent advances in video diffusion models have enabled realistic and controllable human image animation with temporal coherence. Although generating reasonable results, existing methods often overlook the need for regional supervision in crucial areas such as the face and hands, and neglect the explicit modeling for motion blur, leading to unrealistic low-quality synthesis. To address these limitations, we first leverage regional supervision for detailed regions to enhance face and hand faithfulness. Second, we model the motion blur explicitly to further improve the appearance quality. Third, we explore novel training strategies for high-resolution human animation to improve the overall fidelity. Experimental results demonstrate that our proposed method outperforms state-of-the-art approaches, achieving significant improvements upon the strongest baseline by more than 21.0% and 57.4% in terms of reconstruction precision (L1) and perceptual quality (FVD) on HumanDance dataset. Code and model will be made available.
ShowRoom3D: Text to High-Quality 3D Room Generation Using 3D Priors
Dec 20, 2023We introduce ShowRoom3D, a three-stage approach for generating high-quality 3D room-scale scenes from texts. Previous methods using 2D diffusion priors to optimize neural radiance fields for generating room-scale scenes have shown unsatisfactory quality. This is primarily attributed to the limitations of 2D priors lacking 3D awareness and constraints in the training methodology. In this paper, we utilize a 3D diffusion prior, MVDiffusion, to optimize the 3D room-scale scene. Our contributions are in two aspects. Firstly, we propose a progressive view selection process to optimize NeRF. This involves dividing the training process into three stages, gradually expanding the camera sampling scope. Secondly, we propose the pose transformation method in the second stage. It will ensure MVDiffusion provide the accurate view guidance. As a result, ShowRoom3D enables the generation of rooms with improved structural integrity, enhanced clarity from any view, reduced content repetition, and higher consistency across different perspectives. Extensive experiments demonstrate that our method, significantly outperforms state-of-the-art approaches by a large margin in terms of user study.
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
Nov 27, 2023



This paper studies the human image animation task, which aims to generate a video of a certain reference identity following a particular motion sequence. Existing animation works typically employ the frame-warping technique to animate the reference image towards the target motion. Despite achieving reasonable results, these approaches face challenges in maintaining temporal consistency throughout the animation due to the lack of temporal modeling and poor preservation of reference identity. In this work, we introduce MagicAnimate, a diffusion-based framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity. To achieve this, we first develop a video diffusion model to encode temporal information. Second, to maintain the appearance coherence across frames, we introduce a novel appearance encoder to retain the intricate details of the reference image. Leveraging these two innovations, we further employ a simple video fusion technique to encourage smooth transitions for long video animation. Empirical results demonstrate the superiority of our method over baseline approaches on two benchmarks. Notably, our approach outperforms the strongest baseline by over 38% in terms of video fidelity on the challenging TikTok dancing dataset. Code and model will be made available.
XAGen: 3D Expressive Human Avatars Generation
Nov 22, 2023


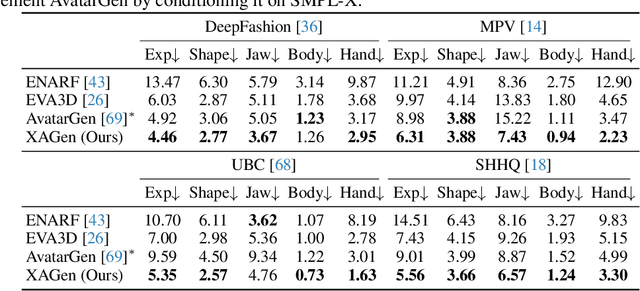
Recent advances in 3D-aware GAN models have enabled the generation of realistic and controllable human body images. However, existing methods focus on the control of major body joints, neglecting the manipulation of expressive attributes, such as facial expressions, jaw poses, hand poses, and so on. In this work, we present XAGen, the first 3D generative model for human avatars capable of expressive control over body, face, and hands. To enhance the fidelity of small-scale regions like face and hands, we devise a multi-scale and multi-part 3D representation that models fine details. Based on this representation, we propose a multi-part rendering technique that disentangles the synthesis of body, face, and hands to ease model training and enhance geometric quality. Furthermore, we design multi-part discriminators that evaluate the quality of the generated avatars with respect to their appearance and fine-grained control capabilities. Experiments show that XAGen surpasses state-of-the-art methods in terms of realism, diversity, and expressive control abilities. Code and data will be made available at https://showlab.github.io/xagen.
MagicEdit: High-Fidelity and Temporally Coherent Video Editing
Aug 28, 2023



In this report, we present MagicEdit, a surprisingly simple yet effective solution to the text-guided video editing task. We found that high-fidelity and temporally coherent video-to-video translation can be achieved by explicitly disentangling the learning of content, structure and motion signals during training. This is in contradict to most existing methods which attempt to jointly model both the appearance and temporal representation within a single framework, which we argue, would lead to degradation in per-frame quality. Despite its simplicity, we show that MagicEdit supports various downstream video editing tasks, including video stylization, local editing, video-MagicMix and video outpainting.
MagicAvatar: Multimodal Avatar Generation and Animation
Aug 28, 2023This report presents MagicAvatar, a framework for multimodal video generation and animation of human avatars. Unlike most existing methods that generate avatar-centric videos directly from multimodal inputs (e.g., text prompts), MagicAvatar explicitly disentangles avatar video generation into two stages: (1) multimodal-to-motion and (2) motion-to-video generation. The first stage translates the multimodal inputs into motion/ control signals (e.g., human pose, depth, DensePose); while the second stage generates avatar-centric video guided by these motion signals. Additionally, MagicAvatar supports avatar animation by simply providing a few images of the target person. This capability enables the animation of the provided human identity according to the specific motion derived from the first stage. We demonstrate the flexibility of MagicAvatar through various applications, including text-guided and video-guided avatar generation, as well as multimodal avatar animation.
AvatarGen: A 3D Generative Model for Animatable Human Avatars
Nov 26, 2022
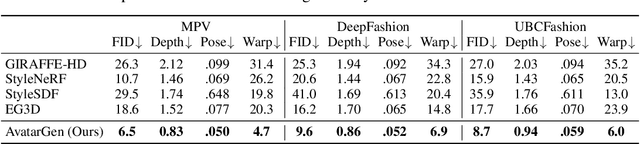
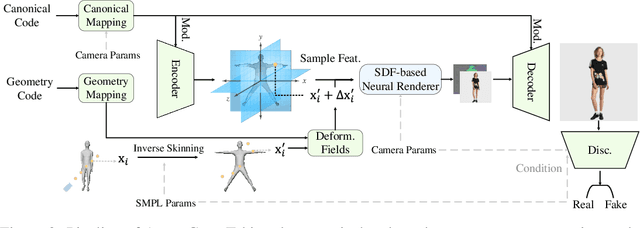
Unsupervised generation of 3D-aware clothed humans with various appearances and controllable geometries is important for creating virtual human avatars and other AR/VR applications. Existing methods are either limited to rigid object modeling, or not generative and thus unable to generate high-quality virtual humans and animate them. In this work, we propose AvatarGen, the first method that enables not only geometry-aware clothed human synthesis with high-fidelity appearances but also disentangled human animation controllability, while only requiring 2D images for training. Specifically, we decompose the generative 3D human synthesis into pose-guided mapping and canonical representation with predefined human pose and shape, such that the canonical representation can be explicitly driven to different poses and shapes with the guidance of a 3D parametric human model SMPL. AvatarGen further introduces a deformation network to learn non-rigid deformations for modeling fine-grained geometric details and pose-dependent dynamics. To improve the geometry quality of the generated human avatars, it leverages the signed distance field as geometric proxy, which allows more direct regularization from the 3D geometric priors of SMPL. Benefiting from these designs, our method can generate animatable 3D human avatars with high-quality appearance and geometry modeling, significantly outperforming previous 3D GANs. Furthermore, it is competent for many applications, e.g., single-view reconstruction, re-animation, and text-guided synthesis/editing. Code and pre-trained model will be available at http://jeff95.me/projects/avatargen.html.
Neuromorphic Visual Odometry System for Intelligent Vehicle Application with Bio-inspired Vision Sensor
Sep 05, 2019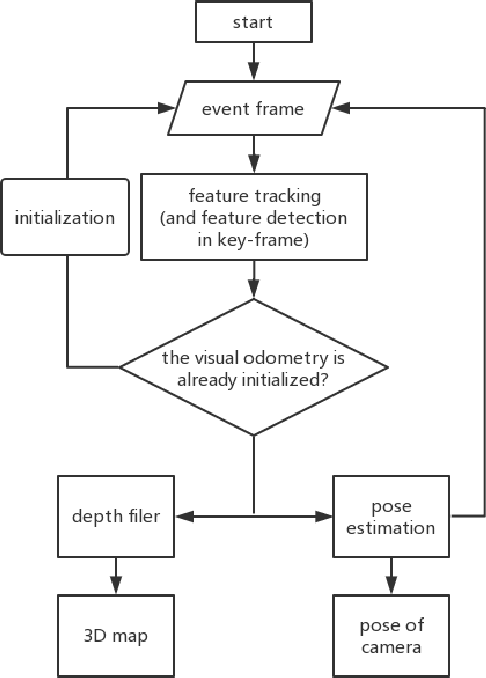

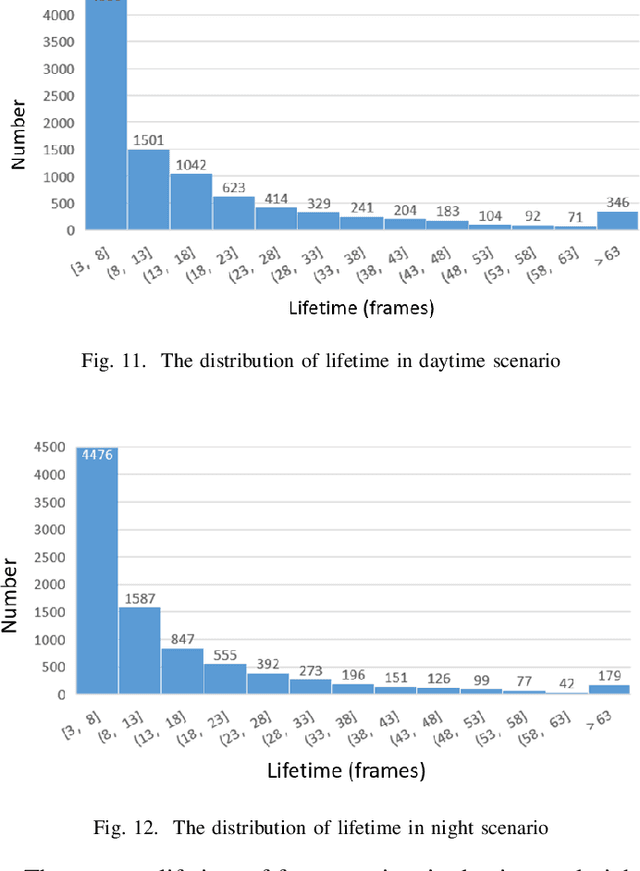
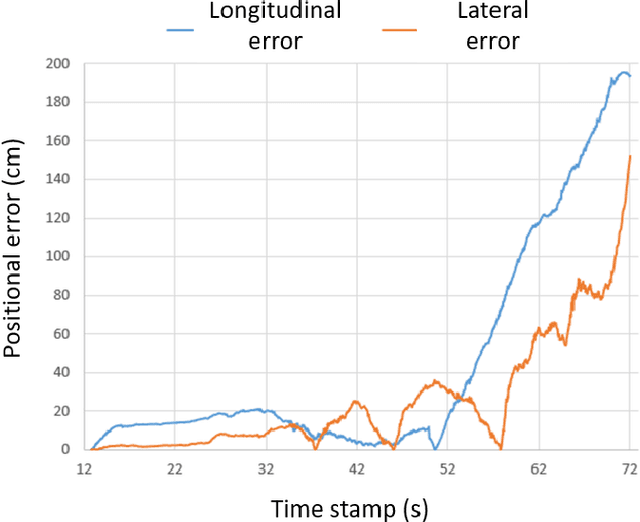
The neuromorphic camera is a brand new vision sensor that has emerged in recent years. In contrast to the conventional frame-based camera, the neuromorphic camera only transmits local pixel-level changes at the time of its occurrence and provides an asynchronous event stream with low latency. It has the advantages of extremely low signal delay, low transmission bandwidth requirements, rich information of edges, high dynamic range etc., which make it a promising sensor in the application of in-vehicle visual odometry system. This paper proposes a neuromorphic in-vehicle visual odometry system using feature tracking algorithm. To the best of our knowledge, this is the first in-vehicle visual odometry system that only uses a neuromorphic camera, and its performance test is carried out on actual driving datasets. In addition, an in-depth analysis of the results of the experiment is provided. The work of this paper verifies the feasibility of in-vehicle visual odometry system using neuromorphic cameras.