 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitDance: Scaling Autoregressive Generative Models with Binary Tokens
Feb 15, 2026We present BitDance, a scalable autoregressive (AR) image generator that predicts binary visual tokens instead of codebook indices. With high-entropy binary latents, BitDance lets each token represent up to $2^{256}$ states, yielding a compact yet highly expressive discrete representation. Sampling from such a huge token space is difficult with standard classification. To resolve this, BitDance uses a binary diffusion head: instead of predicting an index with softmax, it employs continuous-space diffusion to generate the binary tokens. Furthermore, we propose next-patch diffusion, a new decoding method that predicts multiple tokens in parallel with high accuracy, greatly speeding up inference. On ImageNet 256x256, BitDance achieves an FID of 1.24, the best among AR models. With next-patch diffusion, BitDance beats state-of-the-art parallel AR models that use 1.4B parameters, while using 5.4x fewer parameters (260M) and achieving 8.7x speedup. For text-to-image generation, BitDance trains on large-scale multimodal tokens and generates high-resolution, photorealistic images efficiently, showing strong performance and favorable scaling. When generating 1024x1024 images, BitDance achieves a speedup of over 30x compared to prior AR models. We release code and models to facilitate further research on AR foundation models. Code and models are available at: https://github.com/shallowdream204/BitDance.
UniWeTok: An Unified Binary Tokenizer with Codebook Size $\mathit{2^{128}}$ for Unified Multimodal Large Language Model
Feb 15, 2026Unified Multimodal Large Language Models (MLLMs) require a visual representation that simultaneously supports high-fidelity reconstruction, complex semantic extraction, and generative suitability. However, existing visual tokenizers typically struggle to satisfy these conflicting objectives within a single framework. In this paper, we introduce UniWeTok, a unified discrete tokenizer designed to bridge this gap using a massive binary codebook ($\mathit{2^{128}}$). For training framework, we introduce Pre-Post Distillation and a Generative-Aware Prior to enhance the semantic extraction and generative prior of the discrete tokens. In terms of model architecture, we propose a convolution-attention hybrid architecture with the SigLu activation function. SigLu activation not only bounds the encoder output and stabilizes the semantic distillation process but also effectively addresses the optimization conflict between token entropy loss and commitment loss. We further propose a three-stage training framework designed to enhance UniWeTok's adaptability cross various image resolutions and perception-sensitive scenarios, such as those involving human faces and textual content. On ImageNet, UniWeTok achieves state-of-the-art image generation performance (FID: UniWeTok 1.38 vs. REPA 1.42) while requiring a remarkably low training compute (Training Tokens: UniWeTok 33B vs. REPA 262B). On general-domain, UniWeTok demonstrates highly competitive capabilities across a broad range of tasks, including multimodal understanding, image generation (DPG Score: UniWeTok 86.63 vs. FLUX.1 [Dev] 83.84), and editing (GEdit Overall Score: UniWeTok 5.09 vs. OmniGen 5.06). We release code and models to facilitate community exploration of unified tokenizer and MLLM.
Mitty: Diffusion-based Human-to-Robot Video Generation
Dec 19, 2025Learning directly from human demonstration videos is a key milestone toward scalable and generalizable robot learning. Yet existing methods rely on intermediate representations such as keypoints or trajectories, introducing information loss and cumulative errors that harm temporal and visual consistency. We present Mitty, a Diffusion Transformer that enables video In-Context Learning for end-to-end Human2Robot video generation. Built on a pretrained video diffusion model, Mitty leverages strong visual-temporal priors to translate human demonstrations into robot-execution videos without action labels or intermediate abstractions. Demonstration videos are compressed into condition tokens and fused with robot denoising tokens through bidirectional attention during diffusion. To mitigate paired-data scarcity, we also develop an automatic synthesis pipeline that produces high-quality human-robot pairs from large egocentric datasets. Experiments on Human2Robot and EPIC-Kitchens show that Mitty delivers state-of-the-art results, strong generalization to unseen environments, and new insights for scalable robot learning from human observations.
UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning
May 29, 2025Unified multimodal large language models such as Show-o and Janus have achieved strong performance across both generation and understanding tasks. However, these models typically rely on large-scale datasets and require substantial computation during the pretraining stage. In addition, several post-training methods have been proposed, but they often depend on external data or are limited to task-specific customization. In this work, we introduce UniRL, a self-improving post-training approach. Our approach enables the model to generate images from prompts and use them as training data in each iteration, without relying on any external image data. Moreover, it enables the two tasks to enhance each other: the generated images are used for understanding, and the understanding results are used to supervise generation. We explore supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) to optimize the models. UniRL offers three key advantages: (1) it requires no external image data, as all training samples are generated by the model itself during training; (2) it not only improves individual task performance, but also reduces the imbalance between generation and understanding; and (3) it requires only several additional training steps during the post-training stage. We evaluate UniRL on top of Show-o and Janus, achieving a GenEval score of 0.77 for Show-o and 0.65 for Janus. Code and models will be released in https://github.com/showlab/UniRL.
Long-Context Autoregressive Video Modeling with Next-Frame Prediction
Mar 25, 2025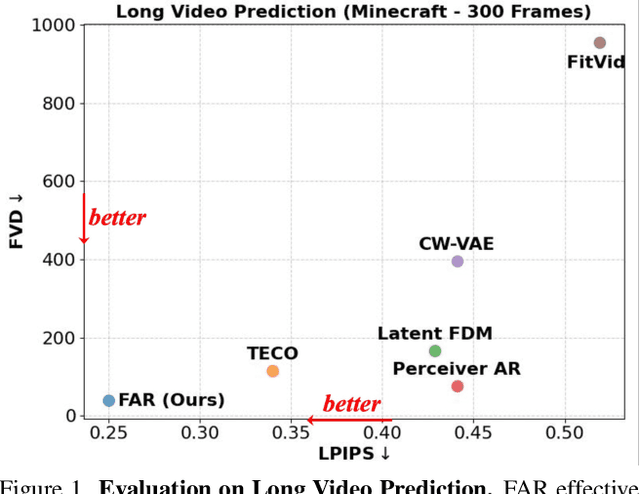
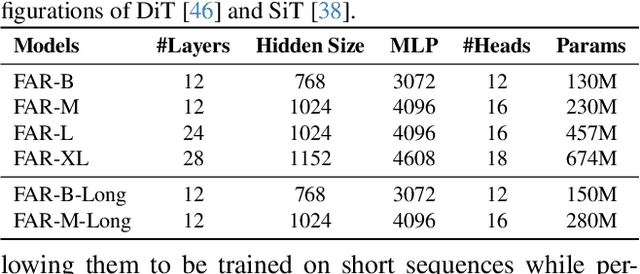
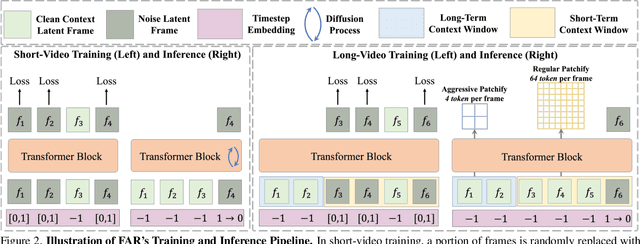
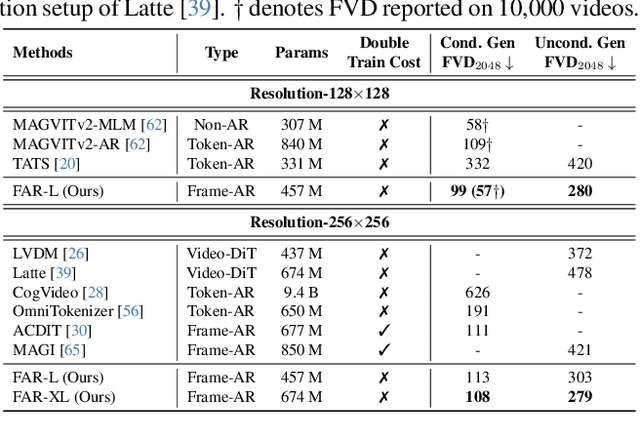
Long-context autoregressive modeling has significantly advanced language generation, but video generation still struggles to fully utilize extended temporal contexts. To investigate long-context video modeling, we introduce Frame AutoRegressive (FAR), a strong baseline for video autoregressive modeling. Just as language models learn causal dependencies between tokens (i.e., Token AR), FAR models temporal causal dependencies between continuous frames, achieving better convergence than Token AR and video diffusion transformers. Building on FAR, we observe that long-context vision modeling faces challenges due to visual redundancy. Existing RoPE lacks effective temporal decay for remote context and fails to extrapolate well to long video sequences. Additionally, training on long videos is computationally expensive, as vision tokens grow much faster than language tokens. To tackle these issues, we propose balancing locality and long-range dependency. We introduce FlexRoPE, an test-time technique that adds flexible temporal decay to RoPE, enabling extrapolation to 16x longer vision contexts. Furthermore, we propose long short-term context modeling, where a high-resolution short-term context window ensures fine-grained temporal consistency, while an unlimited long-term context window encodes long-range information using fewer tokens. With this approach, we can train on long video sequences with a manageable token context length. We demonstrate that FAR achieves state-of-the-art performance in both short- and long-video generation, providing a simple yet effective baseline for video autoregressive modeling.
DoraCycle: Domain-Oriented Adaptation of Unified Generative Model in Multimodal Cycles
Mar 05, 2025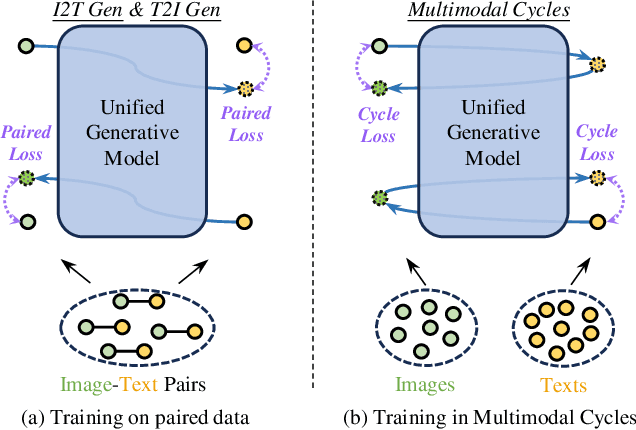
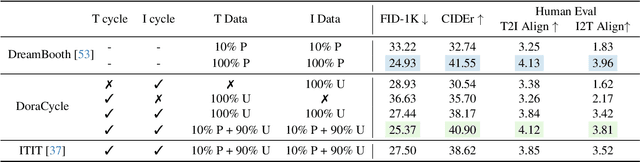
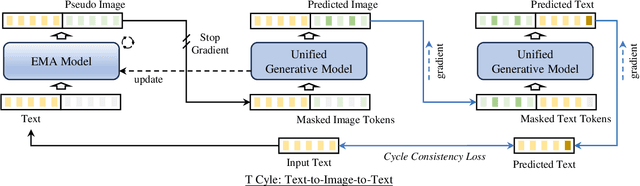

Adapting generative models to specific domains presents an effective solution for satisfying specialized requirements. However, adapting to some complex domains remains challenging, especially when these domains require substantial paired data to capture the targeted distributions. Since unpaired data from a single modality, such as vision or language, is more readily available, we utilize the bidirectional mappings between vision and language learned by the unified generative model to enable training on unpaired data for domain adaptation. Specifically, we propose DoraCycle, which integrates two multimodal cycles: text-to-image-to-text and image-to-text-to-image. The model is optimized through cross-entropy loss computed at the cycle endpoints, where both endpoints share the same modality. This facilitates self-evolution of the model without reliance on annotated text-image pairs. Experimental results demonstrate that for tasks independent of paired knowledge, such as stylization, DoraCycle can effectively adapt the unified model using only unpaired data. For tasks involving new paired knowledge, such as specific identities, a combination of a small set of paired image-text examples and larger-scale unpaired data is sufficient for effective domain-oriented adaptation. The code will be released at https://github.com/showlab/DoraCycle.
UniMoD: Efficient Unified Multimodal Transformers with Mixture-of-Depths
Feb 10, 2025



Unified multimodal transformers, which handle both generation and understanding tasks within a shared parameter space, have received increasing attention in recent research. Although various unified transformers have been proposed, training these models is costly due to redundant tokens and heavy attention computation. In the past, studies on large language models have demonstrated that token pruning methods, such as Mixture of Depths (MoD), can significantly improve computational efficiency. MoD employs a router to select the most important ones for processing within a transformer layer. However, directly applying MoD-based token pruning to unified transformers will result in suboptimal performance because different tasks exhibit varying levels of token redundancy. In our work, we analyze the unified transformers by (1) examining attention weight patterns, (2) evaluating the layer importance and token redundancy, and (3) analyzing task interactions. Our findings reveal that token redundancy is primarily influenced by different tasks and layers. Building on these findings, we introduce UniMoD, a task-aware token pruning method that employs a separate router for each task to determine which tokens should be pruned. We apply our method to Show-o and Emu3, reducing training FLOPs by approximately 15% in Show-o and 40% in Emu3, while maintaining or improving performance on several benchmarks. Code will be released at https://github.com/showlab/UniMoD.
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Aug 22, 2024



We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
ShowRoom3D: Text to High-Quality 3D Room Generation Using 3D Priors
Dec 20, 2023We introduce ShowRoom3D, a three-stage approach for generating high-quality 3D room-scale scenes from texts. Previous methods using 2D diffusion priors to optimize neural radiance fields for generating room-scale scenes have shown unsatisfactory quality. This is primarily attributed to the limitations of 2D priors lacking 3D awareness and constraints in the training methodology. In this paper, we utilize a 3D diffusion prior, MVDiffusion, to optimize the 3D room-scale scene. Our contributions are in two aspects. Firstly, we propose a progressive view selection process to optimize NeRF. This involves dividing the training process into three stages, gradually expanding the camera sampling scope. Secondly, we propose the pose transformation method in the second stage. It will ensure MVDiffusion provide the accurate view guidance. As a result, ShowRoom3D enables the generation of rooms with improved structural integrity, enhanced clarity from any view, reduced content repetition, and higher consistency across different perspectives. Extensive experiments demonstrate that our method, significantly outperforms state-of-the-art approaches by a large margin in terms of user study.
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
Oct 16, 2023
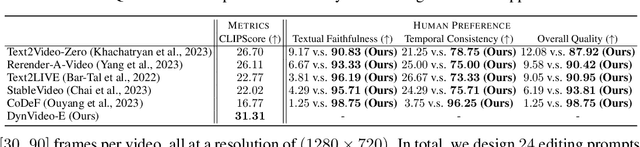
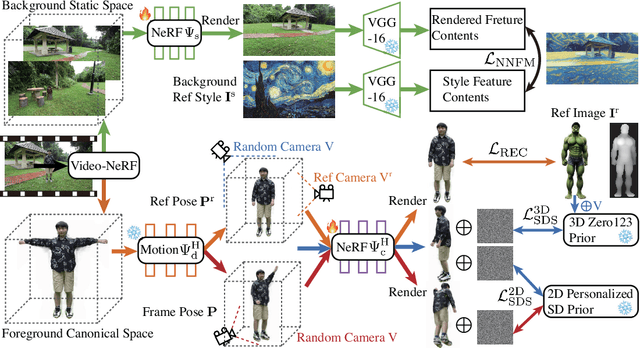

Despite remarkable research advances in diffusion-based video editing, existing methods are limited to short-length videos due to the contradiction between long-range consistency and frame-wise editing. Recent approaches attempt to tackle this challenge by introducing video-2D representations to degrade video editing to image editing. However, they encounter significant difficulties in handling large-scale motion- and view-change videos especially for human-centric videos. This motivates us to introduce the dynamic Neural Radiance Fields (NeRF) as the human-centric video representation to ease the video editing problem to a 3D space editing task. As such, editing can be performed in the 3D spaces and propagated to the entire video via the deformation field. To provide finer and direct controllable editing, we propose the image-based 3D space editing pipeline with a set of effective designs. These include multi-view multi-pose Score Distillation Sampling (SDS) from both 2D personalized diffusion priors and 3D diffusion priors, reconstruction losses on the reference image, text-guided local parts super-resolution, and style transfer for 3D background space. Extensive experiments demonstrate that our method, dubbed as DynVideo-E, significantly outperforms SOTA approaches on two challenging datasets by a large margin of 50% ~ 95% in terms of human preference. Compelling video comparisons are provided in the project page https://showlab.github.io/DynVideo-E/. Our code and data will be released to the community.