 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model
Dec 06, 2023



We introduce X-Adapter, a universal upgrader to enable the pretrained plug-and-play modules (e.g., ControlNet, LoRA) to work directly with the upgraded text-to-image diffusion model (e.g., SDXL) without further retraining. We achieve this goal by training an additional network to control the frozen upgraded model with the new text-image data pairs. In detail, X-Adapter keeps a frozen copy of the old model to preserve the connectors of different plugins. Additionally, X-Adapter adds trainable mapping layers that bridge the decoders from models of different versions for feature remapping. The remapped features will be used as guidance for the upgraded model. To enhance the guidance ability of X-Adapter, we employ a null-text training strategy for the upgraded model. After training, we also introduce a two-stage denoising strategy to align the initial latents of X-Adapter and the upgraded model. Thanks to our strategies, X-Adapter demonstrates universal compatibility with various plugins and also enables plugins of different versions to work together, thereby expanding the functionalities of diffusion community. To verify the effectiveness of the proposed method, we conduct extensive experiments and the results show that X-Adapter may facilitate wider application in the upgraded foundational diffusion model.
Instant3D: Instant Text-to-3D Generation
Nov 14, 2023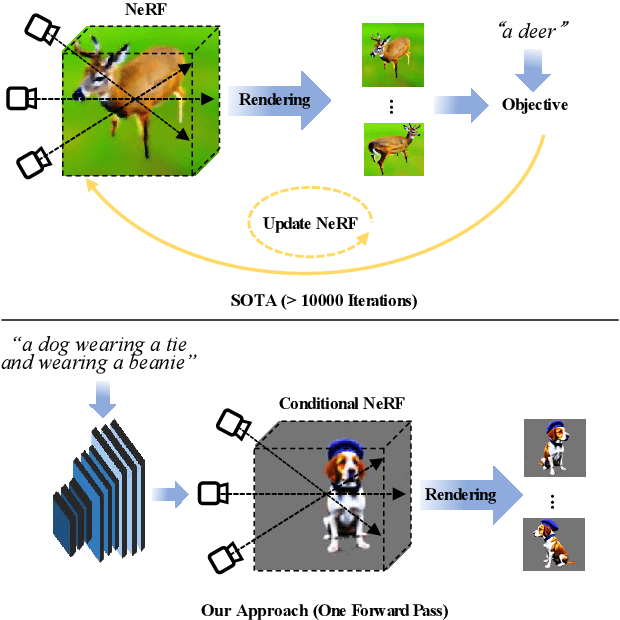

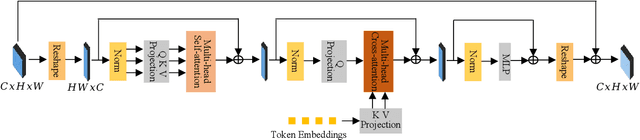
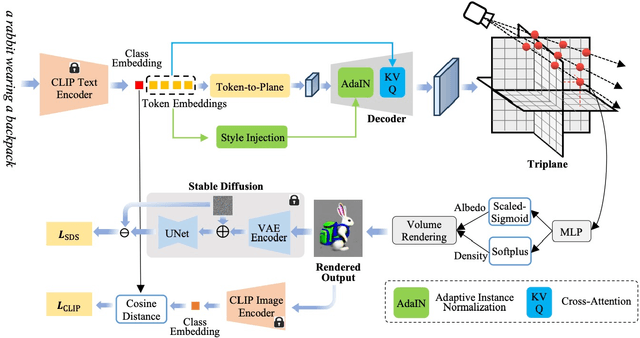
Text-to-3D generation, which aims to synthesize vivid 3D objects from text prompts, has attracted much attention from the computer vision community. While several existing works have achieved impressive results for this task, they mainly rely on a time-consuming optimization paradigm. Specifically, these methods optimize a neural field from scratch for each text prompt, taking approximately one hour or more to generate one object. This heavy and repetitive training cost impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network. Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect. Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively, while achieving significantly better efficiency. The project page is at https://ming1993li.github.io/Instant3DProj.
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
Oct 16, 2023
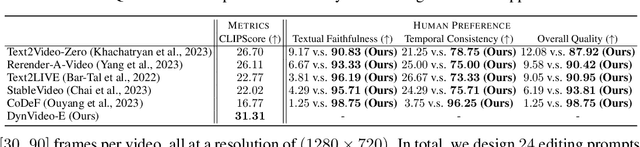
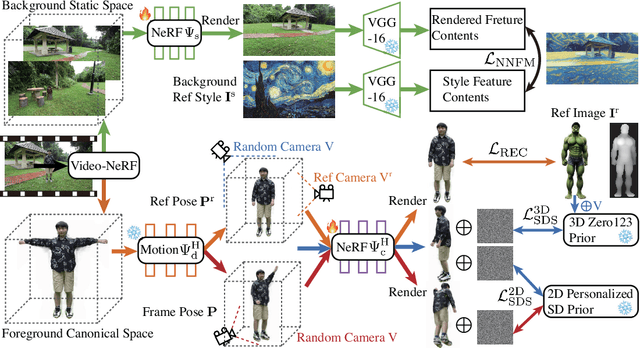

Despite remarkable research advances in diffusion-based video editing, existing methods are limited to short-length videos due to the contradiction between long-range consistency and frame-wise editing. Recent approaches attempt to tackle this challenge by introducing video-2D representations to degrade video editing to image editing. However, they encounter significant difficulties in handling large-scale motion- and view-change videos especially for human-centric videos. This motivates us to introduce the dynamic Neural Radiance Fields (NeRF) as the human-centric video representation to ease the video editing problem to a 3D space editing task. As such, editing can be performed in the 3D spaces and propagated to the entire video via the deformation field. To provide finer and direct controllable editing, we propose the image-based 3D space editing pipeline with a set of effective designs. These include multi-view multi-pose Score Distillation Sampling (SDS) from both 2D personalized diffusion priors and 3D diffusion priors, reconstruction losses on the reference image, text-guided local parts super-resolution, and style transfer for 3D background space. Extensive experiments demonstrate that our method, dubbed as DynVideo-E, significantly outperforms SOTA approaches on two challenging datasets by a large margin of 50% ~ 95% in terms of human preference. Compelling video comparisons are provided in the project page https://showlab.github.io/DynVideo-E/. Our code and data will be released to the community.
MotionDirector: Motion Customization of Text-to-Video Diffusion Models
Oct 12, 2023



Large-scale pre-trained diffusion models have exhibited remarkable capabilities in diverse video generations. Given a set of video clips of the same motion concept, the task of Motion Customization is to adapt existing text-to-video diffusion models to generate videos with this motion. For example, generating a video with a car moving in a prescribed manner under specific camera movements to make a movie, or a video illustrating how a bear would lift weights to inspire creators. Adaptation methods have been developed for customizing appearance like subject or style, yet unexplored for motion. It is straightforward to extend mainstream adaption methods for motion customization, including full model tuning, parameter-efficient tuning of additional layers, and Low-Rank Adaptions (LoRAs). However, the motion concept learned by these methods is often coupled with the limited appearances in the training videos, making it difficult to generalize the customized motion to other appearances. To overcome this challenge, we propose MotionDirector, with a dual-path LoRAs architecture to decouple the learning of appearance and motion. Further, we design a novel appearance-debiased temporal loss to mitigate the influence of appearance on the temporal training objective. Experimental results show the proposed method can generate videos of diverse appearances for the customized motions. Our method also supports various downstream applications, such as the mixing of different videos with their appearance and motion respectively, and animating a single image with customized motions. Our code and model weights will be released.
HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video
Apr 24, 2023We introduce HOSNeRF, a novel 360{\deg} free-viewpoint rendering method that reconstructs neural radiance fields for dynamic human-object-scene from a single monocular in-the-wild video. Our method enables pausing the video at any frame and rendering all scene details (dynamic humans, objects, and backgrounds) from arbitrary viewpoints. The first challenge in this task is the complex object motions in human-object interactions, which we tackle by introducing the new object bones into the conventional human skeleton hierarchy to effectively estimate large object deformations in our dynamic human-object model. The second challenge is that humans interact with different objects at different times, for which we introduce two new learnable object state embeddings that can be used as conditions for learning our human-object representation and scene representation, respectively. Extensive experiments show that HOSNeRF significantly outperforms SOTA approaches on two challenging datasets by a large margin of 40% ~ 50% in terms of LPIPS. The code, data, and compelling examples of 360{\deg} free-viewpoint renderings from single videos will be released in https://showlab.github.io/HOSNeRF.
STPrivacy: Spatio-Temporal Tubelet Sparsification and Anonymization for Privacy-preserving Action Recognition
Jan 08, 2023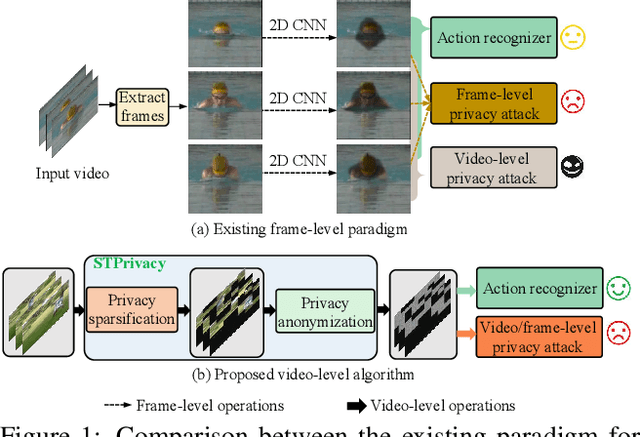
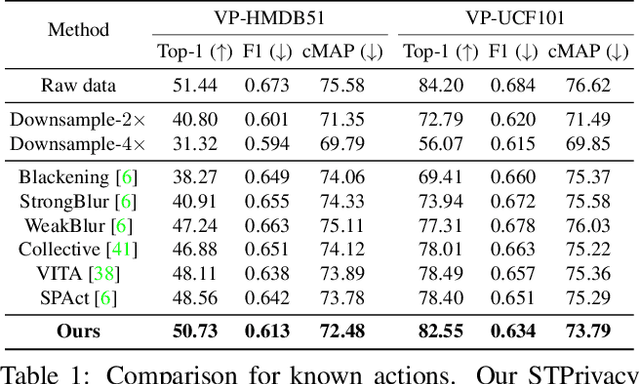
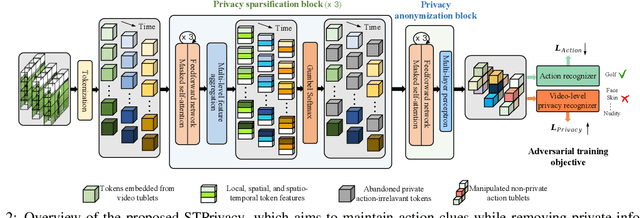
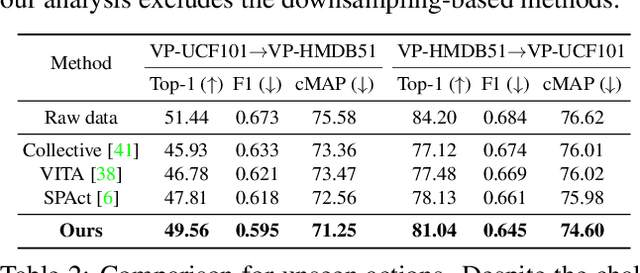
Recently privacy-preserving action recognition (PPAR) has been becoming an appealing video understanding problem. Nevertheless, existing works focus on the frame-level (spatial) privacy preservation, ignoring the privacy leakage from a whole video and destroying the temporal continuity of actions. In this paper, we present a novel PPAR paradigm, i.e., performing privacy preservation from both spatial and temporal perspectives, and propose a STPrivacy framework. For the first time, our STPrivacy applies vision Transformers to PPAR and regards a video as a sequence of spatio-temporal tubelets, showing outstanding advantages over previous convolutional methods. Specifically, our STPrivacy adaptively treats privacy-containing tubelets in two different manners. The tubelets irrelevant to actions are directly abandoned, i.e., sparsification, and not published for subsequent tasks. In contrast, those highly involved in actions are anonymized, i.e., anonymization, to remove private information. These two transformation mechanisms are complementary and simultaneously optimized in our unified framework. Because there is no large-scale benchmarks, we annotate five privacy attributes for two of the most popular action recognition datasets, i.e., HMDB51 and UCF101, and conduct extensive experiments on them. Moreover, to verify the generalization ability of our STPrivacy, we further introduce a privacy-preserving facial expression recognition task and conduct experiments on a large-scale video facial attributes dataset, i.e., Celeb-VHQ. The thorough comparisons and visualization analysis demonstrate our significant superiority over existing works. The appendix contains more details and visualizations.
DeVRF: Fast Deformable Voxel Radiance Fields for Dynamic Scenes
Jun 04, 2022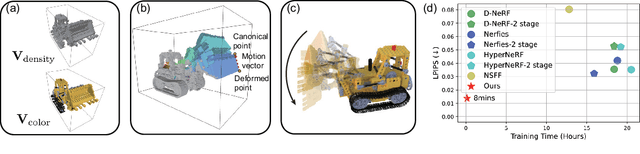
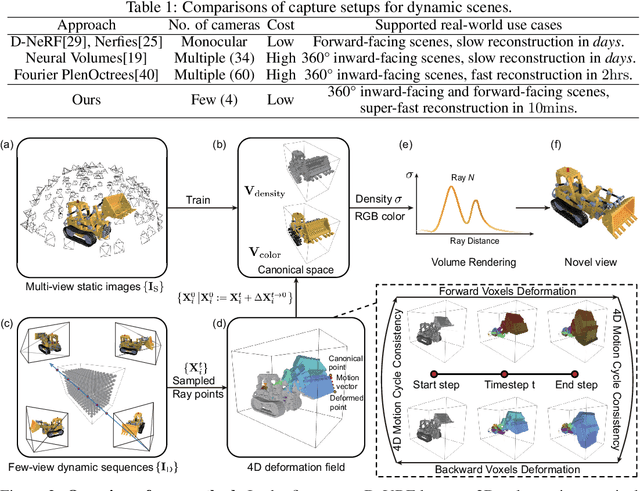
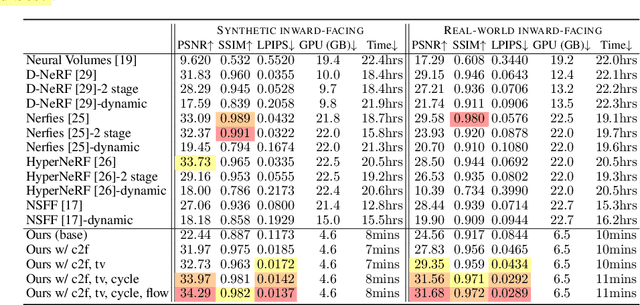

Modeling dynamic scenes is important for many applications such as virtual reality and telepresence. Despite achieving unprecedented fidelity for novel view synthesis in dynamic scenes, existing methods based on Neural Radiance Fields (NeRF) suffer from slow convergence (i.e., model training time measured in days). In this paper, we present DeVRF, a novel representation to accelerate learning dynamic radiance fields. The core of DeVRF is to model both the 3D canonical space and 4D deformation field of a dynamic, non-rigid scene with explicit and discrete voxel-based representations. However, it is quite challenging to train such a representation which has a large number of model parameters, often resulting in overfitting issues. To overcome this challenge, we devise a novel static-to-dynamic learning paradigm together with a new data capture setup that is convenient to deploy in practice. This paradigm unlocks efficient learning of deformable radiance fields via utilizing the 3D volumetric canonical space learnt from multi-view static images to ease the learning of 4D voxel deformation field with only few-view dynamic sequences. To further improve the efficiency of our DeVRF and its synthesized novel view's quality, we conduct thorough explorations and identify a set of strategies. We evaluate DeVRF on both synthetic and real-world dynamic scenes with different types of deformation. Experiments demonstrate that DeVRF achieves two orders of magnitude speedup (100x faster) with on-par high-fidelity results compared to the previous state-of-the-art approaches. The code and dataset will be released in https://github.com/showlab/DeVRF.