 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTPrivacy: Spatio-Temporal Tubelet Sparsification and Anonymization for Privacy-preserving Action Recognition
Paper and Code
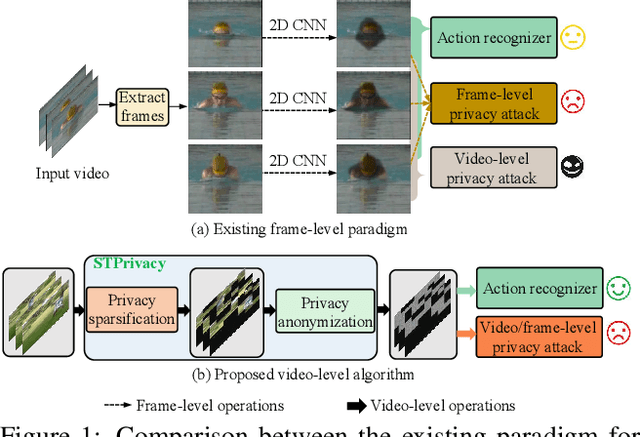
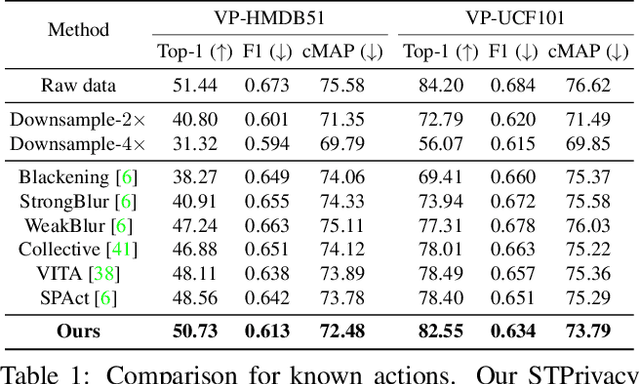
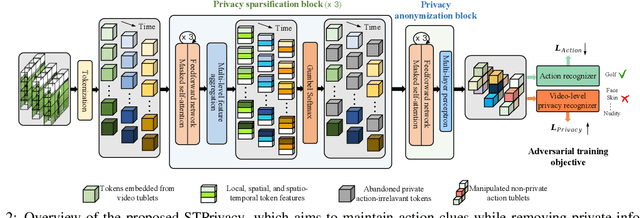
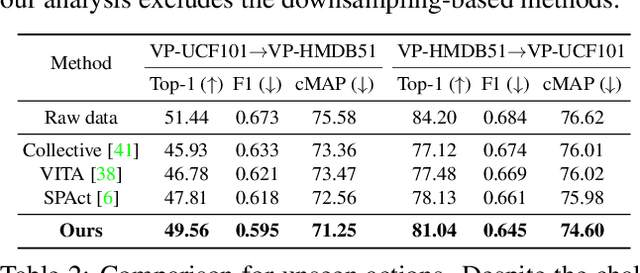
Recently privacy-preserving action recognition (PPAR) has been becoming an appealing video understanding problem. Nevertheless, existing works focus on the frame-level (spatial) privacy preservation, ignoring the privacy leakage from a whole video and destroying the temporal continuity of actions. In this paper, we present a novel PPAR paradigm, i.e., performing privacy preservation from both spatial and temporal perspectives, and propose a STPrivacy framework. For the first time, our STPrivacy applies vision Transformers to PPAR and regards a video as a sequence of spatio-temporal tubelets, showing outstanding advantages over previous convolutional methods. Specifically, our STPrivacy adaptively treats privacy-containing tubelets in two different manners. The tubelets irrelevant to actions are directly abandoned, i.e., sparsification, and not published for subsequent tasks. In contrast, those highly involved in actions are anonymized, i.e., anonymization, to remove private information. These two transformation mechanisms are complementary and simultaneously optimized in our unified framework. Because there is no large-scale benchmarks, we annotate five privacy attributes for two of the most popular action recognition datasets, i.e., HMDB51 and UCF101, and conduct extensive experiments on them. Moreover, to verify the generalization ability of our STPrivacy, we further introduce a privacy-preserving facial expression recognition task and conduct experiments on a large-scale video facial attributes dataset, i.e., Celeb-VHQ. The thorough comparisons and visualization analysis demonstrate our significant superiority over existing works. The appendix contains more details and visualizations.