 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyMotion: Structured 3D Motion Reward for Physics-Grounded Human Video Generation
May 14, 2026Generating realistic human motion is a central yet unsolved challenge in video generation. While reinforcement learning (RL)-based post-training has driven recent gains in general video quality, extending it to human motion remains bottlenecked by a reward signal that cannot reliably score motion realism. Existing video rewards primarily rely on 2D perceptual signals, without explicitly modeling the 3D body state, contact, and dynamics underlying articulated human motion, and often assign high scores to videos with floating bodies or physically implausible movements. To address this, we propose PhyMotion, a structured, fine-grained motion reward that grounds recovered 3D human trajectories in a physics simulator and evaluates motion quality along multiple dimensions of physical feasibility. Concretely, we recover SMPL body meshes from generated videos, retarget them onto a humanoid in the MuJoCo physics simulator, and evaluate the resulting motion along three axes: kinematic plausibility, contact and balance consistency, and dynamic feasibility. Each component provides a continuous and interpretable signal tied to a specific aspect of motion quality, allowing the reward to capture which aspects of motion are physically correct or violated. Experiments show that PhyMotion achieves stronger correlation with human judgments than existing reward formulations. These gains carry over to RL-based post-training, where optimizing PhyMotion leads to larger and more consistent improvements than optimizing existing rewards, improving motion realism across both autoregressive and bidirectional video generators under both automatic metrics and blind human evaluation (+68 Elo gain). Ablations show that the three axes provide complementary supervision signals, while the reward preserves overall video generation quality with only modest training overhead.
Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
Mar 16, 2026Simulation-to-real transfer remains a central challenge in robotics, as mismatches between simulated and real-world dynamics often lead to failures. While reinforcement learning offers a principled mechanism for adaptation, existing sim-to-real finetuning methods struggle with exploration and long-horizon credit assignment in the low-data regimes typical of real-world robotics. We introduce Simulation Distillation (SimDist), a sim-to-real framework that distills structural priors from a simulator into a latent world model and enables rapid real-world adaptation via online planning and supervised dynamics finetuning. By transferring reward and value models directly from simulation, SimDist provides dense planning signals from raw perception without requiring value learning during deployment. As a result, real-world adaptation reduces to short-horizon system identification, avoiding long-horizon credit assignment and enabling fast, stable improvement. Across precise manipulation and quadruped locomotion tasks, SimDist substantially outperforms prior methods in data efficiency, stability, and final performance. Project website and code: https://sim-dist.github.io/
ELLIPSE: Evidential Learning for Robust Waypoints and Uncertainties
Mar 04, 2026Robust waypoint prediction is crucial for mobile robots operating in open-world, safety-critical settings. While Imitation Learning (IL) methods have demonstrated great success in practice, they are susceptible to distribution shifts: the policy can become dangerously overconfident in unfamiliar states. In this paper, we present \textit{ELLIPSE}, a method building on multivariate deep evidential regression to output waypoints and multivariate Student-t predictive distributions in a single forward pass. To reduce covariate-shift-induced overconfidence under viewpoint and pose perturbations near expert trajectories, we introduce a lightweight domain augmentation procedure that synthesizes plausible viewpoint/pose variations without collecting additional demonstrations. To improve uncertainty reliability under environment/domain shift (e.g., unseen staircases), we apply a post-hoc isotonic recalibration on probability integral transform (PIT) values so that prediction sets remain plausible during deployment. We ground the discussion and experiments in staircase waypoint prediction, where obtaining robust waypoint and uncertainty is pivotal. Extensive real world evaluations show that \textit{ELLIPSE} improves both task success rate and uncertainty coverage compared to baselines.
Delay-Aware Diffusion Policy: Bridging the Observation-Execution Gap in Dynamic Tasks
Dec 08, 2025
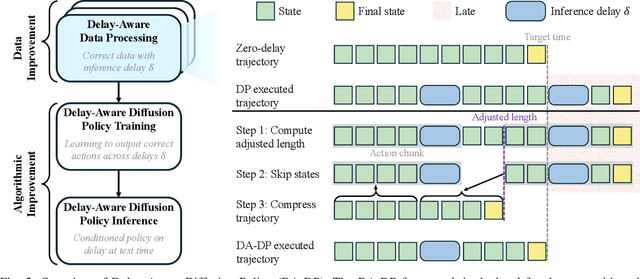


As a robot senses and selects actions, the world keeps changing. This inference delay creates a gap of tens to hundreds of milliseconds between the observed state and the state at execution. In this work, we take the natural generalization from zero delay to measured delay during training and inference. We introduce Delay-Aware Diffusion Policy (DA-DP), a framework for explicitly incorporating inference delays into policy learning. DA-DP corrects zero-delay trajectories to their delay-compensated counterparts, and augments the policy with delay conditioning. We empirically validate DA-DP on a variety of tasks, robots, and delays and find its success rate more robust to delay than delay-unaware methods. DA-DP is architecture agnostic and transfers beyond diffusion policies, offering a general pattern for delay-aware imitation learning. More broadly, DA-DP encourages evaluation protocols that report performance as a function of measured latency, not just task difficulty.
VENTURA: Adapting Image Diffusion Models for Unified Task Conditioned Navigation
Oct 01, 2025Robots must adapt to diverse human instructions and operate safely in unstructured, open-world environments. Recent Vision-Language models (VLMs) offer strong priors for grounding language and perception, but remain difficult to steer for navigation due to differences in action spaces and pretraining objectives that hamper transferability to robotics tasks. Towards addressing this, we introduce VENTURA, a vision-language navigation system that finetunes internet-pretrained image diffusion models for path planning. Instead of directly predicting low-level actions, VENTURA generates a path mask (i.e. a visual plan) in image space that captures fine-grained, context-aware navigation behaviors. A lightweight behavior-cloning policy grounds these visual plans into executable trajectories, yielding an interface that follows natural language instructions to generate diverse robot behaviors. To scale training, we supervise on path masks derived from self-supervised tracking models paired with VLM-augmented captions, avoiding manual pixel-level annotation or highly engineered data collection setups. In extensive real-world evaluations, VENTURA outperforms state-of-the-art foundation model baselines on object reaching, obstacle avoidance, and terrain preference tasks, improving success rates by 33% and reducing collisions by 54% across both seen and unseen scenarios. Notably, we find that VENTURA generalizes to unseen combinations of distinct tasks, revealing emergent compositional capabilities. Videos, code, and additional materials: https://venturapath.github.io
Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
May 19, 2025Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have sparked significant interest in developing GUI visual agents. We introduce MONDAY (Mobile OS Navigation Task Dataset for Agents from YouTube), a large-scale dataset of 313K annotated frames from 20K instructional videos capturing diverse real-world mobile OS navigation across multiple platforms. Models that include MONDAY in their pre-training phases demonstrate robust cross-platform generalization capabilities, consistently outperforming models trained on existing single OS datasets while achieving an average performance gain of 18.11%p on an unseen mobile OS platform. To enable continuous dataset expansion as mobile platforms evolve, we present an automated framework that leverages publicly available video content to create comprehensive task datasets without manual annotation. Our framework comprises robust OCR-based scene detection (95.04% F1score), near-perfect UI element detection (99.87% hit ratio), and novel multi-step action identification to extract reliable action sequences across diverse interface configurations. We contribute both the MONDAY dataset and our automated collection framework to facilitate future research in mobile OS navigation.
SayComply: Grounding Field Robotic Tasks in Operational Compliance through Retrieval-Based Language Models
Nov 18, 2024



This paper addresses the problem of task planning for robots that must comply with operational manuals in real-world settings. Task planning under these constraints is essential for enabling autonomous robot operation in domains that require adherence to domain-specific knowledge. Current methods for generating robot goals and plans rely on common sense knowledge encoded in large language models. However, these models lack grounding of robot plans to domain-specific knowledge and are not easily transferable between multiple sites or customers with different compliance needs. In this work, we present SayComply, which enables grounding robotic task planning with operational compliance using retrieval-based language models. We design a hierarchical database of operational, environment, and robot embodiment manuals and procedures to enable efficient retrieval of the relevant context under the limited context length of the LLMs. We then design a task planner using a tree-based retrieval augmented generation (RAG) technique to generate robot tasks that follow user instructions while simultaneously complying with the domain knowledge in the database. We demonstrate the benefits of our approach through simulations and hardware experiments in real-world scenarios that require precise context retrieval across various types of context, outperforming the standard RAG method. Our approach bridges the gap in deploying robots that consistently adhere to operational protocols, offering a scalable and edge-deployable solution for ensuring compliance across varied and complex real-world environments. Project website: saycomply.github.io.
Auto-Intent: Automated Intent Discovery and Self-Exploration for Large Language Model Web Agents
Oct 29, 2024



In this paper, we introduce Auto-Intent, a method to adapt a pre-trained large language model (LLM) as an agent for a target domain without direct fine-tuning, where we empirically focus on web navigation tasks. Our approach first discovers the underlying intents from target domain demonstrations unsupervisedly, in a highly compact form (up to three words). With the extracted intents, we train our intent predictor to predict the next intent given the agent's past observations and actions. In particular, we propose a self-exploration approach where top-k probable intent predictions are provided as a hint to the pre-trained LLM agent, which leads to enhanced decision-making capabilities. Auto-Intent substantially improves the performance of GPT-{3.5, 4} and Llama-3.1-{70B, 405B} agents on the large-scale real-website navigation benchmarks from Mind2Web and online navigation tasks from WebArena with its cross-benchmark generalization from Mind2Web.
AutoGuide: Automated Generation and Selection of State-Aware Guidelines for Large Language Model Agents
Mar 13, 2024



The primary limitation of large language models (LLMs) is their restricted understanding of the world. This poses significant difficulties for LLM-based agents, particularly in domains where pre-trained LLMs lack sufficient knowledge. In this paper, we introduce a novel framework, called AutoGuide, that bridges the knowledge gap in pre-trained LLMs by leveraging implicit knowledge in offline experiences. Specifically, AutoGuide effectively extracts knowledge embedded in offline data by extracting a set of state-aware guidelines. Importantly, each state-aware guideline is expressed in concise natural language and follows a conditional structure, clearly describing the state where it is applicable. As such, the resulting guidelines enable a principled way to provide helpful knowledge pertinent to an agent's current decision-making process. We show that our approach outperforms competitive LLM-based baselines by a large margin in sequential decision-making benchmarks.
TOD-Flow: Modeling the Structure of Task-Oriented Dialogues
Dec 07, 2023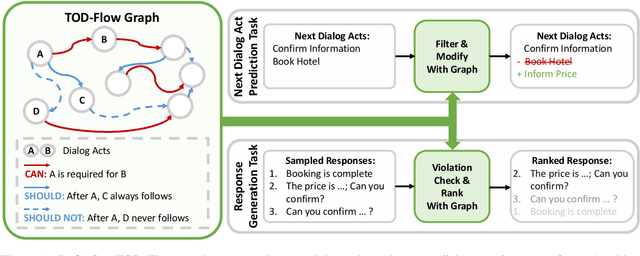
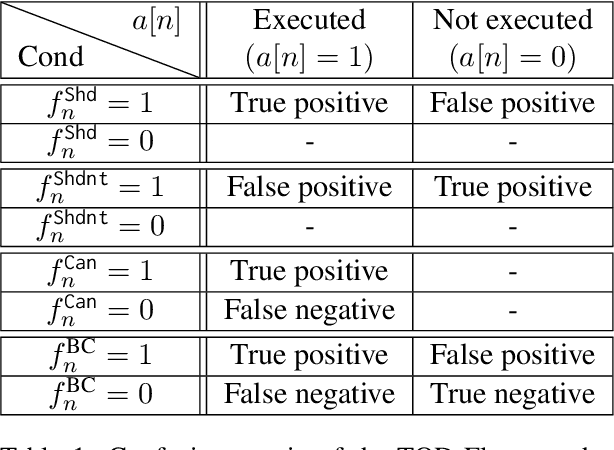
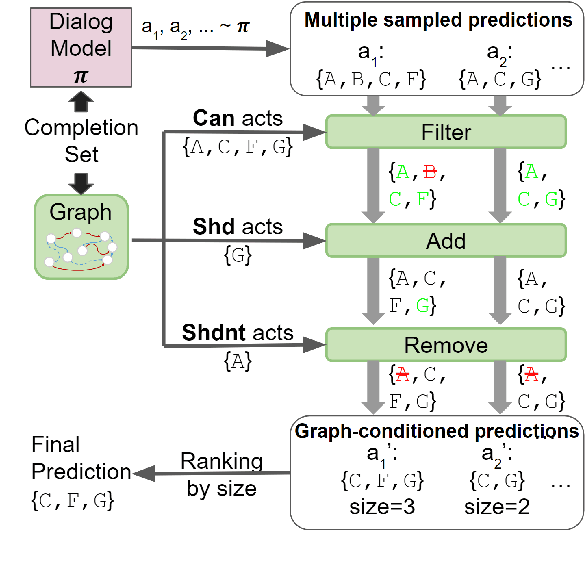

Task-Oriented Dialogue (TOD) systems have become crucial components in interactive artificial intelligence applications. While recent advances have capitalized on pre-trained language models (PLMs), they exhibit limitations regarding transparency and controllability. To address these challenges, we propose a novel approach focusing on inferring the TOD-Flow graph from dialogue data annotated with dialog acts, uncovering the underlying task structure in the form of a graph. The inferred TOD-Flow graph can be easily integrated with any dialogue model to improve its prediction performance, transparency, and controllability. Our TOD-Flow graph learns what a model can, should, and should not predict, effectively reducing the search space and providing a rationale for the model's prediction. We show that the proposed TOD-Flow graph better resembles human-annotated graphs compared to prior approaches. Furthermore, when combined with several dialogue policies and end-to-end dialogue models, we demonstrate that our approach significantly improves dialog act classification and end-to-end response generation performance in the MultiWOZ and SGD benchmarks. Code available at: https://github.com/srsohn/TOD-Flow