 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Meta-Reinforcement Learning via Automated Macro-Action Discovery
Dec 16, 2024



Meta-Reinforcement Learning (Meta-RL) enables fast adaptation to new testing tasks. Despite recent advancements, it is still challenging to learn performant policies across multiple complex and high-dimensional tasks. To address this, we propose a novel architecture with three hierarchical levels for 1) learning task representations, 2) discovering task-agnostic macro-actions in an automated manner, and 3) learning primitive actions. The macro-action can guide the low-level primitive policy learning to more efficiently transition to goal states. This can address the issue that the policy may forget previously learned behavior while learning new, conflicting tasks. Moreover, the task-agnostic nature of the macro-actions is enabled by removing task-specific components from the state space. Hence, this makes them amenable to re-composition across different tasks and leads to promising fast adaptation to new tasks. Also, the prospective instability from the tri-level hierarchies is effectively mitigated by our innovative, independently tailored training schemes. Experiments in the MetaWorld framework demonstrate the improved sample efficiency and success rate of our approach compared to previous state-of-the-art methods.
Sparsity-based Safety Conservatism for Constrained Offline Reinforcement Learning
Jul 17, 2024Reinforcement Learning (RL) has made notable success in decision-making fields like autonomous driving and robotic manipulation. Yet, its reliance on real-time feedback poses challenges in costly or hazardous settings. Furthermore, RL's training approach, centered on "on-policy" sampling, doesn't fully capitalize on data. Hence, Offline RL has emerged as a compelling alternative, particularly in conducting additional experiments is impractical, and abundant datasets are available. However, the challenge of distributional shift (extrapolation), indicating the disparity between data distributions and learning policies, also poses a risk in offline RL, potentially leading to significant safety breaches due to estimation errors (interpolation). This concern is particularly pronounced in safety-critical domains, where real-world problems are prevalent. To address both extrapolation and interpolation errors, numerous studies have introduced additional constraints to confine policy behavior, steering it towards more cautious decision-making. While many studies have addressed extrapolation errors, fewer have focused on providing effective solutions for tackling interpolation errors. For example, some works tackle this issue by incorporating potential cost-maximizing optimization by perturbing the original dataset. However, this, involving a bi-level optimization structure, may introduce significant instability or complicate problem-solving in high-dimensional tasks. This motivates us to pinpoint areas where hazards may be more prevalent than initially estimated based on the sparsity of available data by providing significant insight into constrained offline RL. In this paper, we present conservative metrics based on data sparsity that demonstrate the high generalizability to any methods and efficacy compared to using bi-level cost-ub-maximization.
Out-of-Distribution Adaptation in Offline RL: Counterfactual Reasoning via Causal Normalizing Flows
May 06, 2024



Despite notable successes of Reinforcement Learning (RL), the prevalent use of an online learning paradigm prevents its widespread adoption, especially in hazardous or costly scenarios. Offline RL has emerged as an alternative solution, learning from pre-collected static datasets. However, this offline learning introduces a new challenge known as distributional shift, degrading the performance when the policy is evaluated on scenarios that are Out-Of-Distribution (OOD) from the training dataset. Most existing offline RL resolves this issue by regularizing policy learning within the information supported by the given dataset. However, such regularization overlooks the potential for high-reward regions that may exist beyond the dataset. This motivates exploring novel offline learning techniques that can make improvements beyond the data support without compromising policy performance, potentially by learning causation (cause-and-effect) instead of correlation from the dataset. In this paper, we propose the MOOD-CRL (Model-based Offline OOD-Adapting Causal RL) algorithm, which aims to address the challenge of extrapolation for offline policy training through causal inference instead of policy-regularizing methods. Specifically, Causal Normalizing Flow (CNF) is developed to learn the transition and reward functions for data generation and augmentation in offline policy evaluation and training. Based on the data-invariant, physics-based qualitative causal graph and the observational data, we develop a novel learning scheme for CNF to learn the quantitative structural causal model. As a result, CNF gains predictive and counterfactual reasoning capabilities for sequential decision-making tasks, revealing a high potential for OOD adaptation. Our CNF-based offline RL approach is validated through empirical evaluations, outperforming model-free and model-based methods by a significant margin.
Towards an Adaptable and Generalizable Optimization Engine in Decision and Control: A Meta Reinforcement Learning Approach
Jan 04, 2024Sampling-based model predictive control (MPC) has found significant success in optimal control problems with non-smooth system dynamics and cost function. Many machine learning-based works proposed to improve MPC by a) learning or fine-tuning the dynamics/ cost function, or b) learning to optimize for the update of the MPC controllers. For the latter, imitation learning-based optimizers are trained to update the MPC controller by mimicking the expert demonstrations, which, however, are expensive or even unavailable. More significantly, many sequential decision-making problems are in non-stationary environments, requiring that an optimizer should be adaptable and generalizable to update the MPC controller for solving different tasks. To address those issues, we propose to learn an optimizer based on meta-reinforcement learning (RL) to update the controllers. This optimizer does not need expert demonstration and can enable fast adaptation (e.g., few-shots) when it is deployed in unseen control tasks. Experimental results validate the effectiveness of the learned optimizer regarding fast adaptation.
Constrained Meta-Reinforcement Learning for Adaptable Safety Guarantee with Differentiable Convex Programming
Dec 15, 2023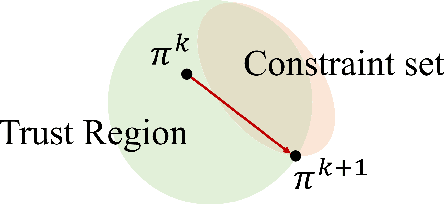

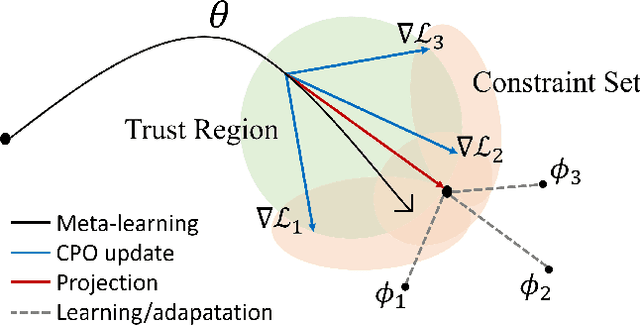
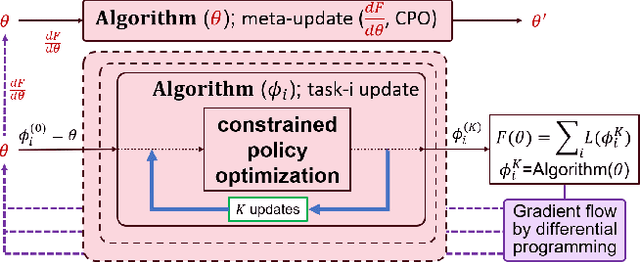
Despite remarkable achievements in artificial intelligence, the deployability of learning-enabled systems in high-stakes real-world environments still faces persistent challenges. For example, in safety-critical domains like autonomous driving, robotic manipulation, and healthcare, it is crucial not only to achieve high performance but also to comply with given constraints. Furthermore, adaptability becomes paramount in non-stationary domains, where environmental parameters are subject to change. While safety and adaptability are recognized as key qualities for the new generation of AI, current approaches have not demonstrated effective adaptable performance in constrained settings. Hence, this paper breaks new ground by studying the unique challenges of ensuring safety in non-stationary environments by solving constrained problems through the lens of the meta-learning approach (learning-to-learn). While unconstrained meta-learning al-ready encounters complexities in end-to-end differentiation of the loss due to the bi-level nature, its constrained counterpart introduces an additional layer of difficulty, since the constraints imposed on task-level updates complicate the differentiation process. To address the issue, we first employ successive convex-constrained policy updates across multiple tasks with differentiable convexprogramming, which allows meta-learning in constrained scenarios by enabling end-to-end differentiation. This approach empowers the agent to rapidly adapt to new tasks under non-stationarity while ensuring compliance with safety constraints.
Distributionally Safe Reinforcement Learning under Model Uncertainty: A Single-Level Approach by Differentiable Convex Programming
Oct 03, 2023



Safety assurance is uncompromisable for safety-critical environments with the presence of drastic model uncertainties (e.g., distributional shift), especially with humans in the loop. However, incorporating uncertainty in safe learning will naturally lead to a bi-level problem, where at the lower level the (worst-case) safety constraint is evaluated within the uncertainty ambiguity set. In this paper, we present a tractable distributionally safe reinforcement learning framework to enforce safety under a distributional shift measured by a Wasserstein metric. To improve the tractability, we first use duality theory to transform the lower-level optimization from infinite-dimensional probability space where distributional shift is measured, to a finite-dimensional parametric space. Moreover, by differentiable convex programming, the bi-level safe learning problem is further reduced to a single-level one with two sequential computationally efficient modules: a convex quadratic program to guarantee safety followed by a projected gradient ascent to simultaneously find the worst-case uncertainty. This end-to-end differentiable framework with safety constraints, to the best of our knowledge, is the first tractable single-level solution to address distributional safety. We test our approach on first and second-order systems with varying complexities and compare our results with the uncertainty-agnostic policies, where our approach demonstrates a significant improvement on safety guarantees.
Wasserstein Distributionally Robust Control Barrier Function using Conditional Value-at-Risk with Differentiable Convex Programming
Sep 15, 2023Control Barrier functions (CBFs) have attracted extensive attention for designing safe controllers for their deployment in real-world safety-critical systems. However, the perception of the surrounding environment is often subject to stochasticity and further distributional shift from the nominal one. In this paper, we present distributional robust CBF (DR-CBF) to achieve resilience under distributional shift while keeping the advantages of CBF, such as computational efficacy and forward invariance. To achieve this goal, we first propose a single-level convex reformulation to estimate the conditional value at risk (CVaR) of the safety constraints under distributional shift measured by a Wasserstein metric, which is by nature tri-level programming. Moreover, to construct a control barrier condition to enforce the forward invariance of the CVaR, the technique of differentiable convex programming is applied to enable differentiation through the optimization layer of CVaR estimation. We also provide an approximate variant of DR-CBF for higher-order systems. Simulation results are presented to validate the chance-constrained safety guarantee under the distributional shift in both first and second-order systems.
On the Optimality, Stability, and Feasibility of Control Barrier Functions: An Adaptive Learning-Based Approach
May 05, 2023Safety has been a critical issue for the deployment of learning-based approaches in real-world applications. To address this issue, control barrier function (CBF) and its variants have attracted extensive attention for safety-critical control. However, due to the myopic one-step nature of CBF and the lack of principled methods to design the class-$\mathcal{K}$ functions, there are still fundamental limitations of current CBFs: optimality, stability, and feasibility. In this paper, we proposed a novel and unified approach to address these limitations with Adaptive Multi-step Control Barrier Function (AM-CBF), where we parameterize the class-$\mathcal{K}$ function by a neural network and train it together with the reinforcement learning policy. Moreover, to mitigate the myopic nature, we propose a novel \textit{multi-step training and single-step execution} paradigm to make CBF farsighted while the execution remains solving a single-step convex quadratic program. Our method is evaluated on the first and second-order systems in various scenarios, where our approach outperforms the conventional CBF both qualitatively and quantitatively.
Influencing Long-Term Behavior in Multiagent Reinforcement Learning
Mar 07, 2022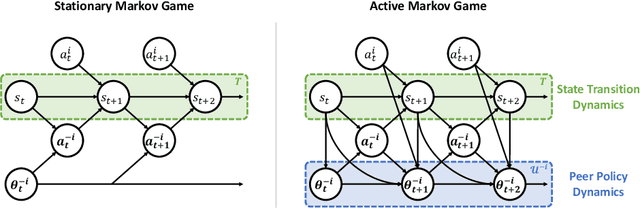
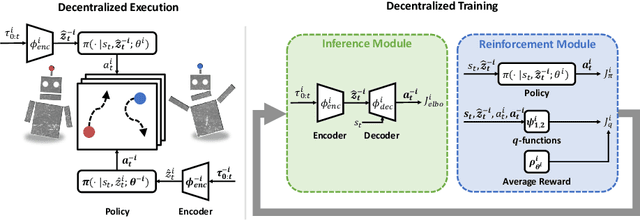
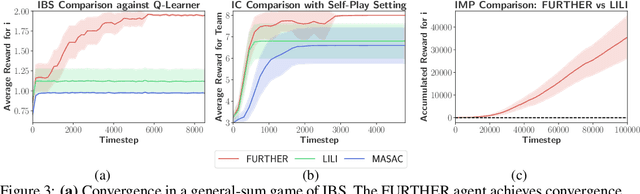
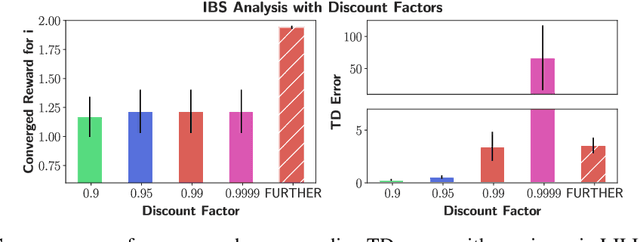
The main challenge of multiagent reinforcement learning is the difficulty of learning useful policies in the presence of other simultaneously learning agents whose changing behaviors jointly affect the environment's transition and reward dynamics. An effective approach that has recently emerged for addressing this non-stationarity is for each agent to anticipate the learning of other interacting agents and influence the evolution of their future policies towards desirable behavior for its own benefit. Unfortunately, all previous approaches for achieving this suffer from myopic evaluation, considering only a few or a finite number of updates to the policies of other agents. In this paper, we propose a principled framework for considering the limiting policies of other agents as the time approaches infinity. Specifically, we develop a new optimization objective that maximizes each agent's average reward by directly accounting for the impact of its behavior on the limiting set of policies that other agents will take on. Thanks to our farsighted evaluation, we demonstrate better long-term performance than state-of-the-art baselines in various domains, including the full spectrum of general-sum, competitive, and cooperative settings.
ROMAX: Certifiably Robust Deep Multiagent Reinforcement Learning via Convex Relaxation
Sep 14, 2021



In a multirobot system, a number of cyber-physical attacks (e.g., communication hijack, observation perturbations) can challenge the robustness of agents. This robustness issue worsens in multiagent reinforcement learning because there exists the non-stationarity of the environment caused by simultaneously learning agents whose changing policies affect the transition and reward functions. In this paper, we propose a minimax MARL approach to infer the worst-case policy update of other agents. As the minimax formulation is computationally intractable to solve, we apply the convex relaxation of neural networks to solve the inner minimization problem. Such convex relaxation enables robustness in interacting with peer agents that may have significantly different behaviors and also achieves a certified bound of the original optimization problem. We evaluate our approach on multiple mixed cooperative-competitive tasks and show that our method outperforms the previous state of the art approaches on this topic.