 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Reward Policy Optimization for Sparse-Reward Environments
Jan 29, 2026Exploration is essential in reinforcement learning as an agent relies on trial and error to learn an optimal policy. However, when rewards are sparse, naive exploration strategies, like noise injection, are often insufficient. Intrinsic rewards can also provide principled guidance for exploration by, for example, combining them with extrinsic rewards to optimize a policy or using them to train subpolicies for hierarchical learning. However, the former approach suffers from unstable credit assignment, while the latter exhibits sample inefficiency and sub-optimality. We propose a policy optimization framework that leverages multiple intrinsic rewards to directly optimize a policy for an extrinsic reward without pretraining subpolicies. Our algorithm -- intrinsic reward policy optimization (IRPO) -- achieves this by using a surrogate policy gradient that provides a more informative learning signal than the true gradient in sparse-reward environments. We demonstrate that IRPO improves performance and sample efficiency relative to baselines in discrete and continuous environments, and formally analyze the optimization problem solved by IRPO. Our code is available at https://github.com/Mgineer117/IRPO.
Hierarchical Meta-Reinforcement Learning via Automated Macro-Action Discovery
Dec 16, 2024



Meta-Reinforcement Learning (Meta-RL) enables fast adaptation to new testing tasks. Despite recent advancements, it is still challenging to learn performant policies across multiple complex and high-dimensional tasks. To address this, we propose a novel architecture with three hierarchical levels for 1) learning task representations, 2) discovering task-agnostic macro-actions in an automated manner, and 3) learning primitive actions. The macro-action can guide the low-level primitive policy learning to more efficiently transition to goal states. This can address the issue that the policy may forget previously learned behavior while learning new, conflicting tasks. Moreover, the task-agnostic nature of the macro-actions is enabled by removing task-specific components from the state space. Hence, this makes them amenable to re-composition across different tasks and leads to promising fast adaptation to new tasks. Also, the prospective instability from the tri-level hierarchies is effectively mitigated by our innovative, independently tailored training schemes. Experiments in the MetaWorld framework demonstrate the improved sample efficiency and success rate of our approach compared to previous state-of-the-art methods.
Sparsity-based Safety Conservatism for Constrained Offline Reinforcement Learning
Jul 17, 2024Reinforcement Learning (RL) has made notable success in decision-making fields like autonomous driving and robotic manipulation. Yet, its reliance on real-time feedback poses challenges in costly or hazardous settings. Furthermore, RL's training approach, centered on "on-policy" sampling, doesn't fully capitalize on data. Hence, Offline RL has emerged as a compelling alternative, particularly in conducting additional experiments is impractical, and abundant datasets are available. However, the challenge of distributional shift (extrapolation), indicating the disparity between data distributions and learning policies, also poses a risk in offline RL, potentially leading to significant safety breaches due to estimation errors (interpolation). This concern is particularly pronounced in safety-critical domains, where real-world problems are prevalent. To address both extrapolation and interpolation errors, numerous studies have introduced additional constraints to confine policy behavior, steering it towards more cautious decision-making. While many studies have addressed extrapolation errors, fewer have focused on providing effective solutions for tackling interpolation errors. For example, some works tackle this issue by incorporating potential cost-maximizing optimization by perturbing the original dataset. However, this, involving a bi-level optimization structure, may introduce significant instability or complicate problem-solving in high-dimensional tasks. This motivates us to pinpoint areas where hazards may be more prevalent than initially estimated based on the sparsity of available data by providing significant insight into constrained offline RL. In this paper, we present conservative metrics based on data sparsity that demonstrate the high generalizability to any methods and efficacy compared to using bi-level cost-ub-maximization.
Out-of-Distribution Adaptation in Offline RL: Counterfactual Reasoning via Causal Normalizing Flows
May 06, 2024



Despite notable successes of Reinforcement Learning (RL), the prevalent use of an online learning paradigm prevents its widespread adoption, especially in hazardous or costly scenarios. Offline RL has emerged as an alternative solution, learning from pre-collected static datasets. However, this offline learning introduces a new challenge known as distributional shift, degrading the performance when the policy is evaluated on scenarios that are Out-Of-Distribution (OOD) from the training dataset. Most existing offline RL resolves this issue by regularizing policy learning within the information supported by the given dataset. However, such regularization overlooks the potential for high-reward regions that may exist beyond the dataset. This motivates exploring novel offline learning techniques that can make improvements beyond the data support without compromising policy performance, potentially by learning causation (cause-and-effect) instead of correlation from the dataset. In this paper, we propose the MOOD-CRL (Model-based Offline OOD-Adapting Causal RL) algorithm, which aims to address the challenge of extrapolation for offline policy training through causal inference instead of policy-regularizing methods. Specifically, Causal Normalizing Flow (CNF) is developed to learn the transition and reward functions for data generation and augmentation in offline policy evaluation and training. Based on the data-invariant, physics-based qualitative causal graph and the observational data, we develop a novel learning scheme for CNF to learn the quantitative structural causal model. As a result, CNF gains predictive and counterfactual reasoning capabilities for sequential decision-making tasks, revealing a high potential for OOD adaptation. Our CNF-based offline RL approach is validated through empirical evaluations, outperforming model-free and model-based methods by a significant margin.
Constrained Meta-Reinforcement Learning for Adaptable Safety Guarantee with Differentiable Convex Programming
Dec 15, 2023

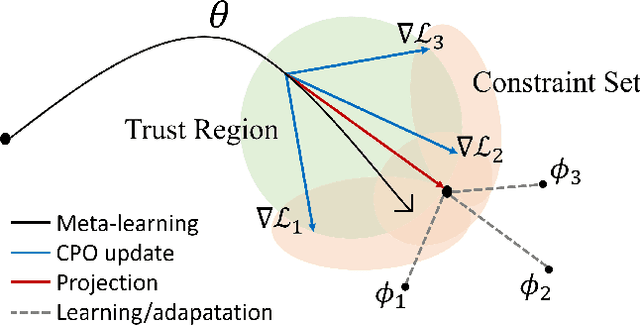
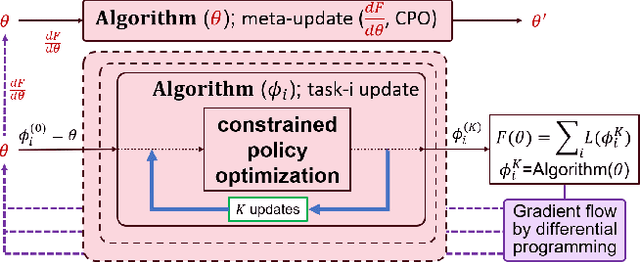
Despite remarkable achievements in artificial intelligence, the deployability of learning-enabled systems in high-stakes real-world environments still faces persistent challenges. For example, in safety-critical domains like autonomous driving, robotic manipulation, and healthcare, it is crucial not only to achieve high performance but also to comply with given constraints. Furthermore, adaptability becomes paramount in non-stationary domains, where environmental parameters are subject to change. While safety and adaptability are recognized as key qualities for the new generation of AI, current approaches have not demonstrated effective adaptable performance in constrained settings. Hence, this paper breaks new ground by studying the unique challenges of ensuring safety in non-stationary environments by solving constrained problems through the lens of the meta-learning approach (learning-to-learn). While unconstrained meta-learning al-ready encounters complexities in end-to-end differentiation of the loss due to the bi-level nature, its constrained counterpart introduces an additional layer of difficulty, since the constraints imposed on task-level updates complicate the differentiation process. To address the issue, we first employ successive convex-constrained policy updates across multiple tasks with differentiable convexprogramming, which allows meta-learning in constrained scenarios by enabling end-to-end differentiation. This approach empowers the agent to rapidly adapt to new tasks under non-stationarity while ensuring compliance with safety constraints.