 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Generic Hierarchical Human Motion Prior using VAEs
Paper and Code
Jun 07, 2021
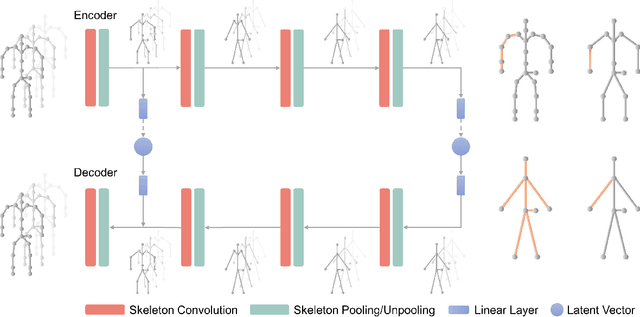

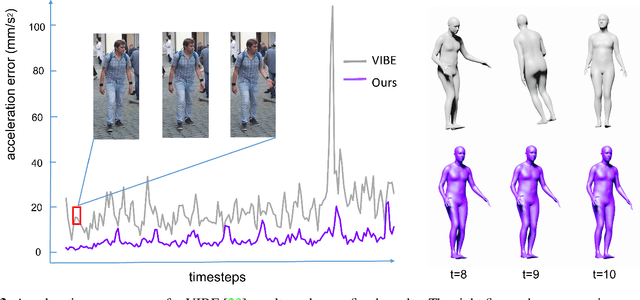
A deep generative model that describes human motions can benefit a wide range of fundamental computer vision and graphics tasks, such as providing robustness to video-based human pose estimation, predicting complete body movements for motion capture systems during occlusions, and assisting key frame animation with plausible movements. In this paper, we present a method for learning complex human motions independent of specific tasks using a combined global and local latent space to facilitate coarse and fine-grained modeling. Specifically, we propose a hierarchical motion variational autoencoder (HM-VAE) that consists of a 2-level hierarchical latent space. While the global latent space captures the overall global body motion, the local latent space enables to capture the refined poses of the different body parts. We demonstrate the effectiveness of our hierarchical motion variational autoencoder in a variety of tasks including video-based human pose estimation, motion completion from partial observations, and motion synthesis from sparse key-frames. Even though, our model has not been trained for any of these tasks specifically, it provides superior performance than task-specific alternatives. Our general-purpose human motion prior model can fix corrupted human body animations and generate complete movements from incomplete observations.