 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels, Pixels, and Rewards: Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning
Dec 08, 2020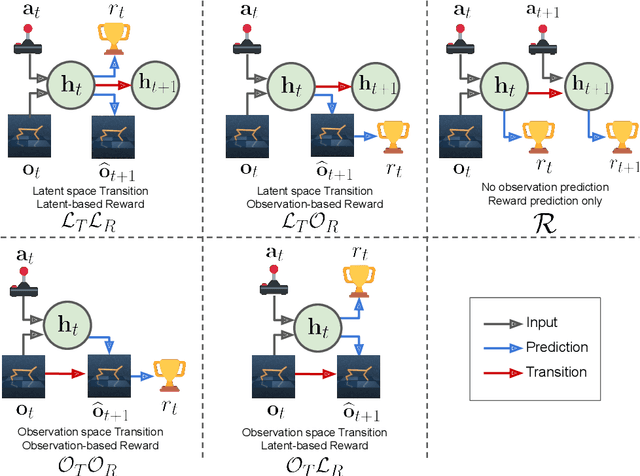

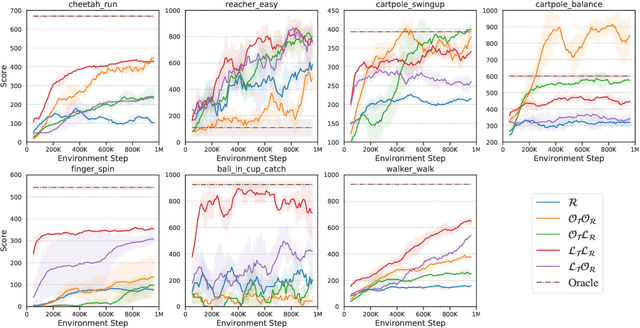
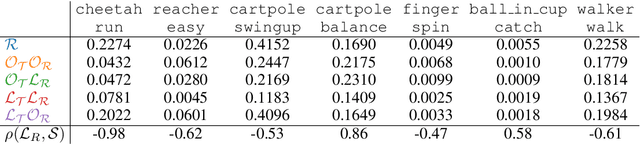
Model-based reinforcement learning (MBRL) methods have shown strong sample efficiency and performance across a variety of tasks, including when faced with high-dimensional visual observations. These methods learn to predict the environment dynamics and expected reward from interaction and use this predictive model to plan and perform the task. However, MBRL methods vary in their fundamental design choices, and there is no strong consensus in the literature on how these design decisions affect performance. In this paper, we study a number of design decisions for the predictive model in visual MBRL algorithms, focusing specifically on methods that use a predictive model for planning. We find that a range of design decisions that are often considered crucial, such as the use of latent spaces, have little effect on task performance. A big exception to this finding is that predicting future observations (i.e., images) leads to significant task performance improvement compared to only predicting rewards. We also empirically find that image prediction accuracy, somewhat surprisingly, correlates more strongly with downstream task performance than reward prediction accuracy. We show how this phenomenon is related to exploration and how some of the lower-scoring models on standard benchmarks (that require exploration) will perform the same as the best-performing models when trained on the same training data. Simultaneously, in the absence of exploration, models that fit the data better usually perform better on the downstream task as well, but surprisingly, these are often not the same models that perform the best when learning and exploring from scratch. These findings suggest that performance and exploration place important and potentially contradictory requirements on the model.
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks
Nov 05, 2019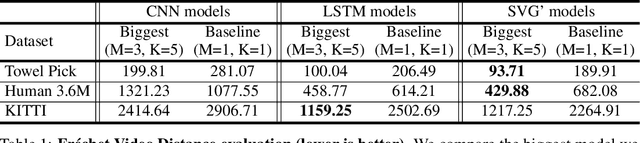
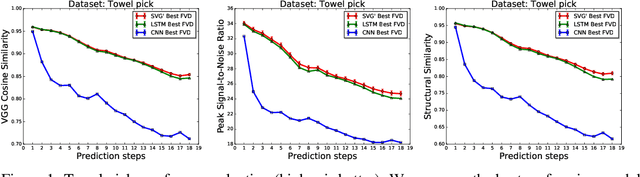
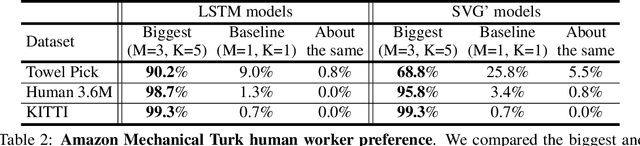

Predicting future video frames is extremely challenging, as there are many factors of variation that make up the dynamics of how frames change through time. Previously proposed solutions require complex inductive biases inside network architectures with highly specialized computation, including segmentation masks, optical flow, and foreground and background separation. In this work, we question if such handcrafted architectures are necessary and instead propose a different approach: finding minimal inductive bias for video prediction while maximizing network capacity. We investigate this question by performing the first large-scale empirical study and demonstrate state-of-the-art performance by learning large models on three different datasets: one for modeling object interactions, one for modeling human motion, and one for modeling car driving.
Adversarial Logit Pairing
Mar 16, 2018
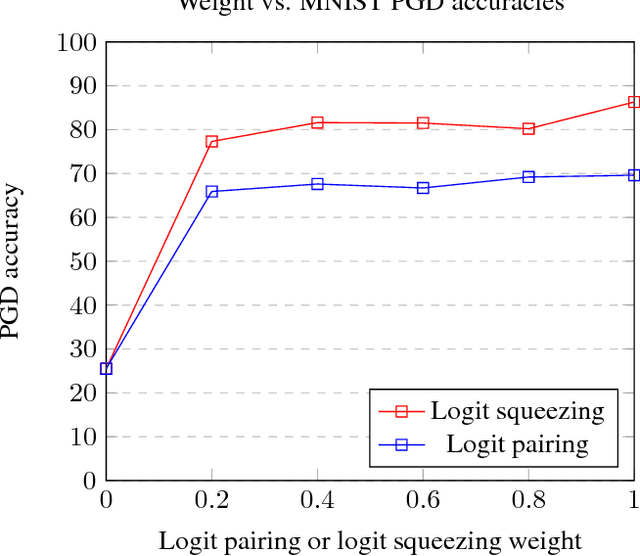

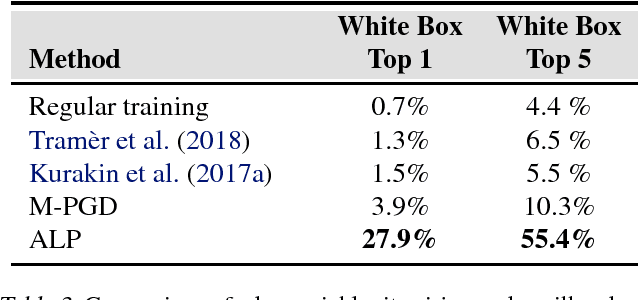
In this paper, we develop improved techniques for defending against adversarial examples at scale. First, we implement the state of the art version of adversarial training at unprecedented scale on ImageNet and investigate whether it remains effective in this setting - an important open scientific question (Athalye et al., 2018). Next, we introduce enhanced defenses using a technique we call logit pairing, a method that encourages logits for pairs of examples to be similar. When applied to clean examples and their adversarial counterparts, logit pairing improves accuracy on adversarial examples over vanilla adversarial training; we also find that logit pairing on clean examples only is competitive with adversarial training in terms of accuracy on two datasets. Finally, we show that adversarial logit pairing achieves the state of the art defense on ImageNet against PGD white box attacks, with an accuracy improvement from 1.5% to 27.9%. Adversarial logit pairing also successfully damages the current state of the art defense against black box attacks on ImageNet (Tramer et al., 2018), dropping its accuracy from 66.6% to 47.1%. With this new accuracy drop, adversarial logit pairing ties with Tramer et al.(2018) for the state of the art on black box attacks on ImageNet.
Eye Tracking for Everyone
Jun 18, 2016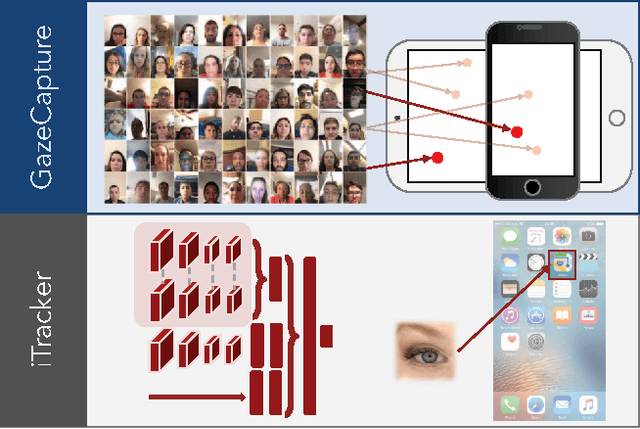
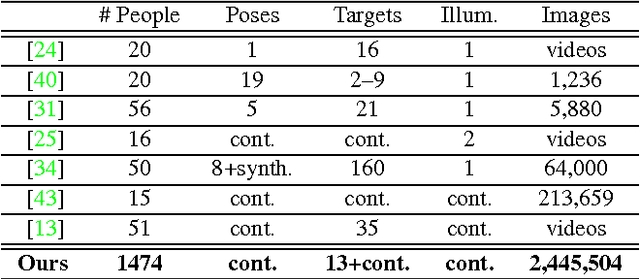

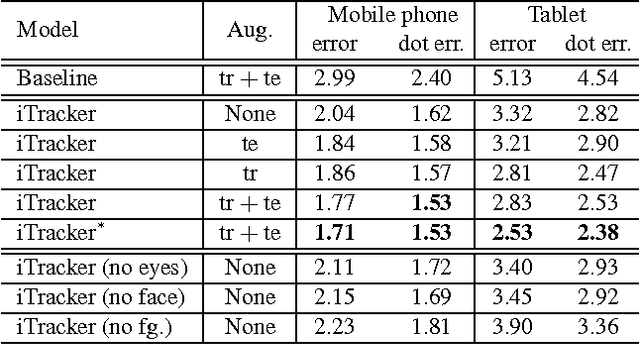
From scientific research to commercial applications, eye tracking is an important tool across many domains. Despite its range of applications, eye tracking has yet to become a pervasive technology. We believe that we can put the power of eye tracking in everyone's palm by building eye tracking software that works on commodity hardware such as mobile phones and tablets, without the need for additional sensors or devices. We tackle this problem by introducing GazeCapture, the first large-scale dataset for eye tracking, containing data from over 1450 people consisting of almost 2.5M frames. Using GazeCapture, we train iTracker, a convolutional neural network for eye tracking, which achieves a significant reduction in error over previous approaches while running in real time (10-15fps) on a modern mobile device. Our model achieves a prediction error of 1.71cm and 2.53cm without calibration on mobile phones and tablets respectively. With calibration, this is reduced to 1.34cm and 2.12cm. Further, we demonstrate that the features learned by iTracker generalize well to other datasets, achieving state-of-the-art results. The code, data, and models are available at http://gazecapture.csail.mit.edu.