 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Dissection: Quantifying Interpretability of Deep Visual Representations
Apr 19, 2017
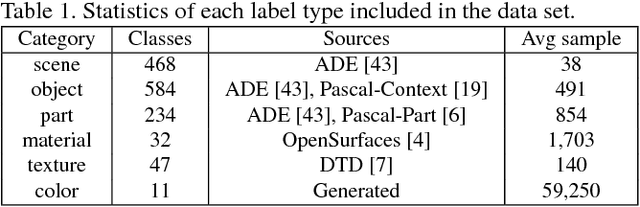
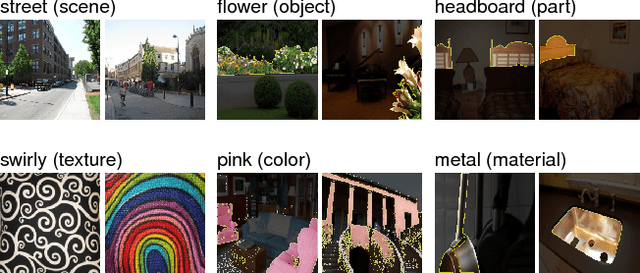

We propose a general framework called Network Dissection for quantifying the interpretability of latent representations of CNNs by evaluating the alignment between individual hidden units and a set of semantic concepts. Given any CNN model, the proposed method draws on a broad data set of visual concepts to score the semantics of hidden units at each intermediate convolutional layer. The units with semantics are given labels across a range of objects, parts, scenes, textures, materials, and colors. We use the proposed method to test the hypothesis that interpretability of units is equivalent to random linear combinations of units, then we apply our method to compare the latent representations of various networks when trained to solve different supervised and self-supervised training tasks. We further analyze the effect of training iterations, compare networks trained with different initializations, examine the impact of network depth and width, and measure the effect of dropout and batch normalization on the interpretability of deep visual representations. We demonstrate that the proposed method can shed light on characteristics of CNN models and training methods that go beyond measurements of their discriminative power.
Following Gaze Across Views
Dec 09, 2016


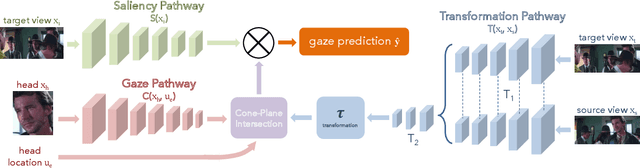
Following the gaze of people inside videos is an important signal for understanding people and their actions. In this paper, we present an approach for following gaze across views by predicting where a particular person is looking throughout a scene. We collect VideoGaze, a new dataset which we use as a benchmark to both train and evaluate models. Given one view with a person in it and a second view of the scene, our model estimates a density for gaze location in the second view. A key aspect of our approach is an end-to-end model that solves the following sub-problems: saliency, gaze pose, and geometric relationships between views. Although our model is supervised only with gaze, we show that the model learns to solve these subproblems automatically without supervision. Experiments suggest that our approach follows gaze better than standard baselines and produces plausible results for everyday situations.
Places: An Image Database for Deep Scene Understanding
Oct 06, 2016
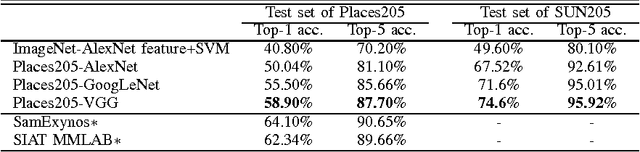

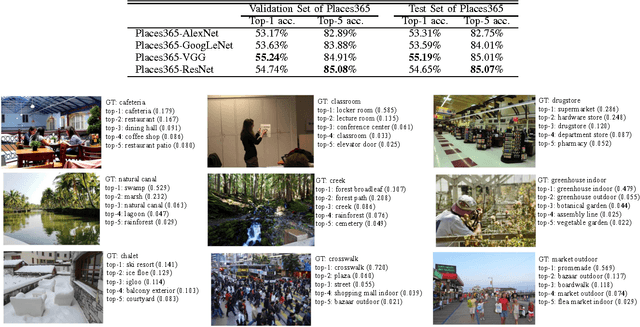
The rise of multi-million-item dataset initiatives has enabled data-hungry machine learning algorithms to reach near-human semantic classification at tasks such as object and scene recognition. Here we describe the Places Database, a repository of 10 million scene photographs, labeled with scene semantic categories and attributes, comprising a quasi-exhaustive list of the types of environments encountered in the world. Using state of the art Convolutional Neural Networks, we provide impressive baseline performances at scene classification. With its high-coverage and high-diversity of exemplars, the Places Database offers an ecosystem to guide future progress on currently intractable visual recognition problems.
Eye Tracking for Everyone
Jun 18, 2016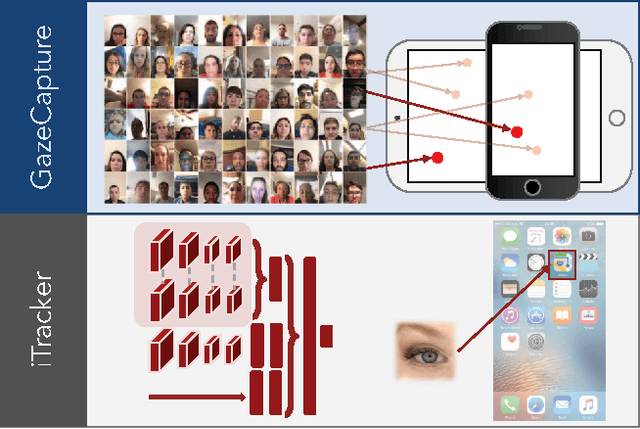
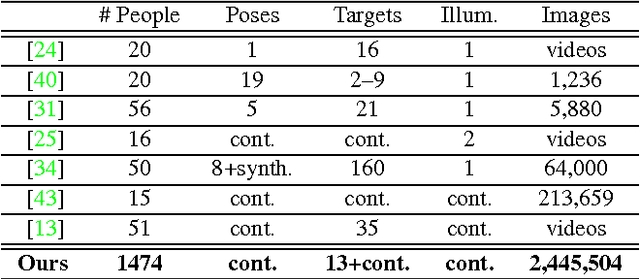

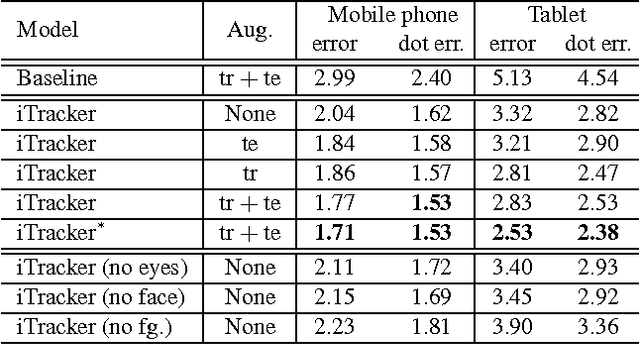
From scientific research to commercial applications, eye tracking is an important tool across many domains. Despite its range of applications, eye tracking has yet to become a pervasive technology. We believe that we can put the power of eye tracking in everyone's palm by building eye tracking software that works on commodity hardware such as mobile phones and tablets, without the need for additional sensors or devices. We tackle this problem by introducing GazeCapture, the first large-scale dataset for eye tracking, containing data from over 1450 people consisting of almost 2.5M frames. Using GazeCapture, we train iTracker, a convolutional neural network for eye tracking, which achieves a significant reduction in error over previous approaches while running in real time (10-15fps) on a modern mobile device. Our model achieves a prediction error of 1.71cm and 2.53cm without calibration on mobile phones and tablets respectively. With calibration, this is reduced to 1.34cm and 2.12cm. Further, we demonstrate that the features learned by iTracker generalize well to other datasets, achieving state-of-the-art results. The code, data, and models are available at http://gazecapture.csail.mit.edu.
Deep Learning for Identifying Metastatic Breast Cancer
Jun 18, 2016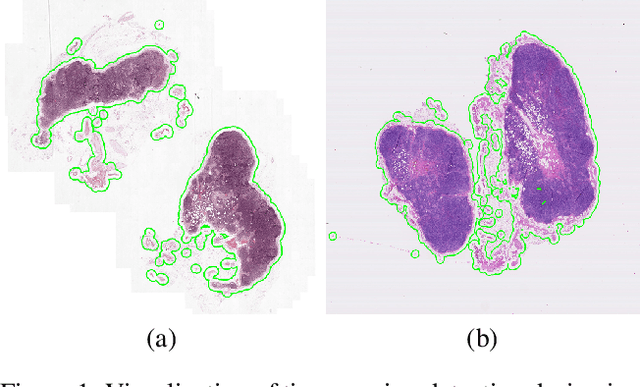
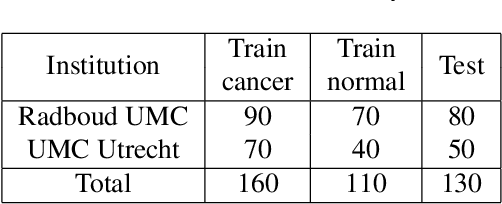
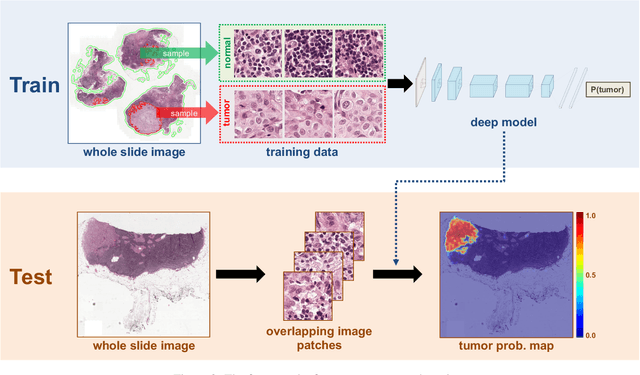
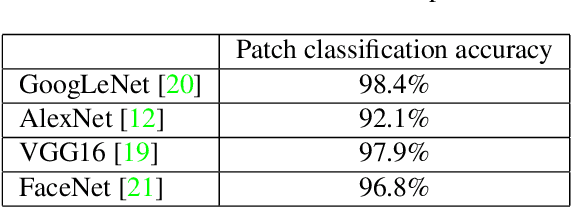
The International Symposium on Biomedical Imaging (ISBI) held a grand challenge to evaluate computational systems for the automated detection of metastatic breast cancer in whole slide images of sentinel lymph node biopsies. Our team won both competitions in the grand challenge, obtaining an area under the receiver operating curve (AUC) of 0.925 for the task of whole slide image classification and a score of 0.7051 for the tumor localization task. A pathologist independently reviewed the same images, obtaining a whole slide image classification AUC of 0.966 and a tumor localization score of 0.733. Combining our deep learning system's predictions with the human pathologist's diagnoses increased the pathologist's AUC to 0.995, representing an approximately 85 percent reduction in human error rate. These results demonstrate the power of using deep learning to produce significant improvements in the accuracy of pathological diagnoses.
Deep Neural Networks predict Hierarchical Spatio-temporal Cortical Dynamics of Human Visual Object Recognition
Jan 12, 2016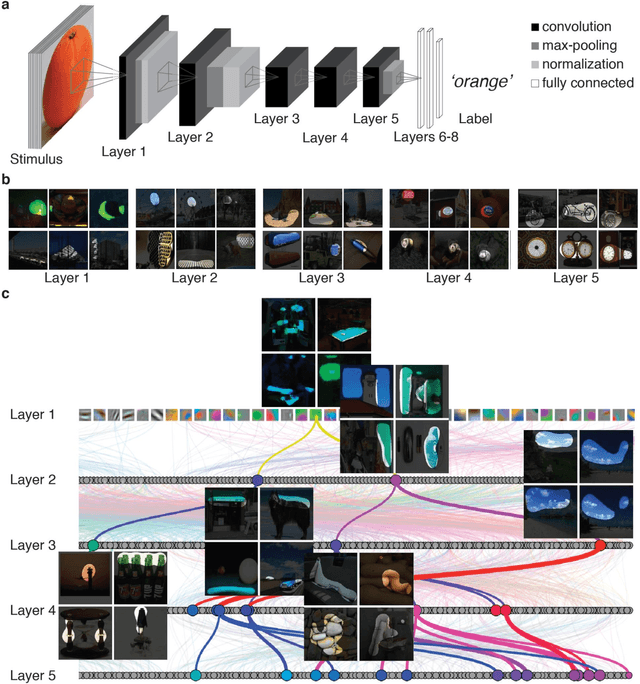
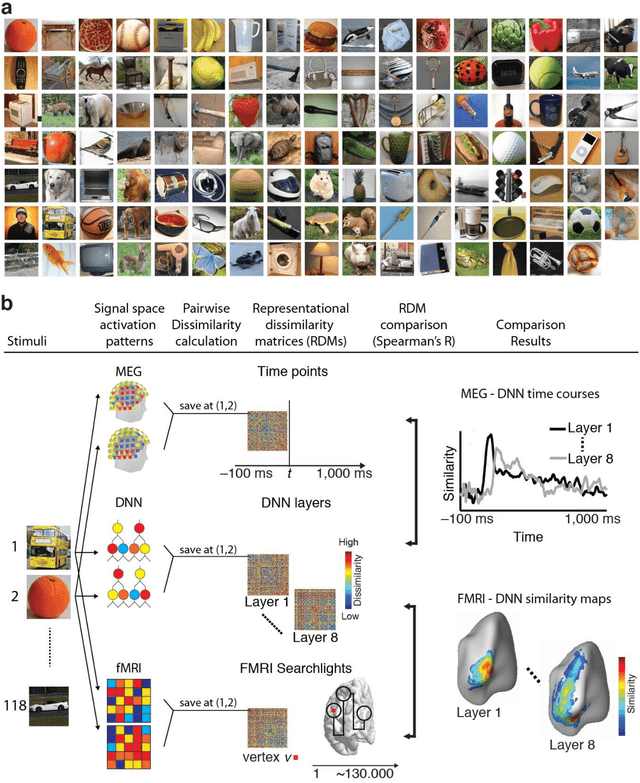
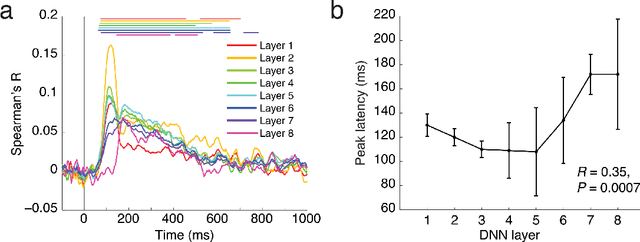
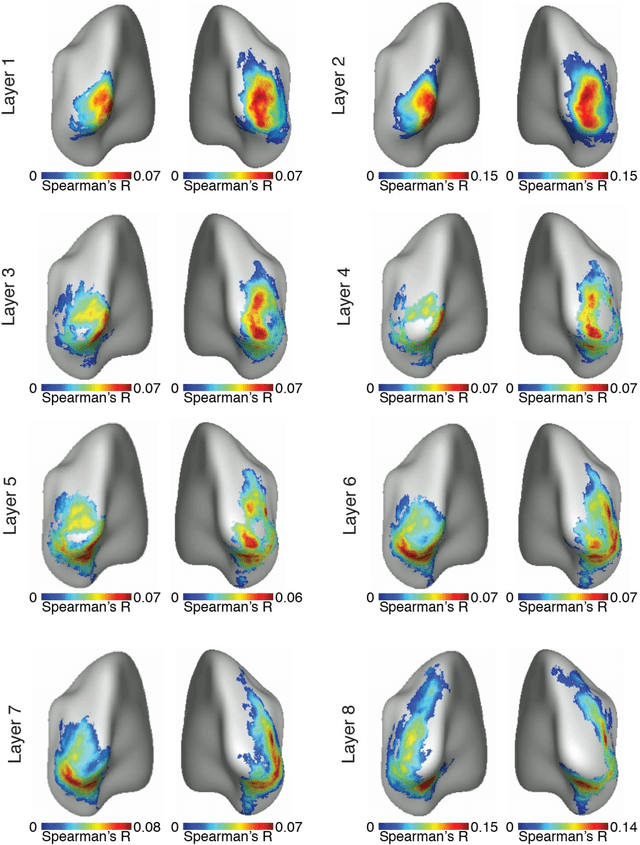
The complex multi-stage architecture of cortical visual pathways provides the neural basis for efficient visual object recognition in humans. However, the stage-wise computations therein remain poorly understood. Here, we compared temporal (magnetoencephalography) and spatial (functional MRI) visual brain representations with representations in an artificial deep neural network (DNN) tuned to the statistics of real-world visual recognition. We showed that the DNN captured the stages of human visual processing in both time and space from early visual areas towards the dorsal and ventral streams. Further investigation of crucial DNN parameters revealed that while model architecture was important, training on real-world categorization was necessary to enforce spatio-temporal hierarchical relationships with the brain. Together our results provide an algorithmically informed view on the spatio-temporal dynamics of visual object recognition in the human visual brain.
Learning Deep Features for Discriminative Localization
Dec 14, 2015

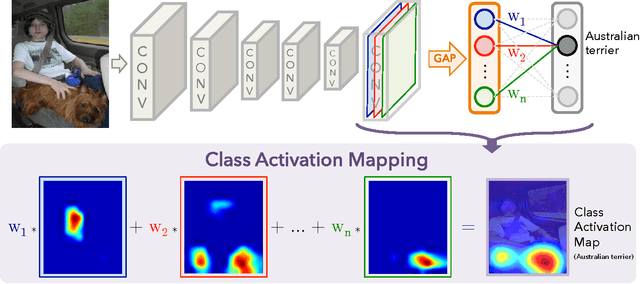
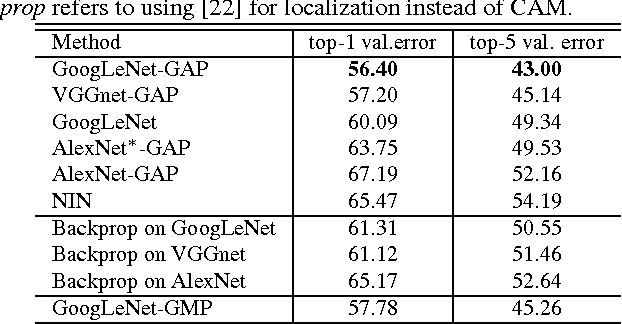
In this work, we revisit the global average pooling layer proposed in [13], and shed light on how it explicitly enables the convolutional neural network to have remarkable localization ability despite being trained on image-level labels. While this technique was previously proposed as a means for regularizing training, we find that it actually builds a generic localizable deep representation that can be applied to a variety of tasks. Despite the apparent simplicity of global average pooling, we are able to achieve 37.1% top-5 error for object localization on ILSVRC 2014, which is remarkably close to the 34.2% top-5 error achieved by a fully supervised CNN approach. We demonstrate that our network is able to localize the discriminative image regions on a variety of tasks despite not being trained for them
Object Detectors Emerge in Deep Scene CNNs
Apr 15, 2015


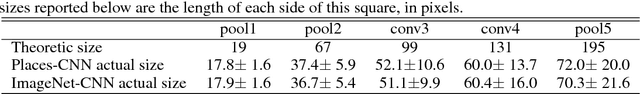
With the success of new computational architectures for visual processing, such as convolutional neural networks (CNN) and access to image databases with millions of labeled examples (e.g., ImageNet, Places), the state of the art in computer vision is advancing rapidly. One important factor for continued progress is to understand the representations that are learned by the inner layers of these deep architectures. Here we show that object detectors emerge from training CNNs to perform scene classification. As scenes are composed of objects, the CNN for scene classification automatically discovers meaningful objects detectors, representative of the learned scene categories. With object detectors emerging as a result of learning to recognize scenes, our work demonstrates that the same network can perform both scene recognition and object localization in a single forward-pass, without ever having been explicitly taught the notion of objects.
3D ShapeNets: A Deep Representation for Volumetric Shapes
Apr 15, 2015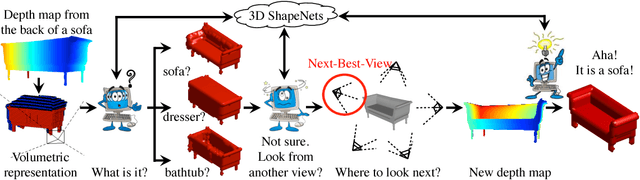
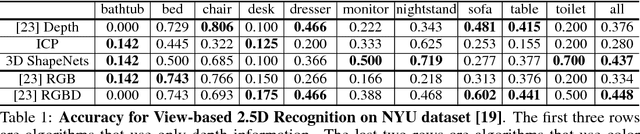
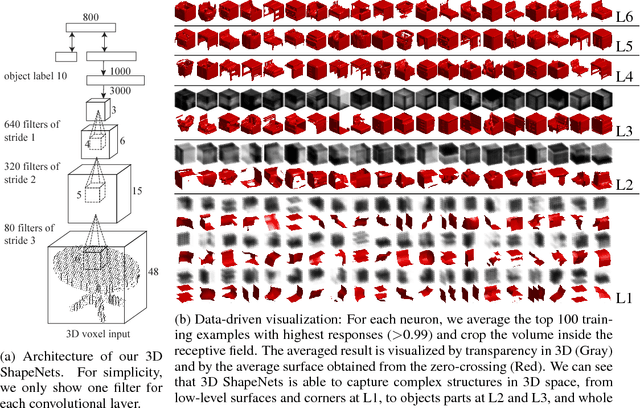

3D shape is a crucial but heavily underutilized cue in today's computer vision systems, mostly due to the lack of a good generic shape representation. With the recent availability of inexpensive 2.5D depth sensors (e.g. Microsoft Kinect), it is becoming increasingly important to have a powerful 3D shape representation in the loop. Apart from category recognition, recovering full 3D shapes from view-based 2.5D depth maps is also a critical part of visual understanding. To this end, we propose to represent a geometric 3D shape as a probability distribution of binary variables on a 3D voxel grid, using a Convolutional Deep Belief Network. Our model, 3D ShapeNets, learns the distribution of complex 3D shapes across different object categories and arbitrary poses from raw CAD data, and discovers hierarchical compositional part representations automatically. It naturally supports joint object recognition and shape completion from 2.5D depth maps, and it enables active object recognition through view planning. To train our 3D deep learning model, we construct ModelNet -- a large-scale 3D CAD model dataset. Extensive experiments show that our 3D deep representation enables significant performance improvement over the-state-of-the-arts in a variety of tasks.
Visualizing Object Detection Features
Feb 19, 2015
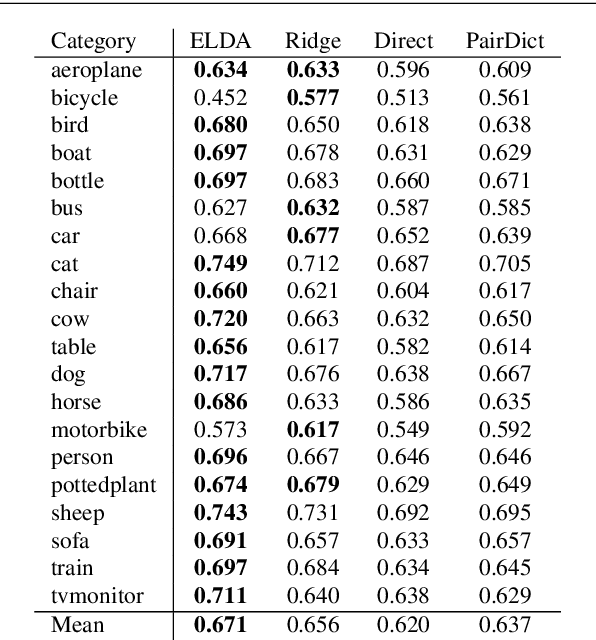

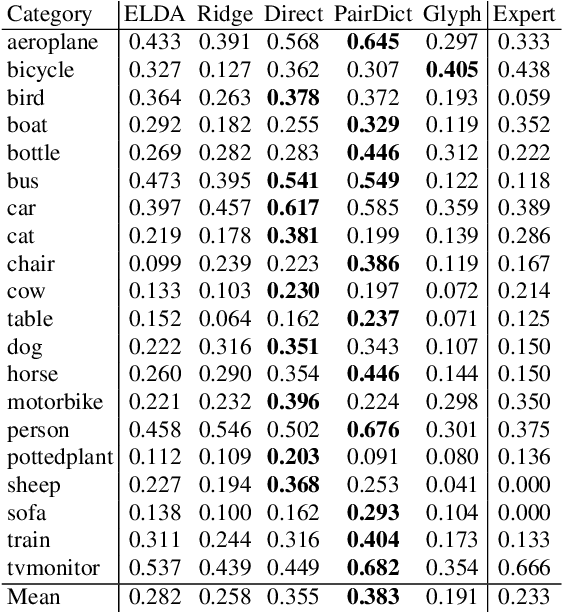
We introduce algorithms to visualize feature spaces used by object detectors. Our method works by inverting a visual feature back to multiple natural images. We found that these visualizations allow us to analyze object detection systems in new ways and gain new insight into the detector's failures. For example, when we visualize the features for high scoring false alarms, we discovered that, although they are clearly wrong in image space, they do look deceptively similar to true positives in feature space. This result suggests that many of these false alarms are caused by our choice of feature space, and supports that creating a better learning algorithm or building bigger datasets is unlikely to correct these errors. By visualizing feature spaces, we can gain a more intuitive understanding of recognition systems.