 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.
SuperGlue: Learning Feature Matching with Graph Neural Networks
Nov 26, 2019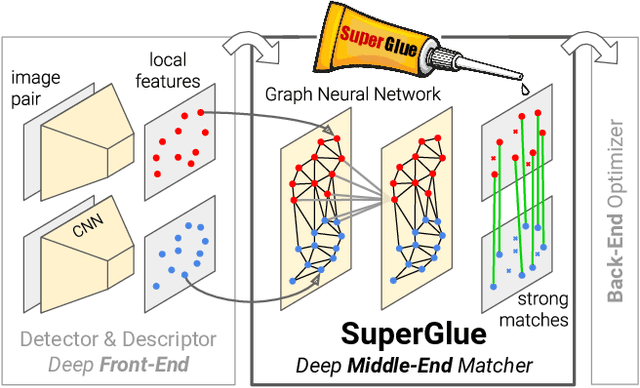


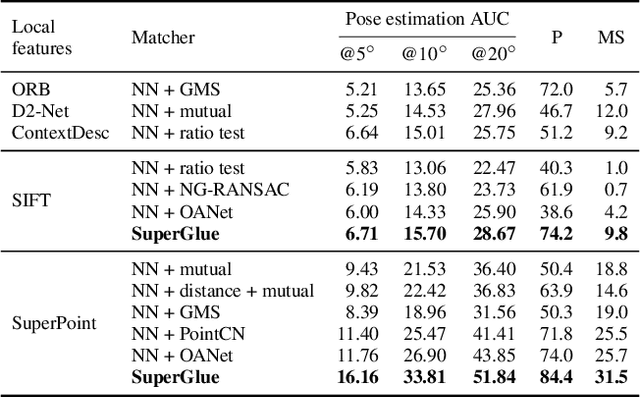
This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics, our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and can be readily integrated into modern SfM or SLAM systems.
Deep ChArUco: Dark ChArUco Marker Pose Estimation
Dec 08, 2018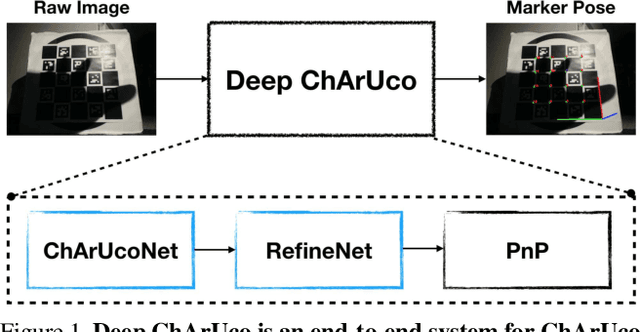


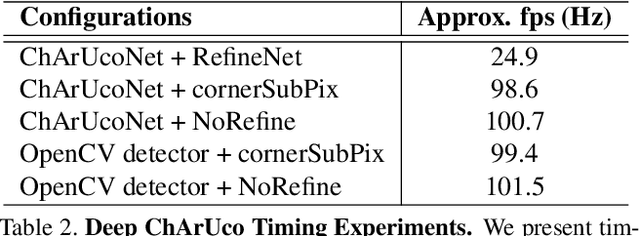
ChArUco boards are used for camera calibration, monocular pose estimation, and pose verification in both robotics and augmented reality. Such fiducials are detectable via traditional computer vision methods (as found in OpenCV) in well-lit environments, but classical methods fail when the lighting is poor or when the image undergoes extreme motion blur. We present Deep ChArUco, a real-time pose estimation system which combines two custom deep networks, ChArUcoNet and RefineNet, with the Perspective-n-Point (PnP) algorithm to estimate the marker's 6DoF pose. ChArUcoNet is a two-headed marker-specific convolutional neural network (CNN) which jointly outputs ID-specific classifiers and 2D point locations. The 2D point locations are further refined into subpixel coordinates using RefineNet. Our networks are trained using a combination of auto-labeled videos of the target marker, synthetic subpixel corner data, and extreme data augmentation. We evaluate Deep ChArUco in challenging low-light, high-motion, high-blur scenarios and demonstrate that our approach is superior to a traditional OpenCV-based method for ChArUco marker detection and pose estimation.
Self-Improving Visual Odometry
Dec 08, 2018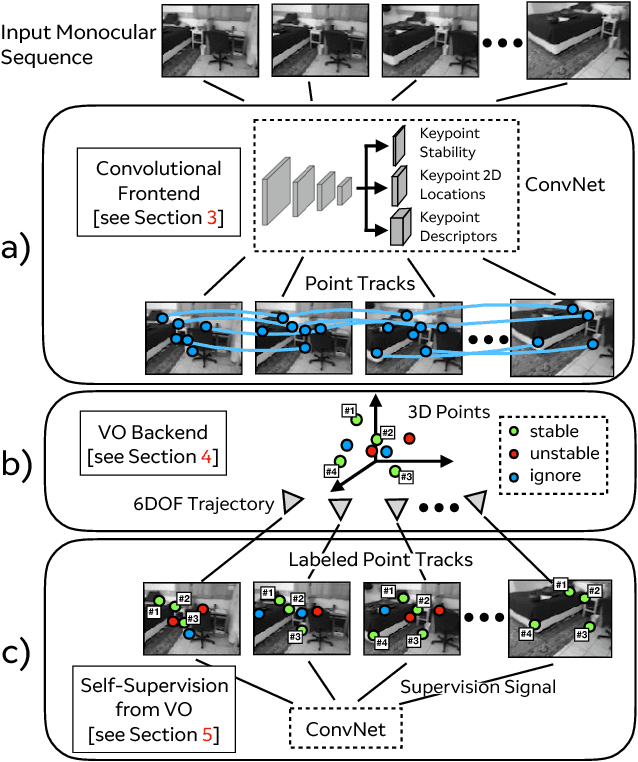
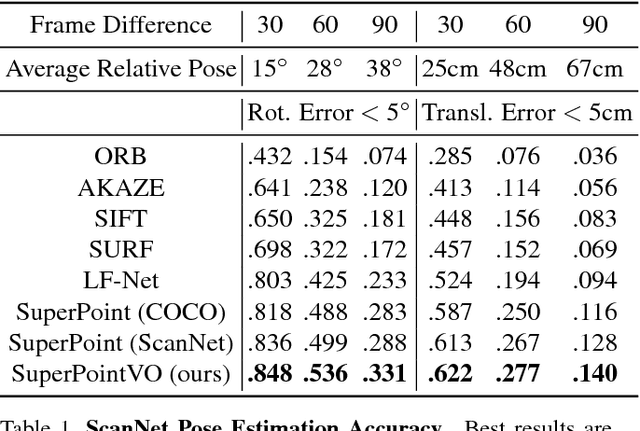

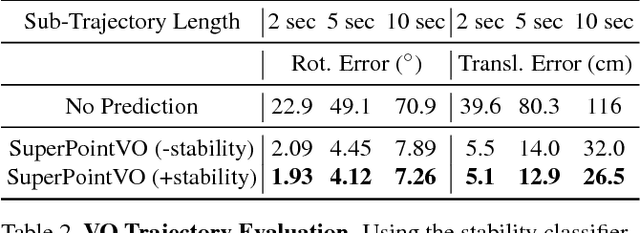
We propose a self-supervised learning framework that uses unlabeled monocular video sequences to generate large-scale supervision for training a Visual Odometry (VO) frontend, a network which computes pointwise data associations across images. Our self-improving method enables a VO frontend to learn over time, unlike other VO and SLAM systems which require time-consuming hand-tuning or expensive data collection to adapt to new environments. Our proposed frontend operates on monocular images and consists of a single multi-task convolutional neural network which outputs 2D keypoints locations, keypoint descriptors, and a novel point stability score. We use the output of VO to create a self-supervised dataset of point correspondences to retrain the frontend. When trained using VO at scale on 2.5 million monocular images from ScanNet, the stability classifier automatically discovers a ranking for keypoints that are not likely to help in VO, such as t-junctions across depth discontinuities, features on shadows and highlights, and dynamic objects like people. The resulting frontend outperforms both traditional methods (SIFT, ORB, AKAZE) and deep learning methods (SuperPoint and LF-Net) in a 3D-to-2D pose estimation task on ScanNet.
SuperPoint: Self-Supervised Interest Point Detection and Description
Apr 19, 2018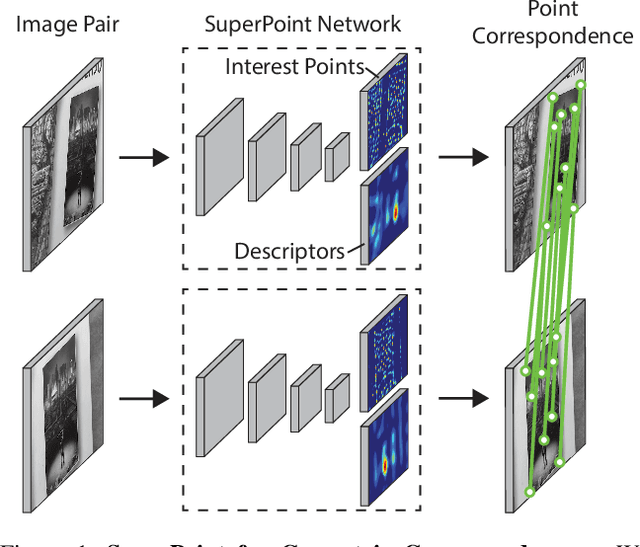

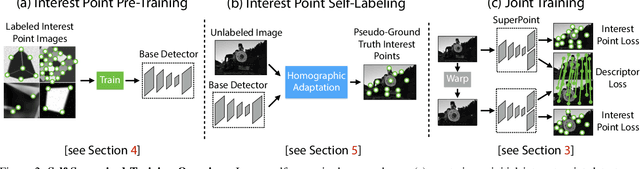

This paper presents a self-supervised framework for training interest point detectors and descriptors suitable for a large number of multiple-view geometry problems in computer vision. As opposed to patch-based neural networks, our fully-convolutional model operates on full-sized images and jointly computes pixel-level interest point locations and associated descriptors in one forward pass. We introduce Homographic Adaptation, a multi-scale, multi-homography approach for boosting interest point detection repeatability and performing cross-domain adaptation (e.g., synthetic-to-real). Our model, when trained on the MS-COCO generic image dataset using Homographic Adaptation, is able to repeatedly detect a much richer set of interest points than the initial pre-adapted deep model and any other traditional corner detector. The final system gives rise to state-of-the-art homography estimation results on HPatches when compared to LIFT, SIFT and ORB.
RoomNet: End-to-End Room Layout Estimation
Aug 07, 2017
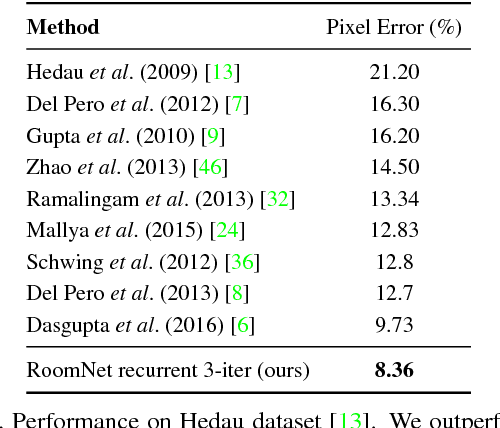


This paper focuses on the task of room layout estimation from a monocular RGB image. Prior works break the problem into two sub-tasks: semantic segmentation of floor, walls, ceiling to produce layout hypotheses, followed by an iterative optimization step to rank these hypotheses. In contrast, we adopt a more direct formulation of this problem as one of estimating an ordered set of room layout keypoints. The room layout and the corresponding segmentation is completely specified given the locations of these ordered keypoints. We predict the locations of the room layout keypoints using RoomNet, an end-to-end trainable encoder-decoder network. On the challenging benchmark datasets Hedau and LSUN, we achieve state-of-the-art performance along with 200x to 600x speedup compared to the most recent work. Additionally, we present optional extensions to the RoomNet architecture such as including recurrent computations and memory units to refine the keypoint locations under the same parametric capacity.
Toward Geometric Deep SLAM
Jul 24, 2017



We present a point tracking system powered by two deep convolutional neural networks. The first network, MagicPoint, operates on single images and extracts salient 2D points. The extracted points are "SLAM-ready" because they are by design isolated and well-distributed throughout the image. We compare this network against classical point detectors and discover a significant performance gap in the presence of image noise. As transformation estimation is more simple when the detected points are geometrically stable, we designed a second network, MagicWarp, which operates on pairs of point images (outputs of MagicPoint), and estimates the homography that relates the inputs. This transformation engine differs from traditional approaches because it does not use local point descriptors, only point locations. Both networks are trained with simple synthetic data, alleviating the requirement of expensive external camera ground truthing and advanced graphics rendering pipelines. The system is fast and lean, easily running 30+ FPS on a single CPU.
Deep Cuboid Detection: Beyond 2D Bounding Boxes
Nov 30, 2016


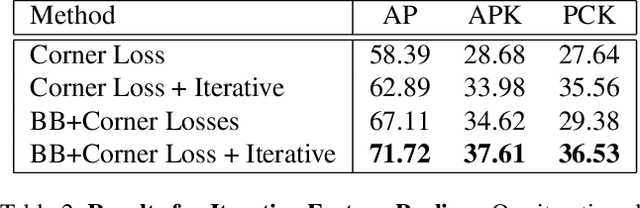
We present a Deep Cuboid Detector which takes a consumer-quality RGB image of a cluttered scene and localizes all 3D cuboids (box-like objects). Contrary to classical approaches which fit a 3D model from low-level cues like corners, edges, and vanishing points, we propose an end-to-end deep learning system to detect cuboids across many semantic categories (e.g., ovens, shipping boxes, and furniture). We localize cuboids with a 2D bounding box, and simultaneously localize the cuboid's corners, effectively producing a 3D interpretation of box-like objects. We refine keypoints by pooling convolutional features iteratively, improving the baseline method significantly. Our deep learning cuboid detector is trained in an end-to-end fashion and is suitable for real-time applications in augmented reality (AR) and robotics.
Deep Image Homography Estimation
Jun 13, 2016
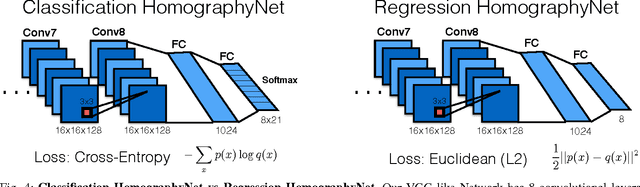


We present a deep convolutional neural network for estimating the relative homography between a pair of images. Our feed-forward network has 10 layers, takes two stacked grayscale images as input, and produces an 8 degree of freedom homography which can be used to map the pixels from the first image to the second. We present two convolutional neural network architectures for HomographyNet: a regression network which directly estimates the real-valued homography parameters, and a classification network which produces a distribution over quantized homographies. We use a 4-point homography parameterization which maps the four corners from one image into the second image. Our networks are trained in an end-to-end fashion using warped MS-COCO images. Our approach works without the need for separate local feature detection and transformation estimation stages. Our deep models are compared to a traditional homography estimator based on ORB features and we highlight the scenarios where HomographyNet outperforms the traditional technique. We also describe a variety of applications powered by deep homography estimation, thus showcasing the flexibility of a deep learning approach.
Visualizing Object Detection Features
Feb 19, 2015
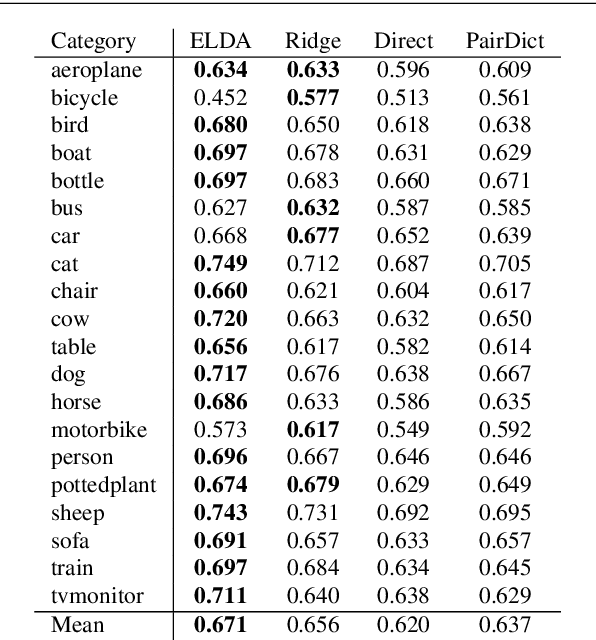

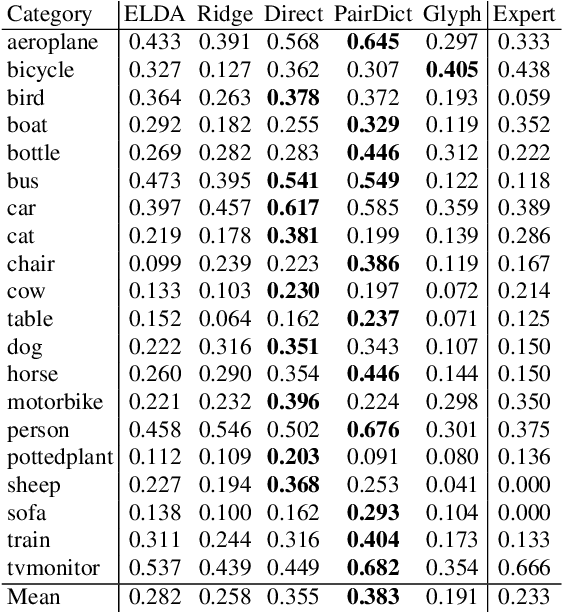
We introduce algorithms to visualize feature spaces used by object detectors. Our method works by inverting a visual feature back to multiple natural images. We found that these visualizations allow us to analyze object detection systems in new ways and gain new insight into the detector's failures. For example, when we visualize the features for high scoring false alarms, we discovered that, although they are clearly wrong in image space, they do look deceptively similar to true positives in feature space. This result suggests that many of these false alarms are caused by our choice of feature space, and supports that creating a better learning algorithm or building bigger datasets is unlikely to correct these errors. By visualizing feature spaces, we can gain a more intuitive understanding of recognition systems.