 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODA: Semantic-Oriented Distributional Alignment for Generative Recommendation
Feb 28, 2026Generative recommendation has emerged as a scalable alternative to traditional retrieve-and-rank pipelines by operating in a compact token space. However, existing methods mainly rely on discrete code-level supervision, which leads to information loss and limits the joint optimization between the tokenizer and the generative recommender. In this work, we propose a distribution-level supervision paradigm that leverages probability distributions over multi-layer codebooks as soft and information-rich representations. Building on this idea, we introduce Semantic-Oriented Distributional Alignment (SODA), a plug-and-play contrastive supervision framework based on Bayesian Personalized Ranking, which aligns semantically rich distributions via negative KL divergence while enabling end-to-end differentiable training. Extensive experiments on multiple real-world datasets demonstrate that SODA consistently improves the performance of various generative recommender backbones, validating its effectiveness and generality. Codes will be available upon acceptance.
UniGRec: Unified Generative Recommendation with Soft Identifiers for End-to-End Optimization
Jan 24, 2026Generative recommendation has recently emerged as a transformative paradigm that directly generates target items, surpassing traditional cascaded approaches. It typically involves two components: a tokenizer that learns item identifiers and a recommender trained on them. Existing methods often decouple tokenization from recommendation or rely on asynchronous alternating optimization, limiting full end-to-end alignment. To address this, we unify the tokenizer and recommender under the ultimate recommendation objective via differentiable soft item identifiers, enabling joint end-to-end training. However, this introduces three challenges: training-inference discrepancy due to soft-to-hard mismatch, item identifier collapse from codeword usage imbalance, and collaborative signal deficiency due to an overemphasis on fine-grained token-level semantics. To tackle these challenges, we propose UniGRec, a unified generative recommendation framework that addresses them from three perspectives. UniGRec employs Annealed Inference Alignment during tokenization to smoothly bridge soft training and hard inference, a Codeword Uniformity Regularization to prevent identifier collapse and encourage codebook diversity, and a Dual Collaborative Distillation mechanism that distills collaborative priors from a lightweight teacher model to jointly guide both the tokenizer and the recommender. Extensive experiments on real-world datasets demonstrate that UniGRec consistently outperforms state-of-the-art baseline methods. Our codes are available at https://github.com/Jialei-03/UniGRec.
UpBench: A Dynamically Evolving Real-World Labor-Market Agentic Benchmark Framework Built for Human-Centric AI
Nov 15, 2025As large language model (LLM) agents increasingly undertake digital work, reliable frameworks are needed to evaluate their real-world competence, adaptability, and capacity for human collaboration. Existing benchmarks remain largely static, synthetic, or domain-limited, providing limited insight into how agents perform in dynamic, economically meaningful environments. We introduce UpBench, a dynamically evolving benchmark grounded in real jobs drawn from the global Upwork labor marketplace. Each task corresponds to a verified client transaction, anchoring evaluation in genuine work activity and financial outcomes. UpBench employs a rubric-based evaluation framework, in which expert freelancers decompose each job into detailed, verifiable acceptance criteria and assess AI submissions with per-criterion feedback. This structure enables fine-grained analysis of model strengths, weaknesses, and instruction-following fidelity beyond binary pass/fail metrics. Human expertise is integrated throughout the data pipeline (from job curation and rubric construction to evaluation) ensuring fidelity to real professional standards and supporting research on human-AI collaboration. By regularly refreshing tasks to reflect the evolving nature of online work, UpBench provides a scalable, human-centered foundation for evaluating agentic systems in authentic labor-market contexts, offering a path toward a collaborative framework, where AI amplifies human capability through partnership rather than replacement.
Atlas: End-to-End 3D Scene Reconstruction from Posed Images
Mar 23, 2020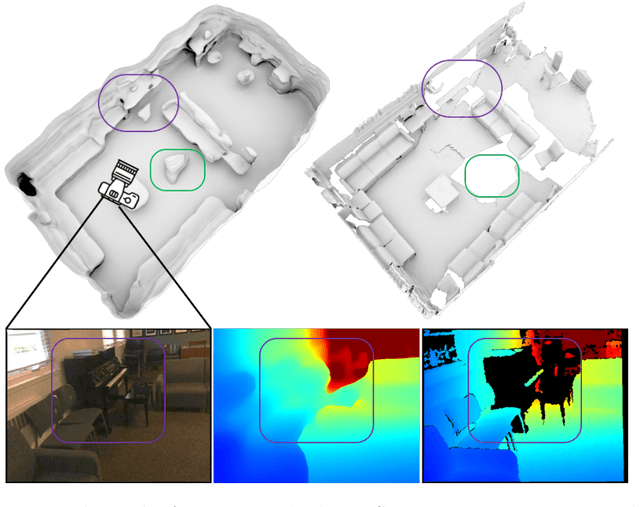
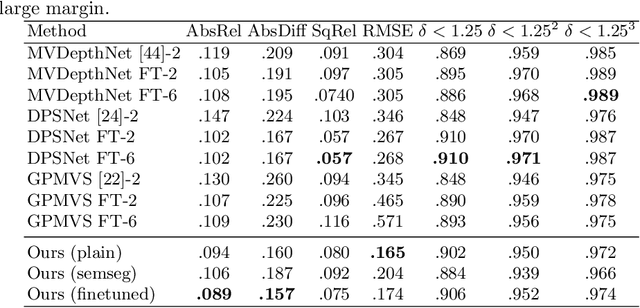
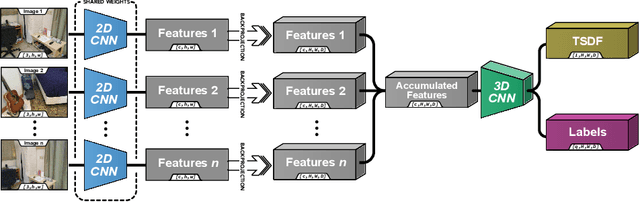
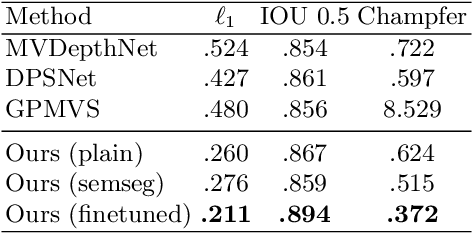
We present an end-to-end 3D reconstruction method for a scene by directly regressing a truncated signed distance function (TSDF) from a set of posed RGB images. Traditional approaches to 3D reconstruction rely on an intermediate representation of depth maps prior to estimating a full 3D model of a scene. We hypothesize that a direct regression to 3D is more effective. A 2D CNN extracts features from each image independently which are then back-projected and accumulated into a voxel volume using the camera intrinsics and extrinsics. After accumulation, a 3D CNN refines the accumulated features and predicts the TSDF values. Additionally, semantic segmentation of the 3D model is obtained without significant computation. This approach is evaluated on the Scannet dataset where we significantly outperform state-of-the-art baselines (deep multiview stereo followed by traditional TSDF fusion) both quantitatively and qualitatively. We compare our 3D semantic segmentation to prior methods that use a depth sensor since no previous work attempts the problem with only RGB input.
Depth Estimation by Learning Triangulation and Densification of Sparse Points for Multi-view Stereo
Mar 19, 2020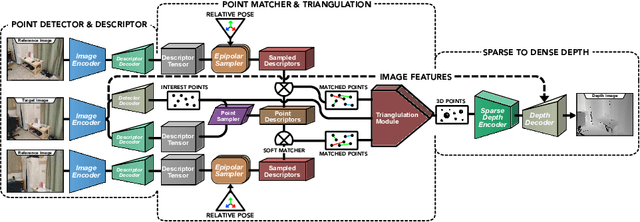
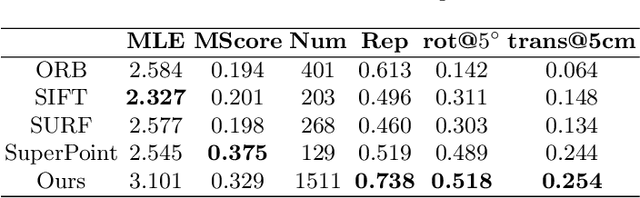
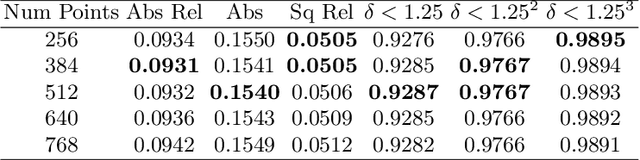

Multi-view stereo (MVS) is the golden mean between the accuracy of active depth sensing and the practicality of monocular depth estimation. Cost volume based approaches employing 3D convolutional neural networks (CNNs) have considerably improved the accuracy of MVS systems. However, this accuracy comes at a high computational cost which impedes practical adoption. Distinct from cost volume approaches, we propose an efficient depth estimation approach by first (a) detecting and evaluating descriptors for interest points, then (b) learning to match and triangulate a small set of interest points, and finally (c) densifying this sparse set of 3D points using CNNs. An end-to-end network efficiently performs all three steps within a deep learning framework and trained with intermediate 2D image and 3D geometric supervision, along with depth supervision. Crucially, our first step complements pose estimation using interest point detection and descriptor learning. We demonstrate that state-of-the-art results on depth estimation with lower compute for different scene lengths. Furthermore, our method generalizes to newer environments and the descriptors output by our network compare favorably to strong baselines.
MagicEyes: A Large Scale Eye Gaze Estimation Dataset for Mixed Reality
Mar 18, 2020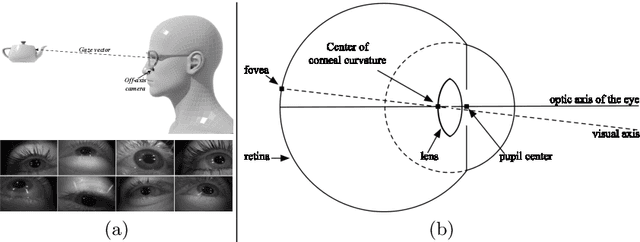
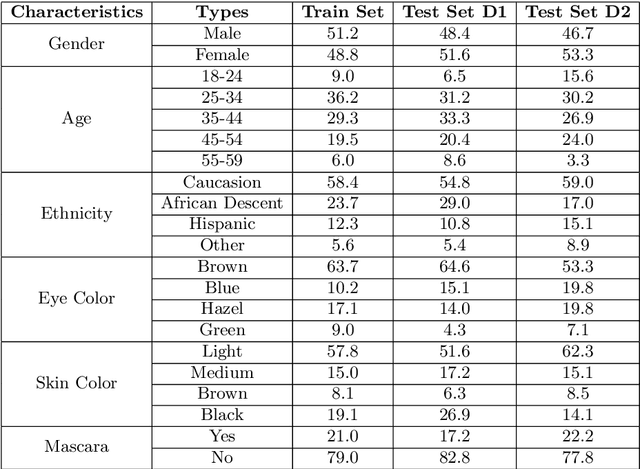

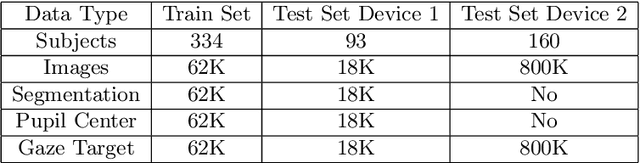
With the emergence of Virtual and Mixed Reality (XR) devices, eye tracking has received significant attention in the computer vision community. Eye gaze estimation is a crucial component in XR -- enabling energy efficient rendering, multi-focal displays, and effective interaction with content. In head-mounted XR devices, the eyes are imaged off-axis to avoid blocking the field of view. This leads to increased challenges in inferring eye related quantities and simultaneously provides an opportunity to develop accurate and robust learning based approaches. To this end, we present MagicEyes, the first large scale eye dataset collected using real MR devices with comprehensive ground truth labeling. MagicEyes includes $587$ subjects with $80,000$ images of human-labeled ground truth and over $800,000$ images with gaze target labels. We evaluate several state-of-the-art methods on MagicEyes and also propose a new multi-task EyeNet model designed for detecting the cornea, glints and pupil along with eye segmentation in a single forward pass.
Scan2Plan: Efficient Floorplan Generation from 3D Scans of Indoor Scenes
Mar 16, 2020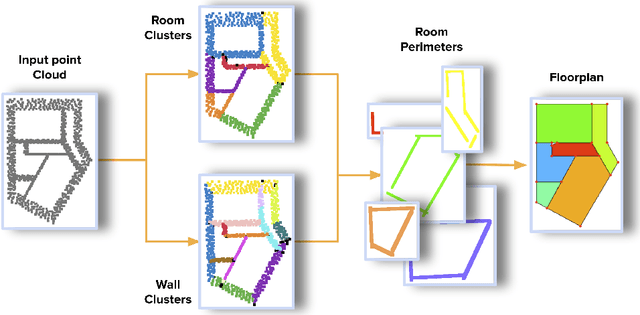
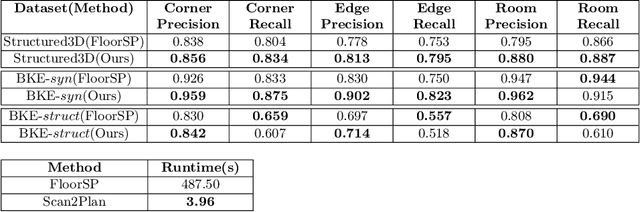
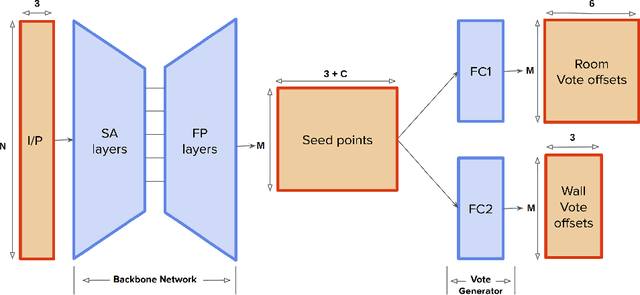
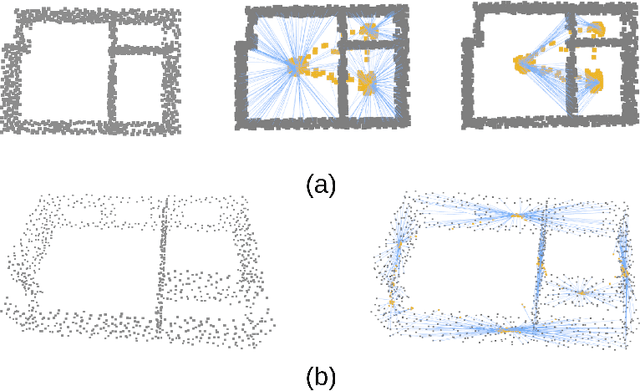
We introduce Scan2Plan, a novel approach for accurate estimation of a floorplan from a 3D scan of the structural elements of indoor environments. The proposed method incorporates a two-stage approach where the initial stage clusters an unordered point cloud representation of the scene into room instances and wall instances using a deep neural network based voting approach. The subsequent stage estimates a closed perimeter, parameterized by a simple polygon, for each individual room by finding the shortest path along the predicted room and wall keypoints. The final floorplan is simply an assembly of all such room perimeters in the global co-ordinate system. The Scan2Plan pipeline produces accurate floorplans for complex layouts, is highly parallelizable and extremely efficient compared to existing methods. The voting module is trained only on synthetic data and evaluated on publicly available Structured3D and BKE datasets to demonstrate excellent qualitative and quantitative results outperforming state-of-the-art techniques.
SuperGlue: Learning Feature Matching with Graph Neural Networks
Nov 26, 2019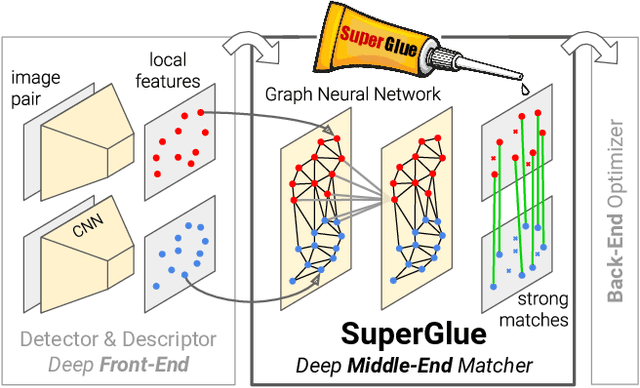


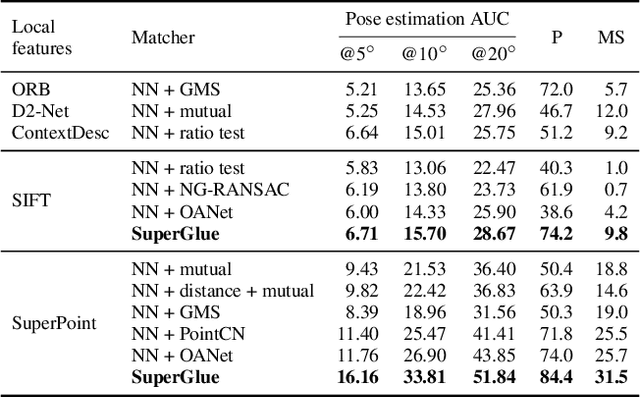
This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics, our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and can be readily integrated into modern SfM or SLAM systems.
Efficient 2.5D Hand Pose Estimation via Auxiliary Multi-Task Training for Embedded Devices
Sep 12, 2019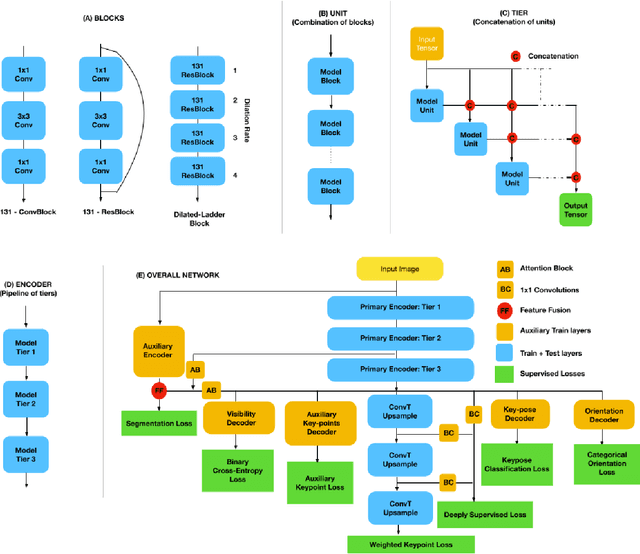
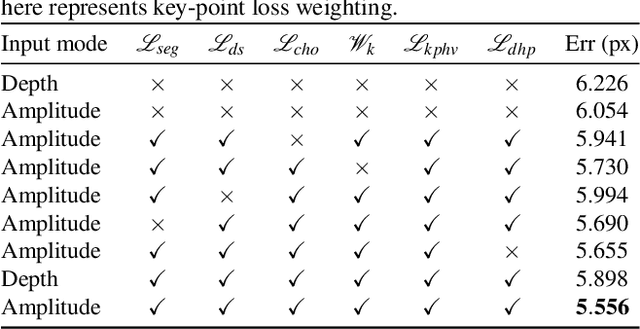

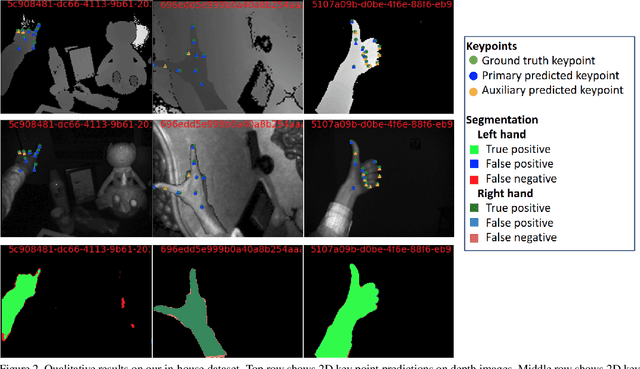
2D Key-point estimation is an important precursor to 3D pose estimation problems for human body and hands. In this work, we discuss the data, architecture, and training procedure necessary to deploy extremely efficient 2.5D hand pose estimation on embedded devices with highly constrained memory and compute envelope, such as AR/VR wearables. Our 2.5D hand pose estimation consists of 2D key-point estimation of joint positions on an egocentric image, captured by a depth sensor, and lifted to 2.5D using the corresponding depth values. Our contributions are two fold: (a) We discuss data labeling and augmentation strategies, the modules in the network architecture that collectively lead to $3\%$ the flop count and $2\%$ the number of parameters when compared to the state of the art MobileNetV2 architecture. (b) We propose an auxiliary multi-task training strategy needed to compensate for the small capacity of the network while achieving comparable performance to MobileNetV2. Our 32-bit trained model has a memory footprint of less than 300 Kilobytes, operates at more than 50 Hz with less than 35 MFLOPs.
EyeNet: A Multi-Task Network for Off-Axis Eye Gaze Estimation and User Understanding
Aug 24, 2019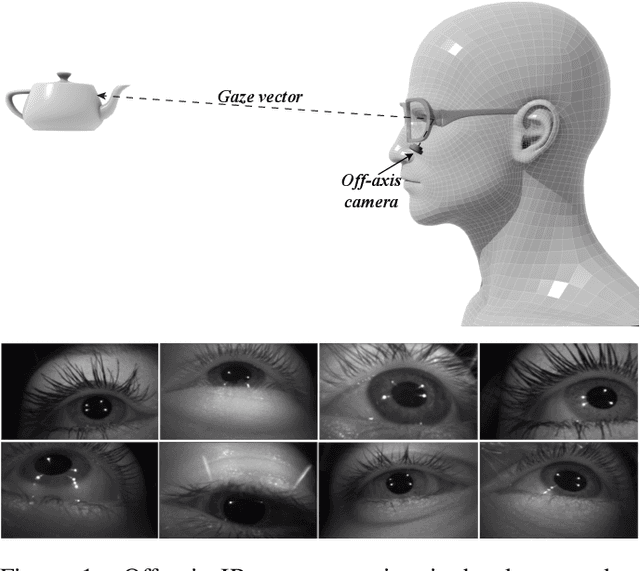
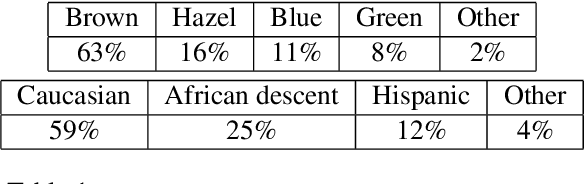
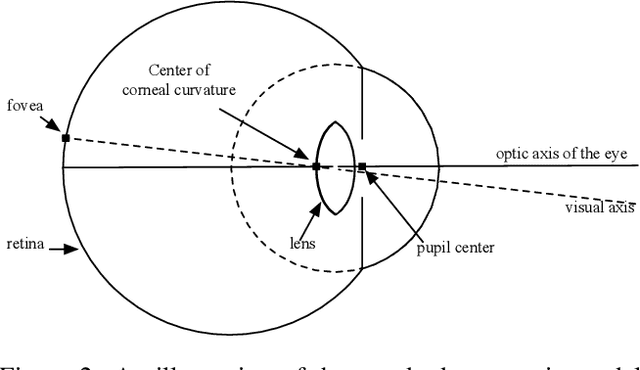
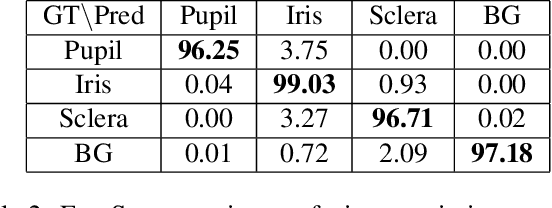
Eye gaze estimation and simultaneous semantic understanding of a user through eye images is a crucial component in Virtual and Mixed Reality; enabling energy efficient rendering, multi-focal displays and effective interaction with 3D content. In head-mounted VR/MR devices the eyes are imaged off-axis to avoid blocking the user's gaze, this view-point makes drawing eye related inferences very challenging. In this work, we present EyeNet, the first single deep neural network which solves multiple heterogeneous tasks related to eye gaze estimation and semantic user understanding for an off-axis camera setting. The tasks include eye segmentation, blink detection, emotive expression classification, IR LED glints detection, pupil and cornea center estimation. To train EyeNet end-to-end we employ both hand labelled supervision and model based supervision. We benchmark all tasks on MagicEyes, a large and new dataset of 587 subjects with varying morphology, gender, skin-color, make-up and imaging conditions.