 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Multiplex Spatial-Temporal Transition Graph Representation Learning for Socially Enhanced POI Recommendation
Aug 11, 2025Next Point-of-Interest (POI) recommendation is a research hotspot in business intelligence, where users' spatial-temporal transitions and social relationships play key roles. However, most existing works model spatial and temporal transitions separately, leading to misaligned representations of the same spatial-temporal key nodes. This misalignment introduces redundant information during fusion, increasing model uncertainty and reducing interpretability. To address this issue, we propose DiMuST, a socially enhanced POI recommendation model based on disentangled representation learning over multiplex spatial-temporal transition graphs. The model employs a novel Disentangled variational multiplex graph Auto-Encoder (DAE), which first disentangles shared and private distributions using a multiplex spatial-temporal graph strategy. It then fuses the shared features via a Product of Experts (PoE) mechanism and denoises the private features through contrastive constraints. The model effectively captures the spatial-temporal transition representations of POIs while preserving the intrinsic correlation of their spatial-temporal relationships. Experiments on two challenging datasets demonstrate that our DiMuST significantly outperforms existing methods across multiple metrics.
MemoryKT: An Integrative Memory-and-Forgetting Method for Knowledge Tracing
Aug 11, 2025Knowledge Tracing (KT) is committed to capturing students' knowledge mastery from their historical interactions. Simulating students' memory states is a promising approach to enhance both the performance and interpretability of knowledge tracing models. Memory consists of three fundamental processes: encoding, storage, and retrieval. Although forgetting primarily manifests during the storage stage, most existing studies rely on a single, undifferentiated forgetting mechanism, overlooking other memory processes as well as personalized forgetting patterns. To address this, this paper proposes memoryKT, a knowledge tracing model based on a novel temporal variational autoencoder. The model simulates memory dynamics through a three-stage process: (i) Learning the distribution of students' knowledge memory features, (ii) Reconstructing their exercise feedback, while (iii) Embedding a personalized forgetting module within the temporal workflow to dynamically modulate memory storage strength. This jointly models the complete encoding-storage-retrieval cycle, significantly enhancing the model's perception capability for individual differences. Extensive experiments on four public datasets demonstrate that our proposed approach significantly outperforms state-of-the-art baselines.
WebCanvas: Benchmarking Web Agents in Online Environments
Jun 18, 2024For web agents to be practically useful, they must adapt to the continuously evolving web environment characterized by frequent updates to user interfaces and content. However, most existing benchmarks only capture the static aspects of the web. To bridge this gap, we introduce WebCanvas, an innovative online evaluation framework for web agents that effectively addresses the dynamic nature of web interactions. WebCanvas contains three main components to facilitate realistic assessments: (1) A novel evaluation metric which reliably capture critical intermediate actions or states necessary for task completions while disregarding noise caused by insignificant events or changed web-elements. (2) A benchmark dataset called Mind2Web-Live, a refined version of original Mind2Web static dataset containing 542 tasks with 2439 intermediate evaluation states; (3) Lightweight and generalizable annotation tools and testing pipelines that enables the community to collect and maintain the high-quality, up-to-date dataset. Building on WebCanvas, we open-source an agent framework with extensible modules for reasoning, providing a foundation for the community to conduct online inference and evaluations. Our best-performing agent achieves a task success rate of 23.1% and a task completion rate of 48.8% on the Mind2Web-Live test set. Additionally, we analyze the performance discrepancies across various websites, domains, and experimental environments. We encourage the community to contribute further insights on online agent evaluation, thereby advancing this field of research.
ExamGAN and Twin-ExamGAN for Exam Script Generation
Aug 22, 2021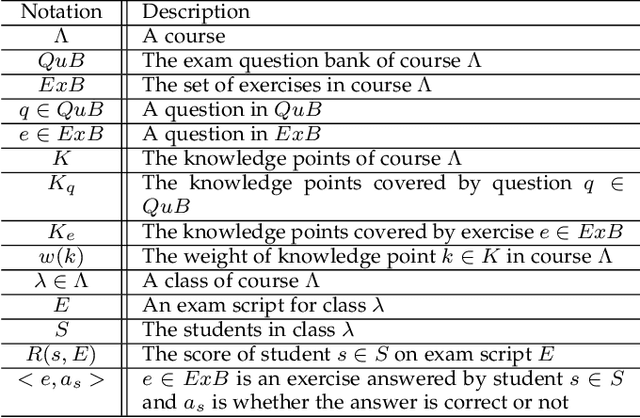
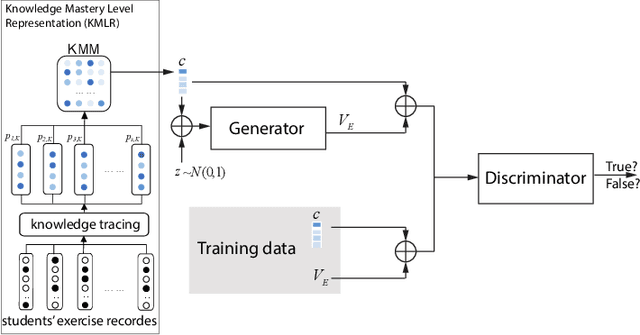

Nowadays, the learning management system (LMS) has been widely used in different educational stages from primary to tertiary education for student administration, documentation, tracking, reporting, and delivery of educational courses, training programs, or learning and development programs. Towards effective learning outcome assessment, the exam script generation problem has attracted many attentions and been investigated recently. But the research in this field is still in its early stage. There are opportunities to further improve the quality of generated exam scripts in various aspects. In particular, two essential issues have been ignored largely by existing solutions. First, given a course, it is unknown yet how to generate an exam script which can result in a desirable distribution of student scores in a class (or across different classes). Second, while it is frequently encountered in practice, it is unknown so far how to generate a pair of high quality exam scripts which are equivalent in assessment (i.e., the student scores are comparable by taking either of them) but have significantly different sets of questions. To fill the gap, this paper proposes ExamGAN (Exam Script Generative Adversarial Network) to generate high quality exam scripts, and then extends ExamGAN to T-ExamGAN (Twin-ExamGAN) to generate a pair of high quality exam scripts. Based on extensive experiments on three benchmark datasets, it has verified the superiority of proposed solutions in various aspects against the state-of-the-art. Moreover, we have conducted a case study which demonstrated the effectiveness of proposed solution in a real teaching scenario.
MagicEyes: A Large Scale Eye Gaze Estimation Dataset for Mixed Reality
Mar 18, 2020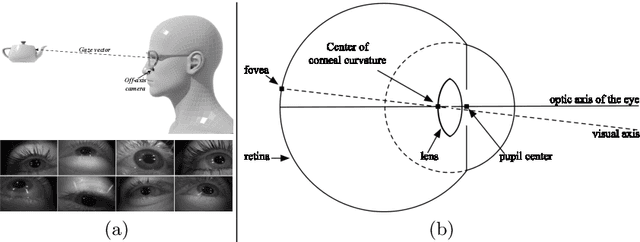
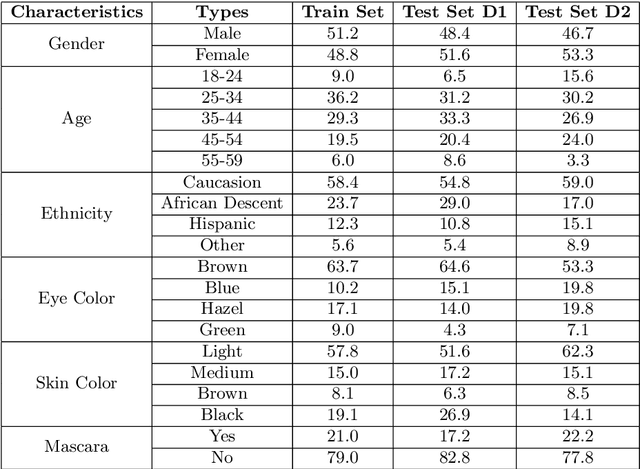

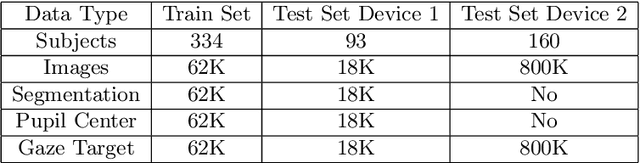
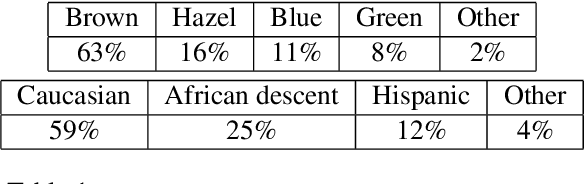
With the emergence of Virtual and Mixed Reality (XR) devices, eye tracking has received significant attention in the computer vision community. Eye gaze estimation is a crucial component in XR -- enabling energy efficient rendering, multi-focal displays, and effective interaction with content. In head-mounted XR devices, the eyes are imaged off-axis to avoid blocking the field of view. This leads to increased challenges in inferring eye related quantities and simultaneously provides an opportunity to develop accurate and robust learning based approaches. To this end, we present MagicEyes, the first large scale eye dataset collected using real MR devices with comprehensive ground truth labeling. MagicEyes includes $587$ subjects with $80,000$ images of human-labeled ground truth and over $800,000$ images with gaze target labels. We evaluate several state-of-the-art methods on MagicEyes and also propose a new multi-task EyeNet model designed for detecting the cornea, glints and pupil along with eye segmentation in a single forward pass.
EyeNet: A Multi-Task Network for Off-Axis Eye Gaze Estimation and User Understanding
Aug 24, 2019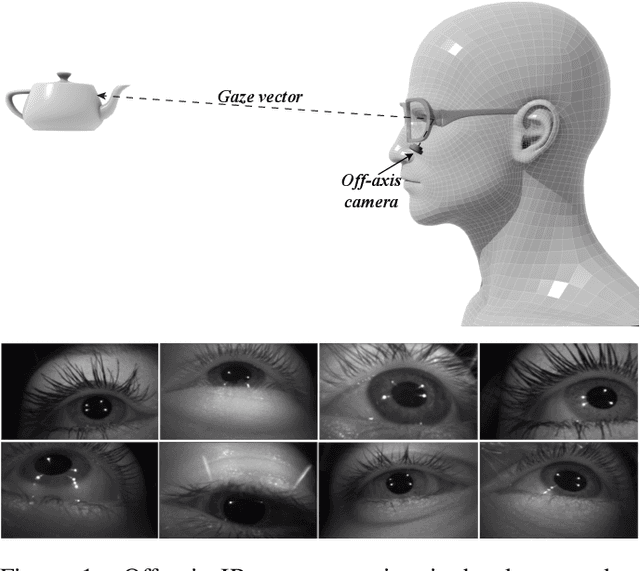
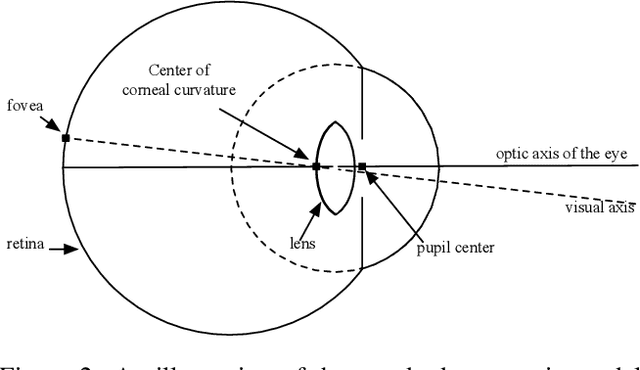
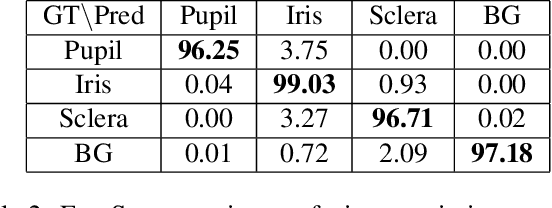
Eye gaze estimation and simultaneous semantic understanding of a user through eye images is a crucial component in Virtual and Mixed Reality; enabling energy efficient rendering, multi-focal displays and effective interaction with 3D content. In head-mounted VR/MR devices the eyes are imaged off-axis to avoid blocking the user's gaze, this view-point makes drawing eye related inferences very challenging. In this work, we present EyeNet, the first single deep neural network which solves multiple heterogeneous tasks related to eye gaze estimation and semantic user understanding for an off-axis camera setting. The tasks include eye segmentation, blink detection, emotive expression classification, IR LED glints detection, pupil and cornea center estimation. To train EyeNet end-to-end we employ both hand labelled supervision and model based supervision. We benchmark all tasks on MagicEyes, a large and new dataset of 587 subjects with varying morphology, gender, skin-color, make-up and imaging conditions.
Learning Articulated Motion Models from Visual and Lingual Signals
Jul 01, 2016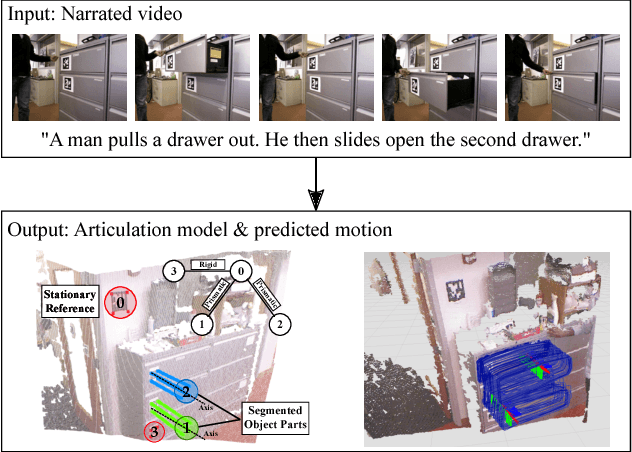
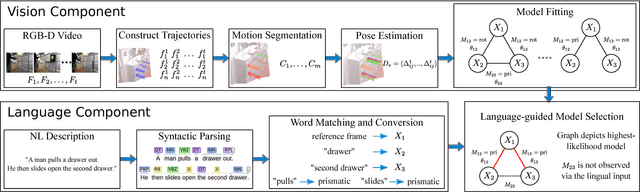
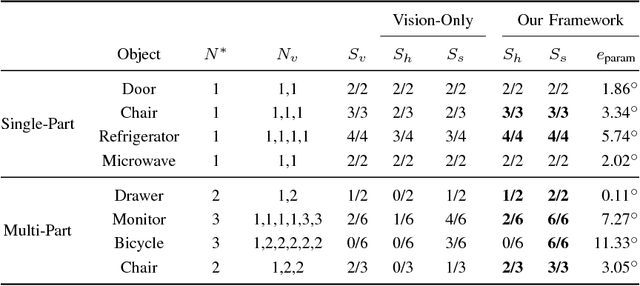
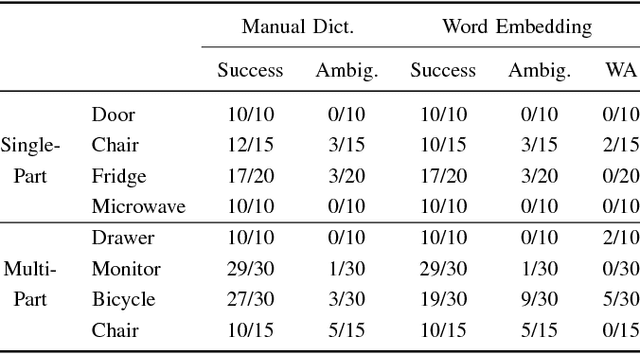
In order for robots to operate effectively in homes and workplaces, they must be able to manipulate the articulated objects common within environments built for and by humans. Previous work learns kinematic models that prescribe this manipulation from visual demonstrations. Lingual signals, such as natural language descriptions and instructions, offer a complementary means of conveying knowledge of such manipulation models and are suitable to a wide range of interactions (e.g., remote manipulation). In this paper, we present a multimodal learning framework that incorporates both visual and lingual information to estimate the structure and parameters that define kinematic models of articulated objects. The visual signal takes the form of an RGB-D image stream that opportunistically captures object motion in an unprepared scene. Accompanying natural language descriptions of the motion constitute the lingual signal. We present a probabilistic language model that uses word embeddings to associate lingual verbs with their corresponding kinematic structures. By exploiting the complementary nature of the visual and lingual input, our method infers correct kinematic structures for various multiple-part objects on which the previous state-of-the-art, visual-only system fails. We evaluate our multimodal learning framework on a dataset comprised of a variety of household objects, and demonstrate a 36% improvement in model accuracy over the vision-only baseline.