 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient endometrial carcinoma screening via cross-modal synthesis and gradient distillation
Feb 23, 2026Early detection of myometrial invasion is critical for the staging and life-saving management of endometrial carcinoma (EC), a prevalent global malignancy. Transvaginal ultrasound serves as the primary, accessible screening modality in resource-constrained primary care settings; however, its diagnostic reliability is severely hindered by low tissue contrast, high operator dependence, and a pronounced scarcity of positive pathological samples. Existing artificial intelligence solutions struggle to overcome this severe class imbalance and the subtle imaging features of invasion, particularly under the strict computational limits of primary care clinics. Here we present an automated, highly efficient two-stage deep learning framework that resolves both data and computational bottlenecks in EC screening. To mitigate pathological data scarcity, we develop a structure-guided cross-modal generation network that synthesizes diverse, high-fidelity ultrasound images from unpaired magnetic resonance imaging (MRI) data, strictly preserving clinically essential anatomical junctions. Furthermore, we introduce a lightweight screening network utilizing gradient distillation, which transfers discriminative knowledge from a high-capacity teacher model to dynamically guide sparse attention towards task-critical regions. Evaluated on a large, multicenter cohort of 7,951 participants, our model achieves a sensitivity of 99.5\%, a specificity of 97.2\%, and an area under the curve of 0.987 at a minimal computational cost (0.289 GFLOPs), substantially outperforming the average diagnostic accuracy of expert sonographers. Our approach demonstrates that combining cross-modal synthetic augmentation with knowledge-driven efficient modeling can democratize expert-level, real-time cancer screening for resource-constrained primary care settings.
RTR: A Transformer-Based Lossless Crossover with Perfect Phase Alignment
Sep 10, 2025This paper proposes a transformer-based lossless crossover method, termed Resonant Transformer Router (RTR), which achieves frequency separation while ensuring perfect phase alignment between low-frequency (LF) and high-frequency (HF) channels at the crossover frequency. The core property of RTR is that its frequency responses satisfy a linear complementary relation HLF(f)+HHF(f)=1. so that the original signal can be perfectly reconstructed by linear summation of the two channels. Theoretical derivation and circuit simulations demonstrate that RTR provides superior energy efficiency, phase consistency, and robustness against component tolerances. Compared with conventional LC crossovers and digital FIR/IIR filters, RTR offers a low-loss, low-latency hardware-assisted filtering solution suitable for high-fidelity audio and communication front-ends. The core theory behind this paper's work, lossless crossover, is based on a Chinese patent [CN116318117A] developed from the previous research of one of the authors, Jianluan Li. We provide a comprehensive experimental validation of this theory and propose a new extension.
Large Language Models Transform Organic Synthesis From Reaction Prediction to Automation
Aug 07, 2025Large language models (LLMs) are beginning to reshape how chemists plan and run reactions in organic synthesis. Trained on millions of reported transformations, these text-based models can propose synthetic routes, forecast reaction outcomes and even instruct robots that execute experiments without human supervision. Here we survey the milestones that turned LLMs from speculative tools into practical lab partners. We show how coupling LLMs with graph neural networks, quantum calculations and real-time spectroscopy shrinks discovery cycles and supports greener, data-driven chemistry. We discuss limitations, including biased datasets, opaque reasoning and the need for safety gates that prevent unintentional hazards. Finally, we outline community initiatives open benchmarks, federated learning and explainable interfaces that aim to democratize access while keeping humans firmly in control. These advances chart a path towards rapid, reliable and inclusive molecular innovation powered by artificial intelligence and automation.
IterComp: Iterative Composition-Aware Feedback Learning from Model Gallery for Text-to-Image Generation
Oct 09, 2024

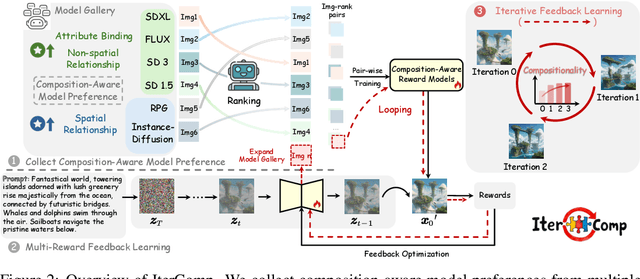
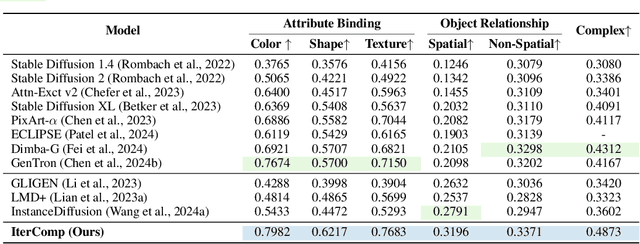
Advanced diffusion models like RPG, Stable Diffusion 3 and FLUX have made notable strides in compositional text-to-image generation. However, these methods typically exhibit distinct strengths for compositional generation, with some excelling in handling attribute binding and others in spatial relationships. This disparity highlights the need for an approach that can leverage the complementary strengths of various models to comprehensively improve the composition capability. To this end, we introduce IterComp, a novel framework that aggregates composition-aware model preferences from multiple models and employs an iterative feedback learning approach to enhance compositional generation. Specifically, we curate a gallery of six powerful open-source diffusion models and evaluate their three key compositional metrics: attribute binding, spatial relationships, and non-spatial relationships. Based on these metrics, we develop a composition-aware model preference dataset comprising numerous image-rank pairs to train composition-aware reward models. Then, we propose an iterative feedback learning method to enhance compositionality in a closed-loop manner, enabling the progressive self-refinement of both the base diffusion model and reward models over multiple iterations. Theoretical proof demonstrates the effectiveness and extensive experiments show our significant superiority over previous SOTA methods (e.g., Omost and FLUX), particularly in multi-category object composition and complex semantic alignment. IterComp opens new research avenues in reward feedback learning for diffusion models and compositional generation. Code: https://github.com/YangLing0818/IterComp
RealCompo: Dynamic Equilibrium between Realism and Compositionality Improves Text-to-Image Diffusion Models
Feb 20, 2024
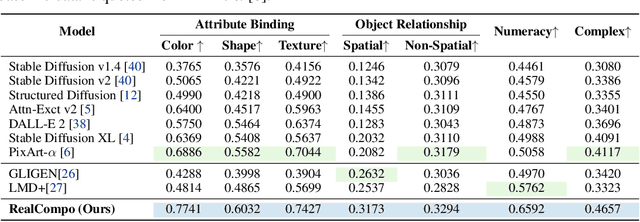
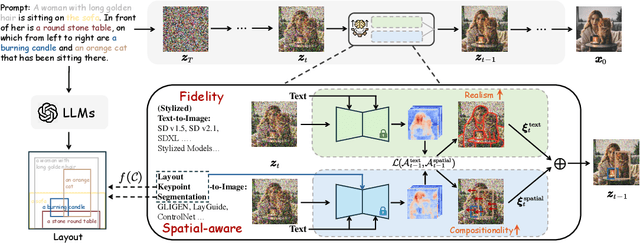
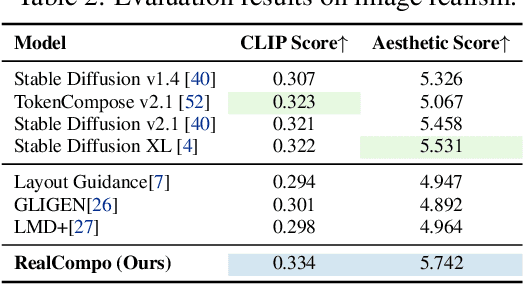
Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose a new training-free and transferred-friendly text-to-image generation framework, namely RealCompo, which aims to leverage the advantages of text-to-image and layout-to-image models to enhance both realism and compositionality of the generated images. An intuitive and novel balancer is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and layout-to-image models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Code is available at https://github.com/YangLing0818/RealCompo
AllSpark: a multimodal spatiotemporal general model
Dec 31, 2023



For a long time, due to the high heterogeneity in structure and semantics among various spatiotemporal modal data, the joint interpretation of multimodal spatiotemporal data has been an extremely challenging problem. The primary challenge resides in striking a trade-off between the cohesion and autonomy of diverse modalities, and this trade-off exhibits a progressively nonlinear nature as the number of modalities expands. We introduce the Language as Reference Framework (LaRF), a fundamental principle for constructing a multimodal unified model, aiming to strike a trade-off between the cohesion and autonomy among different modalities. We propose a multimodal spatiotemporal general artificial intelligence model, called AllSpark. Our model integrates thirteen different modalities into a unified framework, including 1D (text, code), 2D (RGB, infrared, SAR, multispectral, hyperspectral, tables, graphs, trajectory, oblique photography), and 3D (point clouds, videos) modalities. To achieve modal cohesion, AllSpark uniformly maps diverse modal features to the language modality. In addition, we design modality-specific prompts to guide multi-modal large language models in accurately perceiving multimodal data. To maintain modality autonomy, AllSpark introduces modality-specific encoders to extract the tokens of various spatiotemporal modalities. And modal bridge is employed to achieve dimensional projection from each modality to the language modality. Finally, observing a gap between the model's interpretation and downstream tasks, we designed task heads to enhance the model's generalization capability on specific downstream tasks. Experiments indicate that AllSpark achieves competitive accuracy in modalities such as RGB and trajectory compared to state-of-the-art models.
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022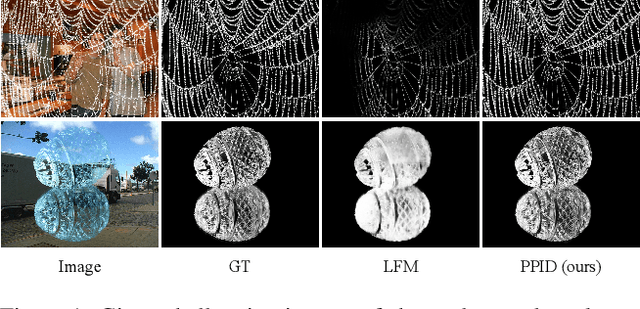

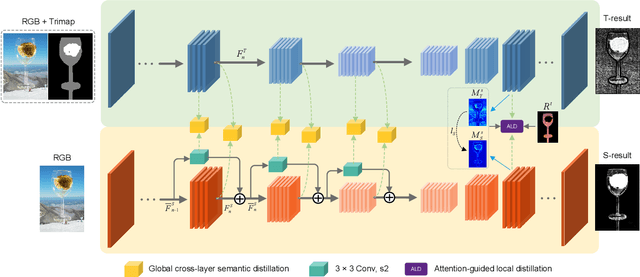
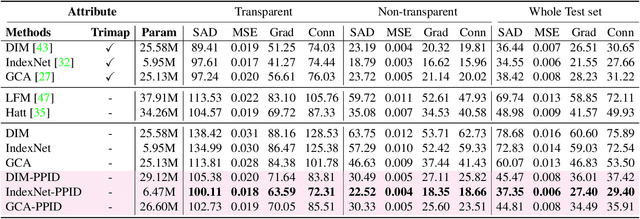
Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
Label Mask AutoEncoder(L-MAE): A Pure Transformer Method to Augment Semantic Segmentation Datasets
Nov 21, 2022



Semantic segmentation models based on the conventional neural network can achieve remarkable performance in such tasks, while the dataset is crucial to the training model process. Significant progress in expanding datasets has been made in semi-supervised semantic segmentation recently. However, completing the pixel-level information remains challenging due to possible missing in a label. Inspired by Mask AutoEncoder, we present a simple yet effective Pixel-Level completion method, Label Mask AutoEncoder(L-MAE), that fully uses the existing information in the label to predict results. The proposed model adopts the fusion strategy that stacks the label and the corresponding image, namely Fuse Map. Moreover, since some of the image information is lost when masking the Fuse Map, direct reconstruction may lead to poor performance. Our proposed Image Patch Supplement algorithm can supplement the missing information, as the experiment shows, an average of 4.1% mIoU can be improved. The Pascal VOC2012 dataset (224 crop size, 20 classes) and the Cityscape dataset (448 crop size, 19 classes) are used in the comparative experiments. With the Mask Ratio setting to 50%, in terms of the prediction region, the proposed model achieves 91.0% and 86.4% of mIoU on Pascal VOC 2012 and Cityscape, respectively, outperforming other current supervised semantic segmentation models. Our code and models are available at https://github.com/jjrccop/Label-Mask-Auto-Encoder.
Efficient Multi-view Clustering via Unified and Discrete Bipartite Graph Learning
Sep 09, 2022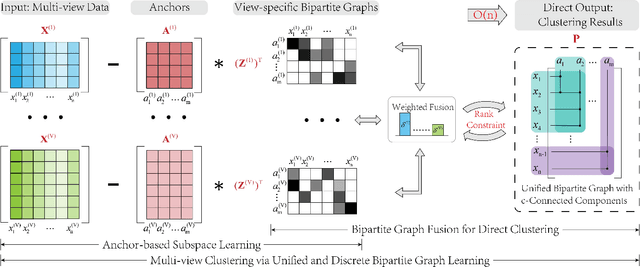

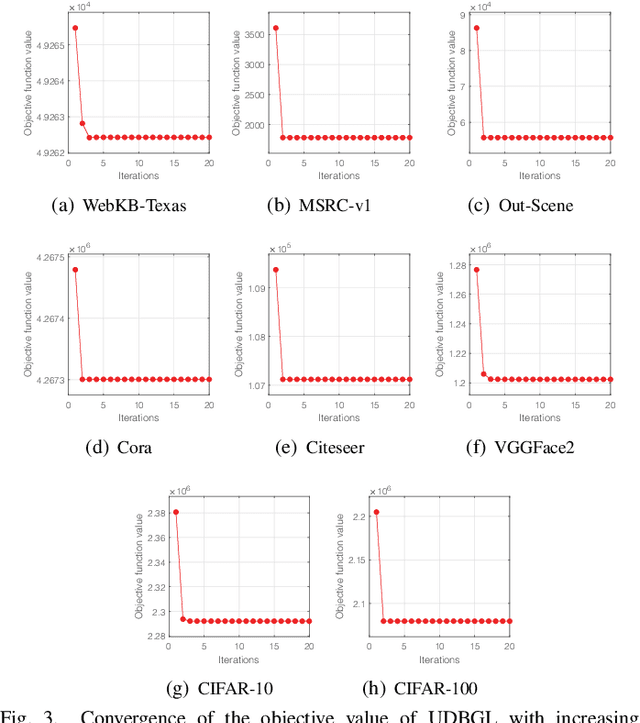
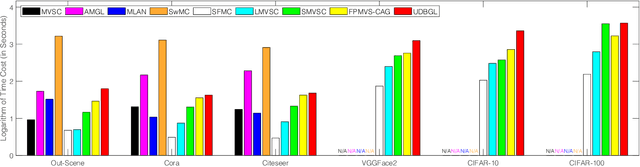
Although previous graph-based multi-view clustering algorithms have gained significant progress, most of them are still faced with three limitations. First, they often suffer from high computational complexity, which restricts their applications in large-scale scenarios. Second, they usually perform graph learning either at the single-view level or at the view-consensus level, but often neglect the possibility of the joint learning of single-view and consensus graphs. Third, many of them rely on the $k$-means for discretization of the spectral embeddings, which lack the ability to directly learn the graph with discrete cluster structure. In light of this, this paper presents an efficient multi-view clustering approach via unified and discrete bipartite graph learning (UDBGL). Specifically, the anchor-based subspace learning is incorporated to learn the view-specific bipartite graphs from multiple views, upon which the bipartite graph fusion is leveraged to learn a view-consensus bipartite graph with adaptive weight learning. Further, the Laplacian rank constraint is imposed to ensure that the fused bipartite graph has discrete cluster structures (with a specific number of connected components). By simultaneously formulating the view-specific bipartite graph learning, the view-consensus bipartite graph learning, and the discrete cluster structure learning into a unified objective function, an efficient minimization algorithm is then designed to tackle this optimization problem and directly achieve a discrete clustering solution without requiring additional partitioning, which notably has linear time complexity in data size. Experiments on a variety of multi-view datasets demonstrate the robustness and efficiency of our UDBGL approach.
Situational Perception Guided Image Matting
Apr 22, 2022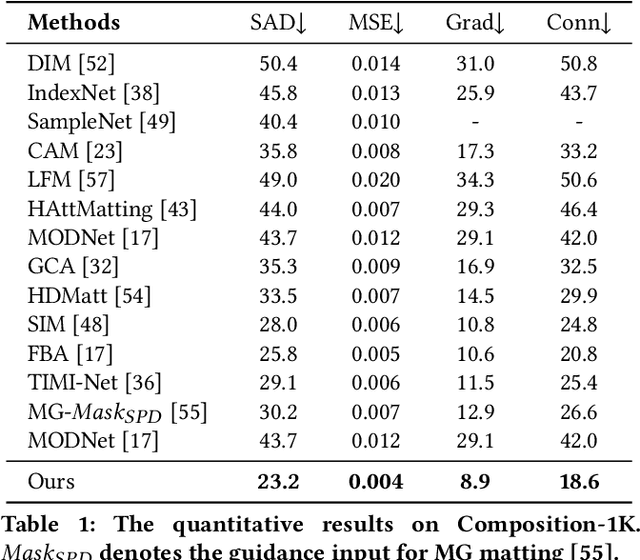
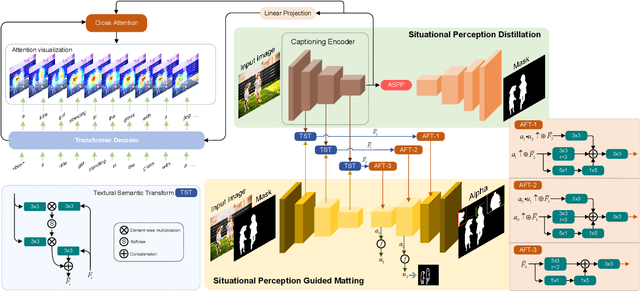
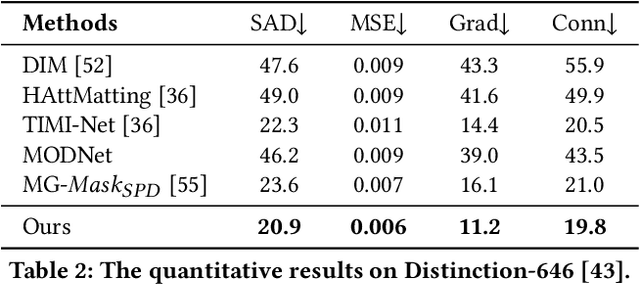
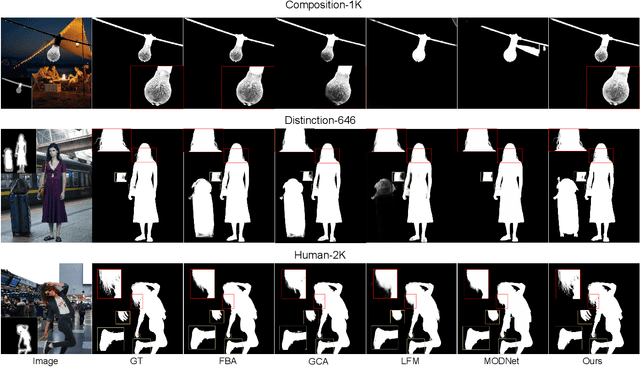
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.