 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterComp: Iterative Composition-Aware Feedback Learning from Model Gallery for Text-to-Image Generation
Oct 09, 2024

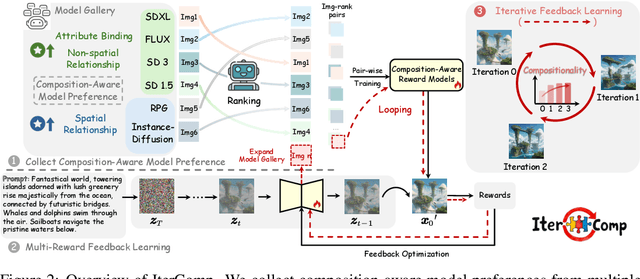
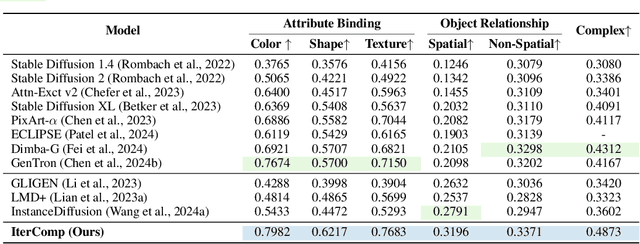
Advanced diffusion models like RPG, Stable Diffusion 3 and FLUX have made notable strides in compositional text-to-image generation. However, these methods typically exhibit distinct strengths for compositional generation, with some excelling in handling attribute binding and others in spatial relationships. This disparity highlights the need for an approach that can leverage the complementary strengths of various models to comprehensively improve the composition capability. To this end, we introduce IterComp, a novel framework that aggregates composition-aware model preferences from multiple models and employs an iterative feedback learning approach to enhance compositional generation. Specifically, we curate a gallery of six powerful open-source diffusion models and evaluate their three key compositional metrics: attribute binding, spatial relationships, and non-spatial relationships. Based on these metrics, we develop a composition-aware model preference dataset comprising numerous image-rank pairs to train composition-aware reward models. Then, we propose an iterative feedback learning method to enhance compositionality in a closed-loop manner, enabling the progressive self-refinement of both the base diffusion model and reward models over multiple iterations. Theoretical proof demonstrates the effectiveness and extensive experiments show our significant superiority over previous SOTA methods (e.g., Omost and FLUX), particularly in multi-category object composition and complex semantic alignment. IterComp opens new research avenues in reward feedback learning for diffusion models and compositional generation. Code: https://github.com/YangLing0818/IterComp
RealCompo: Dynamic Equilibrium between Realism and Compositionality Improves Text-to-Image Diffusion Models
Feb 20, 2024
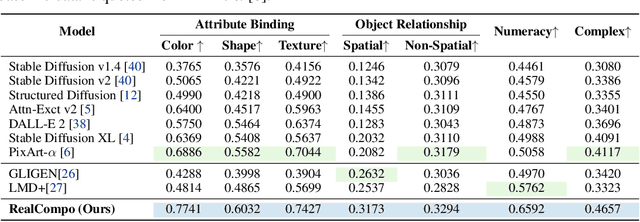
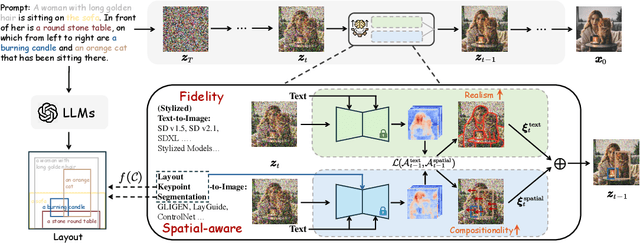
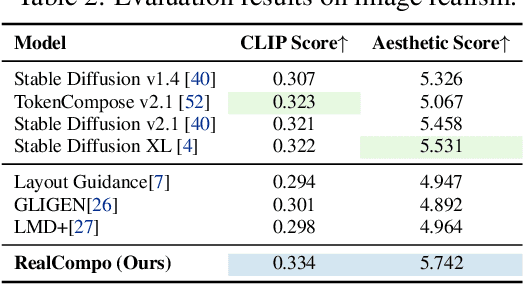
Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose a new training-free and transferred-friendly text-to-image generation framework, namely RealCompo, which aims to leverage the advantages of text-to-image and layout-to-image models to enhance both realism and compositionality of the generated images. An intuitive and novel balancer is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and layout-to-image models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Code is available at https://github.com/YangLing0818/RealCompo
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022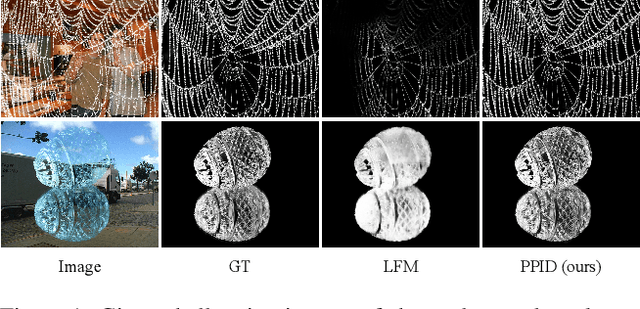

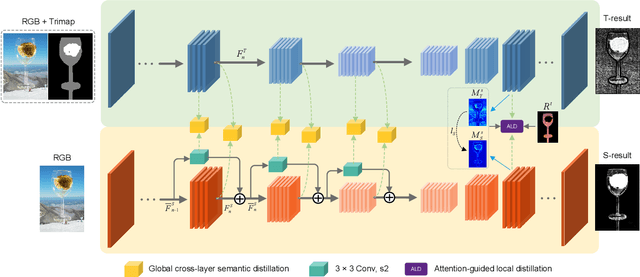
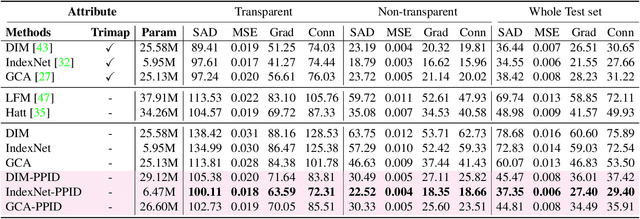
Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
Label Mask AutoEncoder(L-MAE): A Pure Transformer Method to Augment Semantic Segmentation Datasets
Nov 21, 2022



Semantic segmentation models based on the conventional neural network can achieve remarkable performance in such tasks, while the dataset is crucial to the training model process. Significant progress in expanding datasets has been made in semi-supervised semantic segmentation recently. However, completing the pixel-level information remains challenging due to possible missing in a label. Inspired by Mask AutoEncoder, we present a simple yet effective Pixel-Level completion method, Label Mask AutoEncoder(L-MAE), that fully uses the existing information in the label to predict results. The proposed model adopts the fusion strategy that stacks the label and the corresponding image, namely Fuse Map. Moreover, since some of the image information is lost when masking the Fuse Map, direct reconstruction may lead to poor performance. Our proposed Image Patch Supplement algorithm can supplement the missing information, as the experiment shows, an average of 4.1% mIoU can be improved. The Pascal VOC2012 dataset (224 crop size, 20 classes) and the Cityscape dataset (448 crop size, 19 classes) are used in the comparative experiments. With the Mask Ratio setting to 50%, in terms of the prediction region, the proposed model achieves 91.0% and 86.4% of mIoU on Pascal VOC 2012 and Cityscape, respectively, outperforming other current supervised semantic segmentation models. Our code and models are available at https://github.com/jjrccop/Label-Mask-Auto-Encoder.
Situational Perception Guided Image Matting
Apr 22, 2022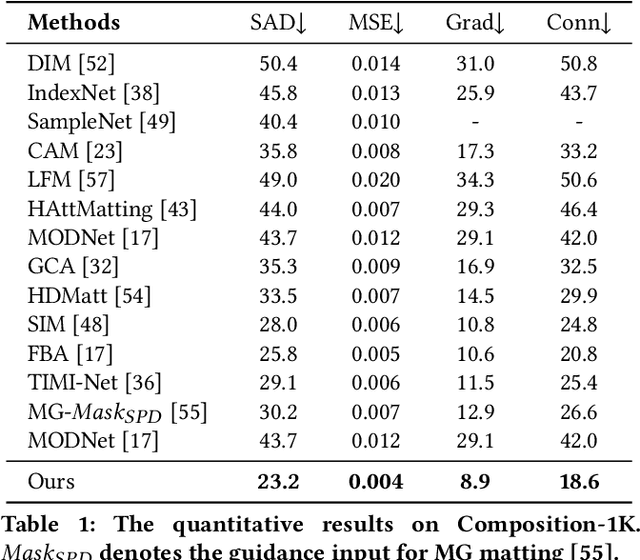
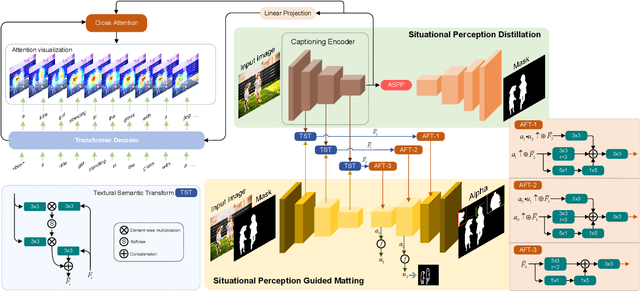
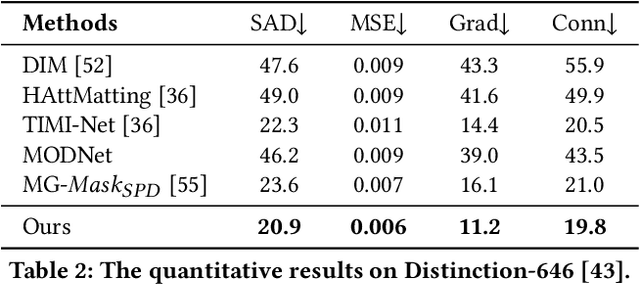
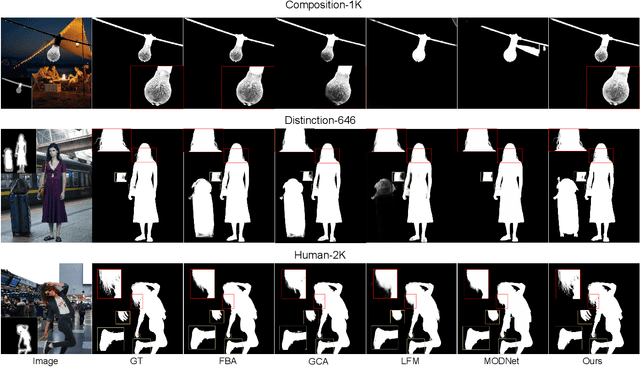
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.
Prior-Induced Information Alignment for Image Matting
Jun 28, 2021

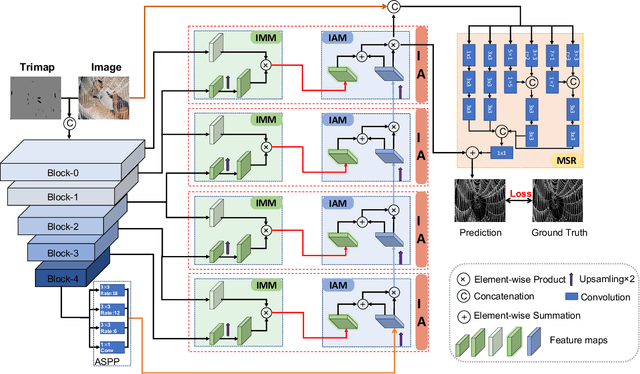
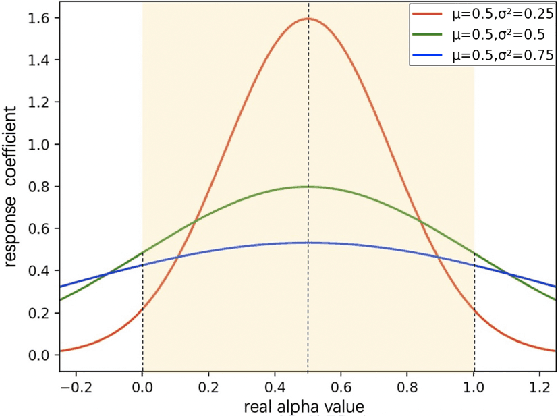
Image matting is an ill-posed problem that aims to estimate the opacity of foreground pixels in an image. However, most existing deep learning-based methods still suffer from the coarse-grained details. In general, these algorithms are incapable of felicitously distinguishing the degree of exploration between deterministic domains (certain FG and BG pixels) and undetermined domains (uncertain in-between pixels), or inevitably lose information in the continuous sampling process, leading to a sub-optimal result. In this paper, we propose a novel network named Prior-Induced Information Alignment Matting Network (PIIAMatting), which can efficiently model the distinction of pixel-wise response maps and the correlation of layer-wise feature maps. It mainly consists of a Dynamic Gaussian Modulation mechanism (DGM) and an Information Alignment strategy (IA). Specifically, the DGM can dynamically acquire a pixel-wise domain response map learned from the prior distribution. The response map can present the relationship between the opacity variation and the convergence process during training. On the other hand, the IA comprises an Information Match Module (IMM) and an Information Aggregation Module (IAM), jointly scheduled to match and aggregate the adjacent layer-wise features adaptively. Besides, we also develop a Multi-Scale Refinement (MSR) module to integrate multi-scale receptive field information at the refinement stage to recover the fluctuating appearance details. Extensive quantitative and qualitative evaluations demonstrate that the proposed PIIAMatting performs favourably against state-of-the-art image matting methods on the Alphamatting.com, Composition-1K and Distinctions-646 dataset.