 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Purchase: Building and Evaluating a Taxonomy-Decoupled Visual Search Engine for Home Goods E-commerce
Jan 16, 2026Visual search is critical for e-commerce, especially in style-driven domains where user intent is subjective and open-ended. Existing industrial systems typically couple object detection with taxonomy-based classification and rely on catalog data for evaluation, which is prone to noise that limits robustness and scalability. We propose a taxonomy-decoupled architecture that uses classification-free region proposals and unified embeddings for similarity retrieval, enabling a more flexible and generalizable visual search. To overcome the evaluation bottleneck, we propose an LLM-as-a-Judge framework that assesses nuanced visual similarity and category relevance for query-result pairs in a zero-shot manner, removing dependence on human annotations or noise-prone catalog data. Deployed at scale on a global home goods platform, our system improves retrieval quality and yields a measurable uplift in customer engagement, while our offline evaluation metrics strongly correlate with real-world outcomes.
Reinforcement Learning-based Sequential Route Recommendation for System-Optimal Traffic Assignment
May 27, 2025Modern navigation systems and shared mobility platforms increasingly rely on personalized route recommendations to improve individual travel experience and operational efficiency. However, a key question remains: can such sequential, personalized routing decisions collectively lead to system-optimal (SO) traffic assignment? This paper addresses this question by proposing a learning-based framework that reformulates the static SO traffic assignment problem as a single-agent deep reinforcement learning (RL) task. A central agent sequentially recommends routes to travelers as origin-destination (OD) demands arrive, to minimize total system travel time. To enhance learning efficiency and solution quality, we develop an MSA-guided deep Q-learning algorithm that integrates the iterative structure of traditional traffic assignment methods into the RL training process. The proposed approach is evaluated on both the Braess and Ortuzar-Willumsen (OW) networks. Results show that the RL agent converges to the theoretical SO solution in the Braess network and achieves only a 0.35% deviation in the OW network. Further ablation studies demonstrate that the route action set's design significantly impacts convergence speed and final performance, with SO-informed route sets leading to faster learning and better outcomes. This work provides a theoretically grounded and practically relevant approach to bridging individual routing behavior with system-level efficiency through learning-based sequential assignment.
AI-Driven Day-to-Day Route Choice
Dec 04, 2024



Understanding travelers' route choices can help policymakers devise optimal operational and planning strategies for both normal and abnormal circumstances. However, existing choice modeling methods often rely on predefined assumptions and struggle to capture the dynamic and adaptive nature of travel behavior. Recently, Large Language Models (LLMs) have emerged as a promising alternative, demonstrating remarkable ability to replicate human-like behaviors across various fields. Despite this potential, their capacity to accurately simulate human route choice behavior in transportation contexts remains doubtful. To satisfy this curiosity, this paper investigates the potential of LLMs for route choice modeling by introducing an LLM-empowered agent, "LLMTraveler." This agent integrates an LLM as its core, equipped with a memory system that learns from past experiences and makes decisions by balancing retrieved data and personality traits. The study systematically evaluates the LLMTraveler's ability to replicate human-like decision-making through two stages: (1) analyzing its route-switching behavior in single origin-destination (OD) pair congestion game scenarios, where it demonstrates patterns align with laboratory data but are not fully explained by traditional models, and (2) testing its capacity to model day-to-day (DTD) adaptive learning behaviors on the Ortuzar and Willumsen (OW) network, producing results comparable to Multinomial Logit (MNL) and Reinforcement Learning (RL) models. These experiments demonstrate that the framework can partially replicate human-like decision-making in route choice while providing natural language explanations for its decisions. This capability offers valuable insights for transportation policymaking, such as simulating traveler responses to new policies or changes in the network.
EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Feb 16, 2024



Despite the remarkable strides of Large Language Models (LLMs) in various fields, the wide applications of LLMs on edge devices are limited due to their massive parameters and computations. To address this, quantization is commonly adopted to generate lightweight LLMs with efficient computations and fast inference. However, Post-Training Quantization (PTQ) methods dramatically degrade in quality when quantizing weights, activations, and KV cache together to below 8 bits. Besides, many Quantization-Aware Training (QAT) works quantize model weights, leaving the activations untouched, which do not fully exploit the potential of quantization for inference acceleration on the edge. In this paper, we propose EdgeQAT, the Entropy and Distribution Guided QAT for the optimization of lightweight LLMs to achieve inference acceleration on Edge devices. We first identify that the performance drop of quantization primarily stems from the information distortion in quantized attention maps, demonstrated by the different distributions in quantized query and key of the self-attention mechanism. Then, the entropy and distribution guided QAT is proposed to mitigate the information distortion. Moreover, we design a token importance-aware adaptive method to dynamically quantize the tokens with different bit widths for further optimization and acceleration. Our extensive experiments verify the substantial improvements with our framework across various datasets. Furthermore, we achieve an on-device speedup of up to 2.37x compared with its FP16 counterparts across multiple edge devices, signaling a groundbreaking advancement.
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023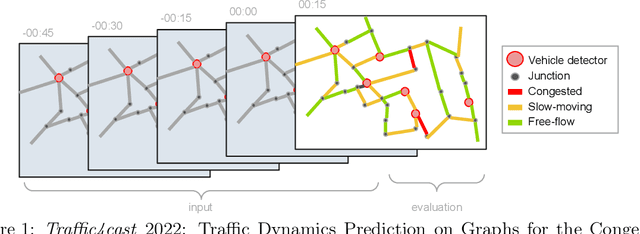
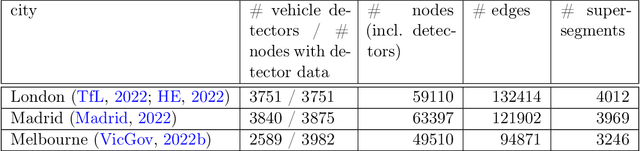
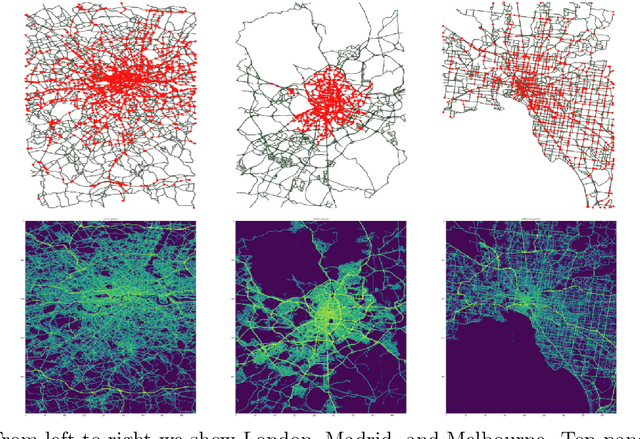
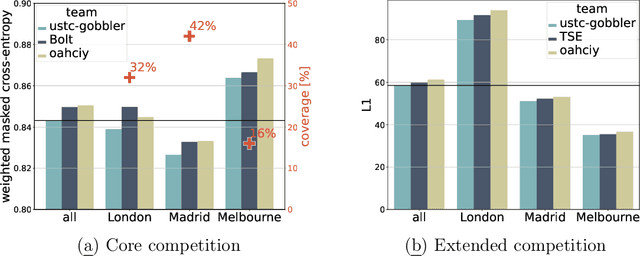
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022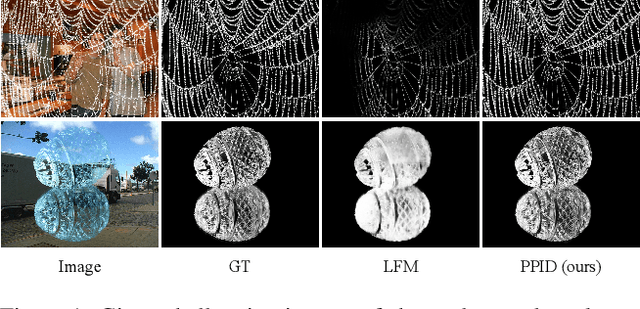

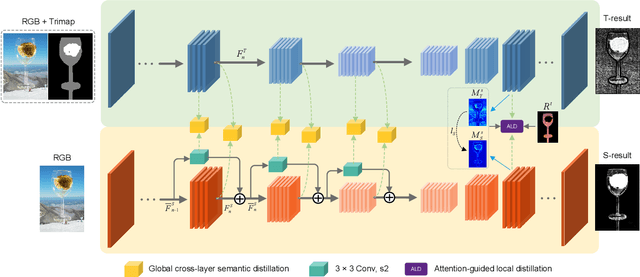
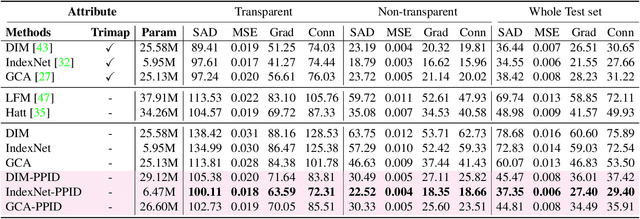
Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
Similarity-based Feature Extraction for Large-scale Sparse Traffic Forecasting
Nov 13, 2022



Short-term traffic forecasting is an extensively studied topic in the field of intelligent transportation system. However, most existing forecasting systems are limited by the requirement of real-time probe vehicle data because of their formulation as a time series forecasting problem. Towards this issue, the NeurIPS 2022 Traffic4cast challenge is dedicated to predicting the citywide traffic states with publicly available sparse loop count data. This technical report introduces our second-place winning solution to the extended challenge of ETA prediction. We present a similarity-based feature extraction method using multiple nearest neighbor (NN) filters. Similarity-based features, static features, node flow features and combined features of segments are extracted for training the gradient boosting decision tree model. Experimental results on three cities (including London, Madrid and Melbourne) demonstrate the strong predictive performance of our approach, which outperforms a number of graph-neural-network-based solutions in the task of travel time estimation. The source code is available at \url{https://github.com/c-lyu/Traffic4Cast2022-TSE}.
Efficient Meta-Tuning for Content-aware Neural Video Delivery
Jul 20, 2022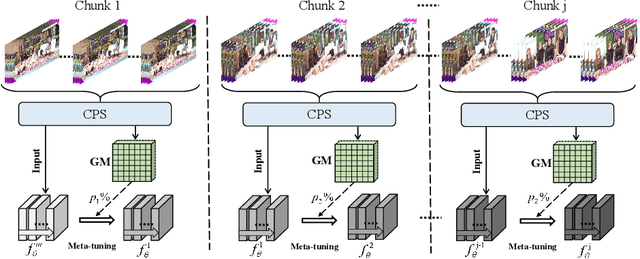
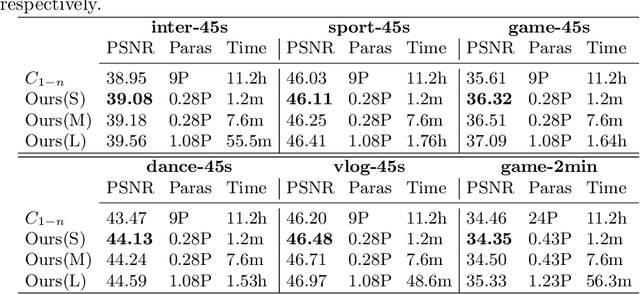
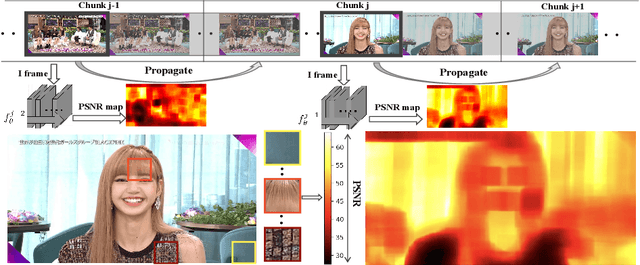
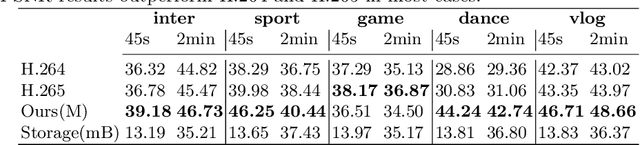
Recently, Deep Neural Networks (DNNs) are utilized to reduce the bandwidth and improve the quality of Internet video delivery. Existing methods train corresponding content-aware super-resolution (SR) model for each video chunk on the server, and stream low-resolution (LR) video chunks along with SR models to the client. Although they achieve promising results, the huge computational cost of network training limits their practical applications. In this paper, we present a method named Efficient Meta-Tuning (EMT) to reduce the computational cost. Instead of training from scratch, EMT adapts a meta-learned model to the first chunk of the input video. As for the following chunks, it fine-tunes the partial parameters selected by gradient masking of previous adapted model. In order to achieve further speedup for EMT, we propose a novel sampling strategy to extract the most challenging patches from video frames. The proposed strategy is highly efficient and brings negligible additional cost. Our method significantly reduces the computational cost and achieves even better performance, paving the way for applying neural video delivery techniques to practical applications. We conduct extensive experiments based on various efficient SR architectures, including ESPCN, SRCNN, FSRCNN and EDSR-1, demonstrating the generalization ability of our work. The code is released at \url{https://github.com/Neural-video-delivery/EMT-Pytorch-ECCV2022}.
Beyond Application End-Point Results: Quantifying Statistical Robustness of MCMC Accelerators
Mar 05, 2020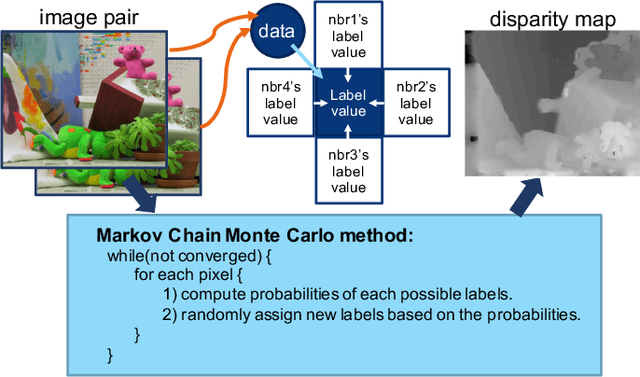
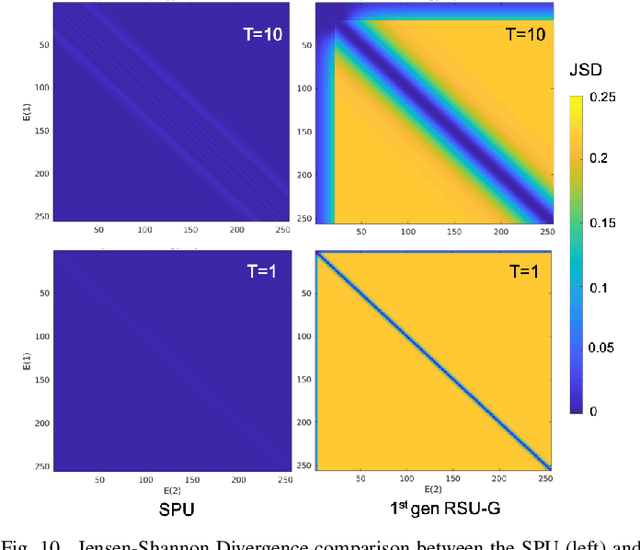
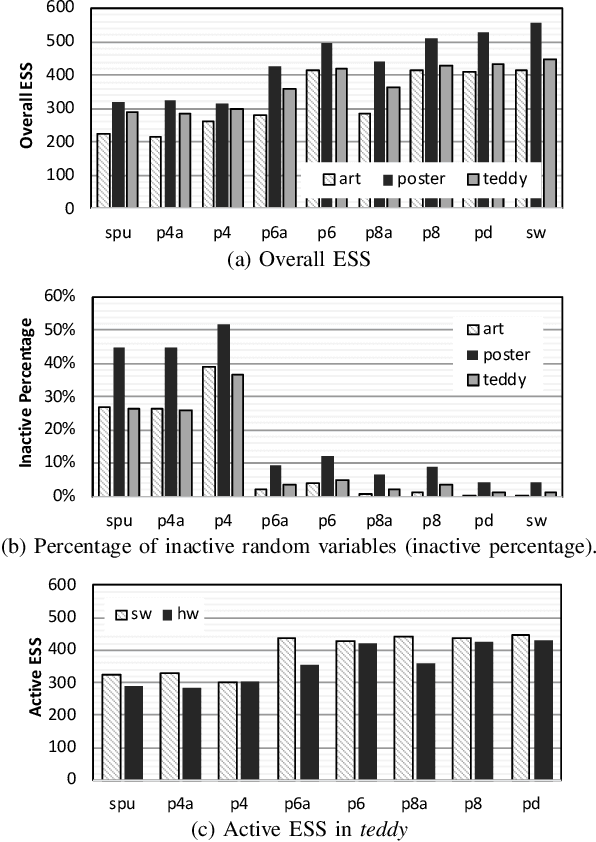
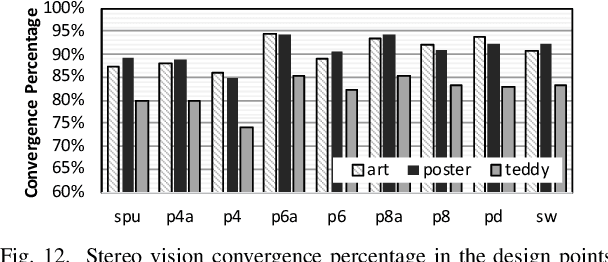
Statistical machine learning often uses probabilistic algorithms, such as Markov Chain Monte Carlo (MCMC), to solve a wide range of problems. Probabilistic computations, often considered too slow on conventional processors, can be accelerated with specialized hardware by exploiting parallelism and optimizing the design using various approximation techniques. Current methodologies for evaluating correctness of probabilistic accelerators are often incomplete, mostly focusing only on end-point result quality ("accuracy"). It is important for hardware designers and domain experts to look beyond end-point "accuracy" and be aware of the hardware optimizations impact on other statistical properties. This work takes a first step towards defining metrics and a methodology for quantitatively evaluating correctness of probabilistic accelerators beyond end-point result quality. We propose three pillars of statistical robustness: 1) sampling quality, 2) convergence diagnostic, and 3) goodness of fit. We apply our framework to a representative MCMC accelerator and surface design issues that cannot be exposed using only application end-point result quality. Applying the framework to guide design space exploration shows that statistical robustness comparable to floating-point software can be achieved by slightly increasing the bit representation, without floating-point hardware requirements.