 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023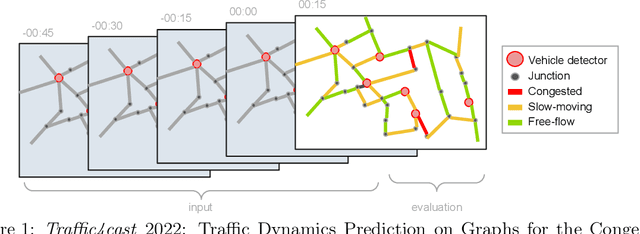
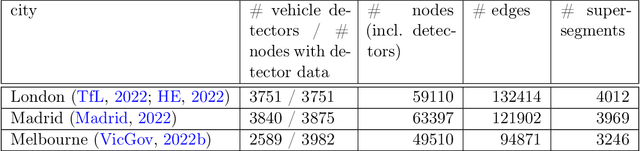
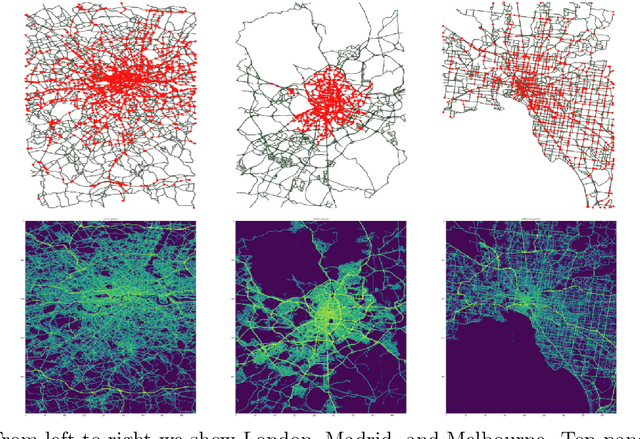
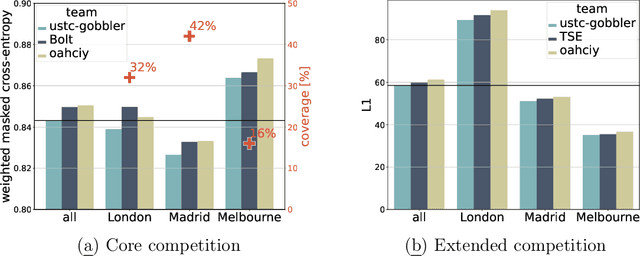
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Self-supervised learning -- A way to minimize time and effort for precision agriculture?
Apr 05, 2022
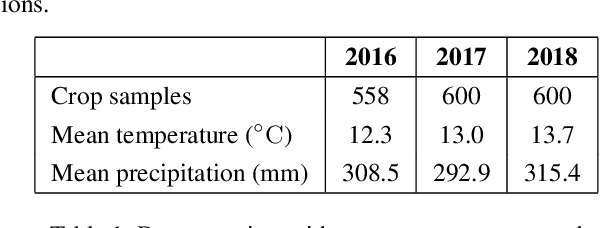
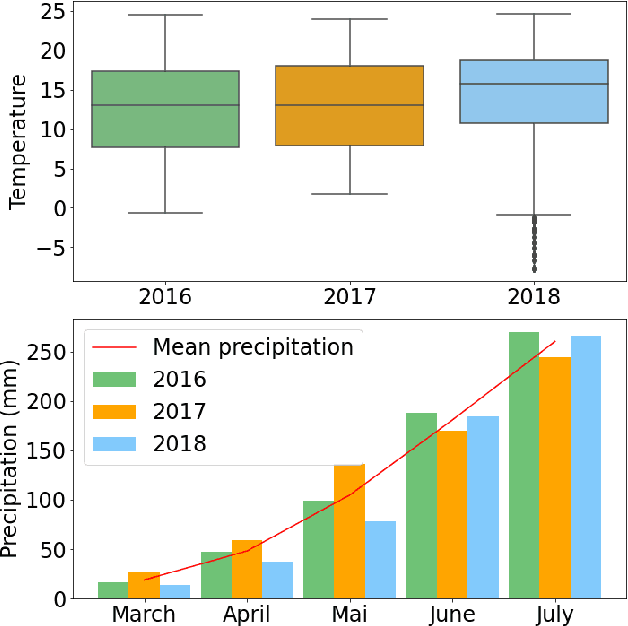
Machine learning, satellites or local sensors are key factors for a sustainable and resource-saving optimisation of agriculture and proved its values for the management of agricultural land. Up to now, the main focus was on the enlargement of data which were evaluated by means of supervised learning methods. Nevertheless, the need for labels is also a limiting and time-consuming factor, while in contrast, ongoing technological development is already providing an ever-increasing amount of unlabeled data. Self-supervised learning (SSL) could overcome this limitation and incorporate existing unlabeled data. Therefore, a crop type data set was utilized to conduct experiments with SSL and compare it to supervised methods. A unique feature of our data set from 2016 to 2018 was a divergent climatological condition in 2018 that reduced yields and affected the spectral fingerprint of the plants. Our experiments focused on predicting 2018 using SLL without or a few labels to clarify whether new labels should be collected for an unknown year. Despite these challenging conditions, the results showed that SSL contributed to higher accuracies. We believe that the results will encourage further improvements in the field of precision farming, why the SSL framework and data will be published (Marszalek, 2021).