 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Software Engineering Through Closed-Loop Memory Optimization
Jun 04, 2026Large language models (LLMs) have enabled powerful software engineering (SE) agents capable of navigating complex codebases and resolving real-world issues. However, these agents remain fundamentally episodic: they fail to retain, refine, and reuse experiences across tasks, repeatedly reconstructing context from scratch and reproducing similar mistakes. Even with memory support, they offer no remedy for the absence of a principled, task-agnostic \textit{memory utility}, making them difficult to evaluate rigorously or generalize across agents and settings. To tackle these limitations, we introduce \ours, a closed-loop framework for memory augmentation in SE agents. \ours grounds memory utility in \textit{validated downstream impact}, establishing utility as both a task-agnostic \textbf{evaluation benchmark} and an annotation-free \textbf{optimization signal}. Through complementary evaluation on \textit{single-episode} and \textit{cross-episode} memory augmentation, results demonstrate that \ours consistently improves SE agents across settings, achieving absolute gains of up to $\uparrow5.25\%$ in success rate and $\uparrow4.63\%$ in resolve efficiency, while substantially reducing computational cost by $\geq9.79\%$. Our project page: \href{https://xhguo7.github.io/MemOp/}{https://xhguo7.github.io/MemOp/}.
When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning
May 05, 2026In single-stream autoregressive interfaces, the same tokens both update the model state and constitute an irreversible public commitment. This coupling creates a \emph{silence tax}: additional deliberation postpones the first \emph{task-relevant} content, while naive early streaming risks premature commitments that bias subsequent generations. We introduce \textbf{\emph{Side-by-Side (SxS)}} Interleaved Reasoning, which makes \emph{disclosure timing} a controllable decision within standard autoregressive generation. SxS interleaves partial disclosures with continued private reasoning in the same context, but releases content only when it is \emph{supported} by the reasoning so far. To learn such pacing without incentivizing filler, we construct entailment-aligned interleaved trajectories by matching answer prefixes to supporting reasoning prefixes, then train with SFT to acquire the dual-action semantics and RL to recover reasoning performance under the new format. Across two Qwen3 architectures/scales (MoE \textbf{Qwen3-30B-A3B}, dense \textbf{Qwen3-4B}) and both in-domain (AIME25) and out-of-domain (GPQA-Diamond) benchmarks, SxS improves accuracy--\emph{content-latency} Pareto trade-offs under token-level proxies (e.g., inter-update waiting).
SciDER: Scientific Data-centric End-to-end Researcher
Mar 02, 2026Automated scientific discovery with large language models is transforming the research lifecycle from ideation to experimentation, yet existing agents struggle to autonomously process raw data collected from scientific experiments. We introduce SciDER, a data-centric end-to-end system that automates the research lifecycle. Unlike traditional frameworks, our specialized agents collaboratively parse and analyze raw scientific data, generate hypotheses and experimental designs grounded in specific data characteristics, and write and execute corresponding code. Evaluation on three benchmarks shows SciDER excels in specialized data-driven scientific discovery and outperforms general-purpose agents and state-of-the-art models through its self-evolving memory and critic-led feedback loop. Distributed as a modular Python package, we also provide easy-to-use PyPI packages with a lightweight web interface to accelerate autonomous, data-driven research and aim to be accessible to all researchers and developers.
Anagent For Enhancing Scientific Table & Figure Analysis
Feb 12, 2026In scientific research, analysis requires accurately interpreting complex multimodal knowledge, integrating evidence from different sources, and drawing inferences grounded in domain-specific knowledge. However, current artificial intelligence (AI) systems struggle to consistently demonstrate such capabilities. The complexity and variability of scientific tables and figures, combined with heterogeneous structures and long-context requirements, pose fundamental obstacles to scientific table \& figure analysis. To quantify these challenges, we introduce AnaBench, a large-scale benchmark featuring $63,178$ instances from nine scientific domains, systematically categorized along seven complexity dimensions. To tackle these challenges, we propose Anagent, a multi-agent framework for enhanced scientific table \& figure analysis through four specialized agents: Planner decomposes tasks into actionable subtasks, Expert retrieves task-specific information through targeted tool execution, Solver synthesizes information to generate coherent analysis, and Critic performs iterative refinement through five-dimensional quality assessment. We further develop modular training strategies that leverage supervised finetuning and specialized reinforcement learning to optimize individual capabilities while maintaining effective collaboration. Comprehensive evaluation across 9 broad domains with 170 subdomains demonstrates that Anagent achieves substantial improvements, up to $\uparrow 13.43\%$ in training-free settings and $\uparrow 42.12\%$ with finetuning, while revealing that task-oriented reasoning and context-aware problem-solving are essential for high-quality scientific table \& figure analysis. Our project page: https://xhguo7.github.io/Anagent/.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
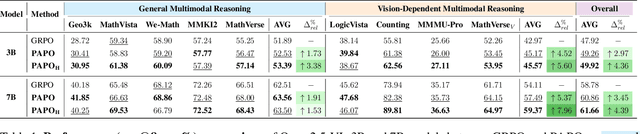
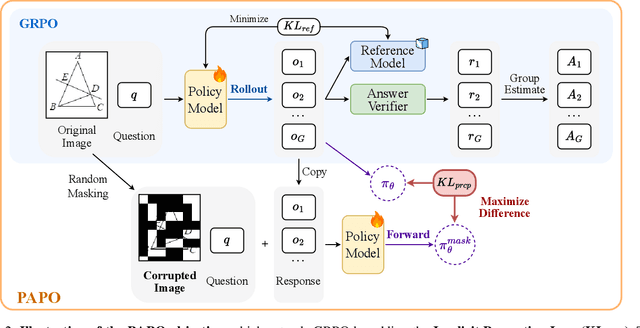
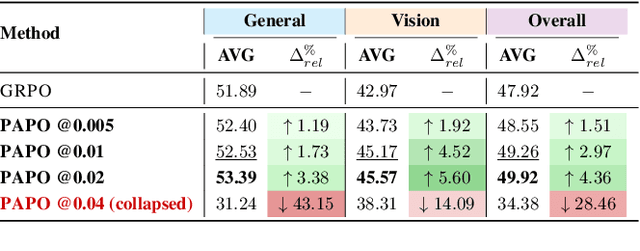
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.
SyncMind: Measuring Agent Out-of-Sync Recovery in Collaborative Software Engineering
Feb 10, 2025
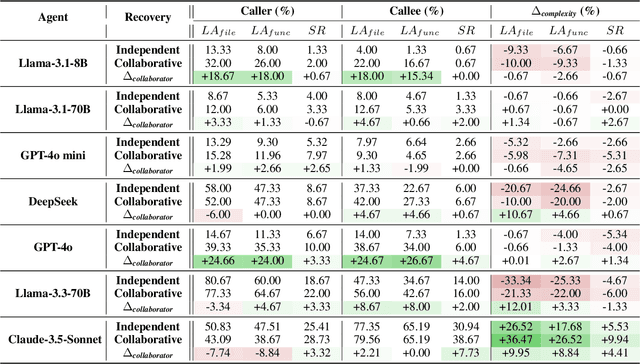


Software engineering (SE) is increasingly collaborative, with developers working together on shared complex codebases. Effective collaboration in shared environments requires participants -- whether humans or AI agents -- to stay on the same page as their environment evolves. When a collaborator's understanding diverges from the current state -- what we term the out-of-sync challenge -- the collaborator's actions may fail, leading to integration issues. In this work, we introduce SyncMind, a framework that systematically defines the out-of-sync problem faced by large language model (LLM) agents in collaborative software engineering (CSE). Based on SyncMind, we create SyncBench, a benchmark featuring 24,332 instances of agent out-of-sync scenarios in real-world CSE derived from 21 popular GitHub repositories with executable verification tests. Experiments on SyncBench uncover critical insights into existing LLM agents' capabilities and limitations. Besides substantial performance gaps among agents (from Llama-3.1 agent <= 3.33% to Claude-3.5-Sonnet >= 28.18%), their consistently low collaboration willingness (<= 4.86%) suggests fundamental limitations of existing LLM in CSE. However, when collaboration occurs, it positively correlates with out-of-sync recovery success. Minimal performance differences in agents' resource-aware out-of-sync recoveries further reveal their significant lack of resource awareness and adaptability, shedding light on future resource-efficient collaborative systems. Code and data are openly available on our project website: https://xhguo7.github.io/SyncMind/.
EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Feb 16, 2024



Despite the remarkable strides of Large Language Models (LLMs) in various fields, the wide applications of LLMs on edge devices are limited due to their massive parameters and computations. To address this, quantization is commonly adopted to generate lightweight LLMs with efficient computations and fast inference. However, Post-Training Quantization (PTQ) methods dramatically degrade in quality when quantizing weights, activations, and KV cache together to below 8 bits. Besides, many Quantization-Aware Training (QAT) works quantize model weights, leaving the activations untouched, which do not fully exploit the potential of quantization for inference acceleration on the edge. In this paper, we propose EdgeQAT, the Entropy and Distribution Guided QAT for the optimization of lightweight LLMs to achieve inference acceleration on Edge devices. We first identify that the performance drop of quantization primarily stems from the information distortion in quantized attention maps, demonstrated by the different distributions in quantized query and key of the self-attention mechanism. Then, the entropy and distribution guided QAT is proposed to mitigate the information distortion. Moreover, we design a token importance-aware adaptive method to dynamically quantize the tokens with different bit widths for further optimization and acceleration. Our extensive experiments verify the substantial improvements with our framework across various datasets. Furthermore, we achieve an on-device speedup of up to 2.37x compared with its FP16 counterparts across multiple edge devices, signaling a groundbreaking advancement.