 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Net-Like Spiking Neural Networks for Single Image Dehazing
Dec 30, 2025Image dehazing is a critical challenge in computer vision, essential for enhancing image clarity in hazy conditions. Traditional methods often rely on atmospheric scattering models, while recent deep learning techniques, specifically Convolutional Neural Networks (CNNs) and Transformers, have improved performance by effectively analyzing image features. However, CNNs struggle with long-range dependencies, and Transformers demand significant computational resources. To address these limitations, we propose DehazeSNN, an innovative architecture that integrates a U-Net-like design with Spiking Neural Networks (SNNs). DehazeSNN captures multi-scale image features while efficiently managing local and long-range dependencies. The introduction of the Orthogonal Leaky-Integrate-and-Fire Block (OLIFBlock) enhances cross-channel communication, resulting in superior dehazing performance with reduced computational burden. Our extensive experiments show that DehazeSNN is highly competitive to state-of-the-art methods on benchmark datasets, delivering high-quality haze-free images with a smaller model size and less multiply-accumulate operations. The proposed dehazing method is publicly available at https://github.com/HaoranLiu507/DehazeSNN.
* 9 pages, 4 figures. Accepted at IJCNN 2025 (Rome, Italy). To appear in IEEE/IJCNN 2025 proceedings
Behavior Tokens Speak Louder: Disentangled Explainable Recommendation with Behavior Vocabulary
Dec 17, 2025
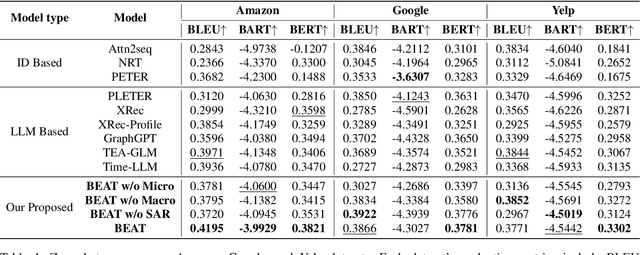


Recent advances in explainable recommendations have explored the integration of language models to analyze natural language rationales for user-item interactions. Despite their potential, existing methods often rely on ID-based representations that obscure semantic meaning and impose structural constraints on language models, thereby limiting their applicability in open-ended scenarios. These challenges are intensified by the complex nature of real-world interactions, where diverse user intents are entangled and collaborative signals rarely align with linguistic semantics. To overcome these limitations, we propose BEAT, a unified and transferable framework that tokenizes user and item behaviors into discrete, interpretable sequences. We construct a behavior vocabulary via a vector-quantized autoencoding process that disentangles macro-level interests and micro-level intentions from graph-based representations. We then introduce multi-level semantic supervision to bridge the gap between behavioral signals and language space. A semantic alignment regularization mechanism is designed to embed behavior tokens directly into the input space of frozen language models. Experiments on three public datasets show that BEAT improves zero-shot recommendation performance while generating coherent and informative explanations. Further analysis demonstrates that our behavior tokens capture fine-grained semantics and offer a plug-and-play interface for integrating complex behavior patterns into large language models.
MELDAE: A Framework for Micro-Expression Spotting, Detection, and Automatic Evaluation in In-the-Wild Conversational Scenes
Oct 26, 2025Accurately analyzing spontaneous, unconscious micro-expressions is crucial for revealing true human emotions, but this task remains challenging in wild scenarios, such as natural conversation. Existing research largely relies on datasets from controlled laboratory environments, and their performance degrades dramatically in the real world. To address this issue, we propose three contributions: the first micro-expression dataset focused on conversational-in-the-wild scenarios; an end-to-end localization and detection framework, MELDAE; and a novel boundary-aware loss function that improves temporal accuracy by penalizing onset and offset errors. Extensive experiments demonstrate that our framework achieves state-of-the-art results on the WDMD dataset, improving the key F1_{DR} localization metric by 17.72% over the strongest baseline, while also demonstrating excellent generalization capabilities on existing benchmarks.
Random-coupled Neural Network
Mar 26, 2024Improving the efficiency of current neural networks and modeling them in biological neural systems have become popular research directions in recent years. Pulse-coupled neural network (PCNN) is a well applicated model for imitating the computation characteristics of the human brain in computer vision and neural network fields. However, differences between the PCNN and biological neural systems remain: limited neural connection, high computational cost, and lack of stochastic property. In this study, random-coupled neural network (RCNN) is proposed. It overcomes these difficulties in PCNN's neuromorphic computing via a random inactivation process. This process randomly closes some neural connections in the RCNN model, realized by the random inactivation weight matrix of link input. This releases the computational burden of PCNN, making it affordable to achieve vast neural connections. Furthermore, the image and video processing mechanisms of RCNN are researched. It encodes constant stimuli as periodic spike trains and periodic stimuli as chaotic spike trains, the same as biological neural information encoding characteristics. Finally, the RCNN is applicated to image segmentation, fusion, and pulse shape discrimination subtasks. It is demonstrated to be robust, efficient, and highly anti-noised, with outstanding performance in all applications mentioned above.
PriSTI: A Conditional Diffusion Framework for Spatiotemporal Imputation
Feb 20, 2023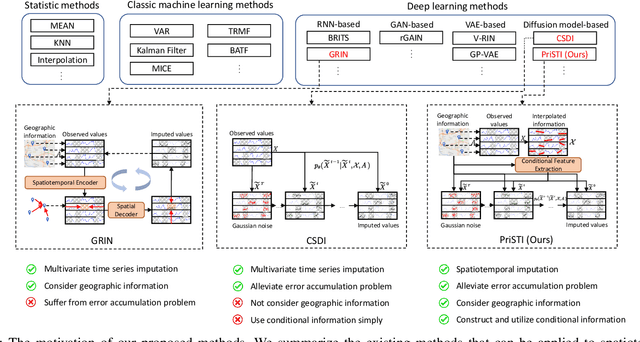
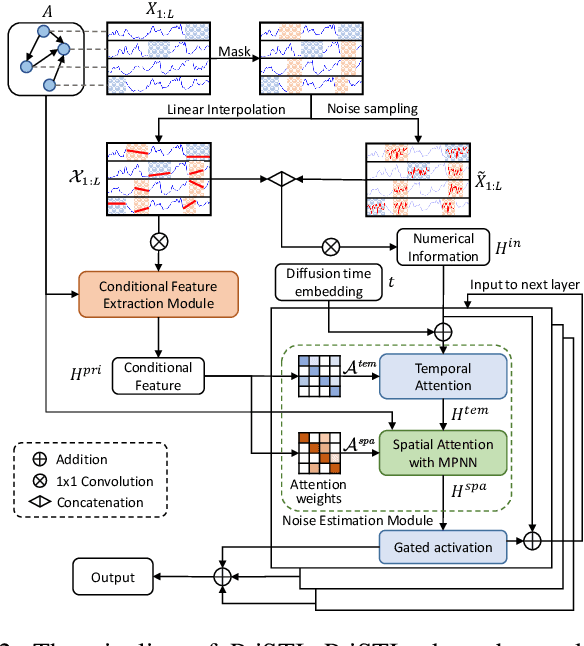
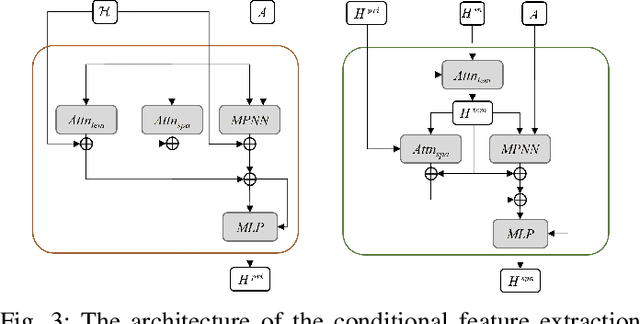
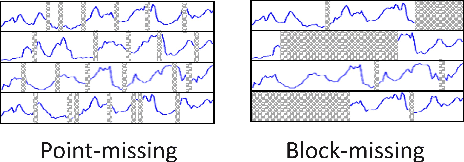
Spatiotemporal data mining plays an important role in air quality monitoring, crowd flow modeling, and climate forecasting. However, the originally collected spatiotemporal data in real-world scenarios is usually incomplete due to sensor failures or transmission loss. Spatiotemporal imputation aims to fill the missing values according to the observed values and the underlying spatiotemporal dependence of them. The previous dominant models impute missing values autoregressively and suffer from the problem of error accumulation. As emerging powerful generative models, the diffusion probabilistic models can be adopted to impute missing values conditioned by observations and avoid inferring missing values from inaccurate historical imputation. However, the construction and utilization of conditional information are inevitable challenges when applying diffusion models to spatiotemporal imputation. To address above issues, we propose a conditional diffusion framework for spatiotemporal imputation with enhanced prior modeling, named PriSTI. Our proposed framework provides a conditional feature extraction module first to extract the coarse yet effective spatiotemporal dependencies from conditional information as the global context prior. Then, a noise estimation module transforms random noise to realistic values, with the spatiotemporal attention weights calculated by the conditional feature, as well as the consideration of geographic relationships. PriSTI outperforms existing imputation methods in various missing patterns of different real-world spatiotemporal data, and effectively handles scenarios such as high missing rates and sensor failure. The implementation code is available at https://github.com/LMZZML/PriSTI.
Label Mask AutoEncoder(L-MAE): A Pure Transformer Method to Augment Semantic Segmentation Datasets
Nov 21, 2022



Semantic segmentation models based on the conventional neural network can achieve remarkable performance in such tasks, while the dataset is crucial to the training model process. Significant progress in expanding datasets has been made in semi-supervised semantic segmentation recently. However, completing the pixel-level information remains challenging due to possible missing in a label. Inspired by Mask AutoEncoder, we present a simple yet effective Pixel-Level completion method, Label Mask AutoEncoder(L-MAE), that fully uses the existing information in the label to predict results. The proposed model adopts the fusion strategy that stacks the label and the corresponding image, namely Fuse Map. Moreover, since some of the image information is lost when masking the Fuse Map, direct reconstruction may lead to poor performance. Our proposed Image Patch Supplement algorithm can supplement the missing information, as the experiment shows, an average of 4.1% mIoU can be improved. The Pascal VOC2012 dataset (224 crop size, 20 classes) and the Cityscape dataset (448 crop size, 19 classes) are used in the comparative experiments. With the Mask Ratio setting to 50%, in terms of the prediction region, the proposed model achieves 91.0% and 86.4% of mIoU on Pascal VOC 2012 and Cityscape, respectively, outperforming other current supervised semantic segmentation models. Our code and models are available at https://github.com/jjrccop/Label-Mask-Auto-Encoder.
Lifelong Property Price Prediction: A Case Study for the Toronto Real Estate Market
Aug 12, 2020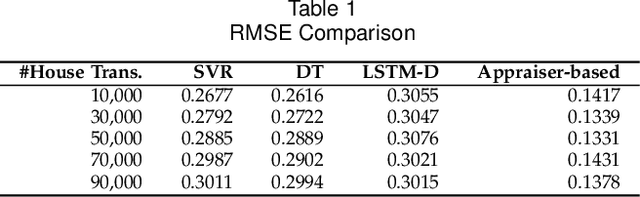
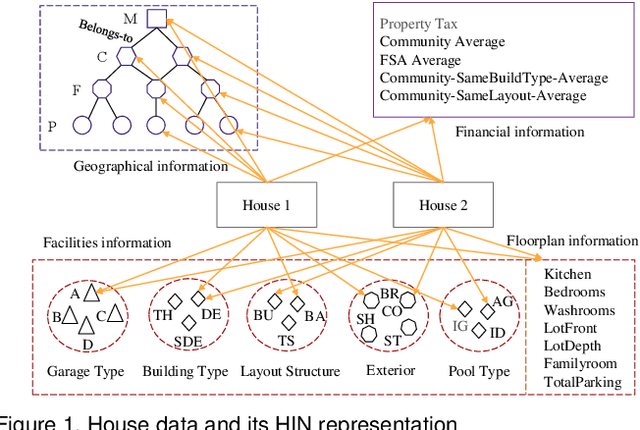

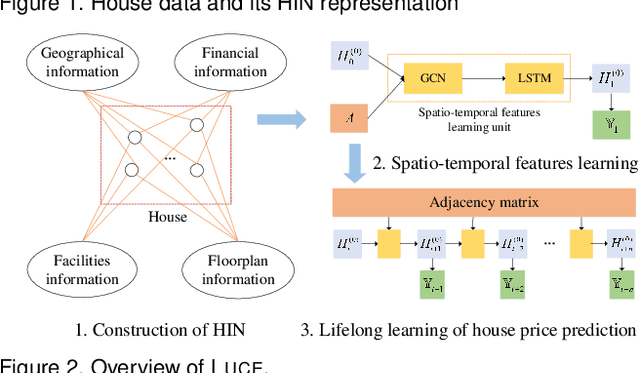
We present Luce, the first life-long predictive model for automated property valuation. Luce addresses two critical issues of property valuation: the lack of recent sold prices and the sparsity of house data. It is designed to operate on a limited volume of recent house transaction data. As a departure from prior work, Luce organizes the house data in a heterogeneous information network (HIN) where graph nodes are house entities and attributes that are important for house price valuation. We employ a Graph Convolutional Network (GCN) to extract the spatial information from the HIN for house-related data like geographical locations, and then use a Long Short Term Memory (LSTM) network to model the temporal dependencies for house transaction data over time. Unlike prior work, Luce can make effective use of the limited house transactions data in the past few months to update valuation information for all house entities within the HIN. By providing a complete and up-to-date house valuation dataset, Luce thus massively simplifies the downstream valuation task for the targeting properties. We demonstrate the benefit of Luce by applying it to large, real-life datasets obtained from the Toronto real estate market. Extensive experimental results show that Luce not only significantly outperforms prior property valuation methods but also often reaches and sometimes exceeds the valuation accuracy given by independent experts when using the actual realization price as the ground truth.