 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect to Know: An Internal-External Knowledge Self-Selection Framework for Domain-Specific Question Answering
Aug 21, 2025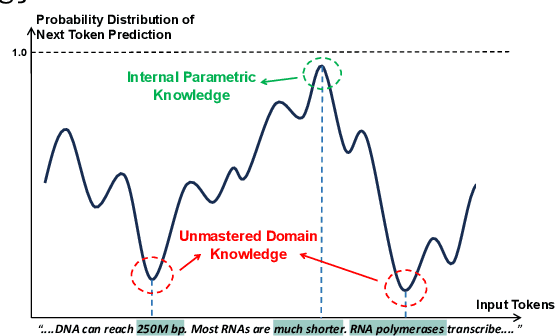
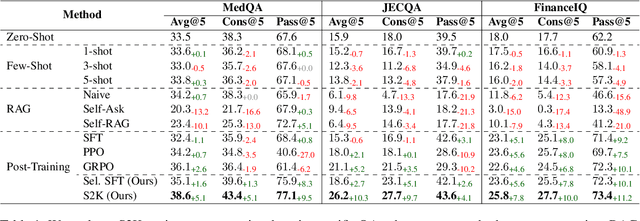
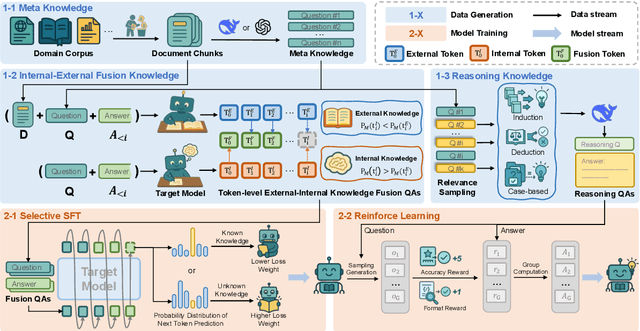

Large Language Models (LLMs) perform well in general QA but often struggle in domain-specific scenarios. Retrieval-Augmented Generation (RAG) introduces external knowledge but suffers from hallucinations and latency due to noisy retrievals. Continued pretraining internalizes domain knowledge but is costly and lacks cross-domain flexibility. We attribute this challenge to the long-tail distribution of domain knowledge, which leaves partial yet useful internal knowledge underutilized. We further argue that knowledge acquisition should be progressive, mirroring human learning: first understanding concepts, then applying them to complex reasoning. To address this, we propose Selct2Know (S2K), a cost-effective framework that internalizes domain knowledge through an internal-external knowledge self-selection strategy and selective supervised fine-tuning. We also introduce a structured reasoning data generation pipeline and integrate GRPO to enhance reasoning ability. Experiments on medical, legal, and financial QA benchmarks show that S2K consistently outperforms existing methods and matches domain-pretrained LLMs with significantly lower cost.
Homogeneous Tokenizer Matters: Homogeneous Visual Tokenizer for Remote Sensing Image Understanding
Mar 27, 2024



The tokenizer, as one of the fundamental components of large models, has long been overlooked or even misunderstood in visual tasks. One key factor of the great comprehension power of the large language model is that natural language tokenizers utilize meaningful words or subwords as the basic elements of language. In contrast, mainstream visual tokenizers, represented by patch-based methods such as Patch Embed, rely on meaningless rectangular patches as basic elements of vision, which cannot serve as effectively as words or subwords in language. Starting from the essence of the tokenizer, we defined semantically independent regions (SIRs) for vision. We designed a simple HOmogeneous visual tOKenizer: HOOK. HOOK mainly consists of two modules: the Object Perception Module (OPM) and the Object Vectorization Module (OVM). To achieve homogeneity, the OPM splits the image into 4*4 pixel seeds and then utilizes the attention mechanism to perceive SIRs. The OVM employs cross-attention to merge seeds within the same SIR. To achieve adaptability, the OVM defines a variable number of learnable vectors as cross-attention queries, allowing for the adjustment of token quantity. We conducted experiments on the NWPU-RESISC45, WHU-RS19 classification dataset, and GID5 segmentation dataset for sparse and dense tasks. The results demonstrate that the visual tokens obtained by HOOK correspond to individual objects, which demonstrates homogeneity. HOOK outperformed Patch Embed by 6\% and 10\% in the two tasks and achieved state-of-the-art performance compared to the baselines used for comparison. Compared to Patch Embed, which requires more than one hundred tokens for one image, HOOK requires only 6 and 8 tokens for sparse and dense tasks, respectively, resulting in efficiency improvements of 1.5 to 2.8 times. The code is available at https://github.com/GeoX-Lab/Hook.
AllSpark: a multimodal spatiotemporal general model
Dec 31, 2023



For a long time, due to the high heterogeneity in structure and semantics among various spatiotemporal modal data, the joint interpretation of multimodal spatiotemporal data has been an extremely challenging problem. The primary challenge resides in striking a trade-off between the cohesion and autonomy of diverse modalities, and this trade-off exhibits a progressively nonlinear nature as the number of modalities expands. We introduce the Language as Reference Framework (LaRF), a fundamental principle for constructing a multimodal unified model, aiming to strike a trade-off between the cohesion and autonomy among different modalities. We propose a multimodal spatiotemporal general artificial intelligence model, called AllSpark. Our model integrates thirteen different modalities into a unified framework, including 1D (text, code), 2D (RGB, infrared, SAR, multispectral, hyperspectral, tables, graphs, trajectory, oblique photography), and 3D (point clouds, videos) modalities. To achieve modal cohesion, AllSpark uniformly maps diverse modal features to the language modality. In addition, we design modality-specific prompts to guide multi-modal large language models in accurately perceiving multimodal data. To maintain modality autonomy, AllSpark introduces modality-specific encoders to extract the tokens of various spatiotemporal modalities. And modal bridge is employed to achieve dimensional projection from each modality to the language modality. Finally, observing a gap between the model's interpretation and downstream tasks, we designed task heads to enhance the model's generalization capability on specific downstream tasks. Experiments indicate that AllSpark achieves competitive accuracy in modalities such as RGB and trajectory compared to state-of-the-art models.