 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomogeneous Tokenizer Matters: Homogeneous Visual Tokenizer for Remote Sensing Image Understanding
Mar 27, 2024



The tokenizer, as one of the fundamental components of large models, has long been overlooked or even misunderstood in visual tasks. One key factor of the great comprehension power of the large language model is that natural language tokenizers utilize meaningful words or subwords as the basic elements of language. In contrast, mainstream visual tokenizers, represented by patch-based methods such as Patch Embed, rely on meaningless rectangular patches as basic elements of vision, which cannot serve as effectively as words or subwords in language. Starting from the essence of the tokenizer, we defined semantically independent regions (SIRs) for vision. We designed a simple HOmogeneous visual tOKenizer: HOOK. HOOK mainly consists of two modules: the Object Perception Module (OPM) and the Object Vectorization Module (OVM). To achieve homogeneity, the OPM splits the image into 4*4 pixel seeds and then utilizes the attention mechanism to perceive SIRs. The OVM employs cross-attention to merge seeds within the same SIR. To achieve adaptability, the OVM defines a variable number of learnable vectors as cross-attention queries, allowing for the adjustment of token quantity. We conducted experiments on the NWPU-RESISC45, WHU-RS19 classification dataset, and GID5 segmentation dataset for sparse and dense tasks. The results demonstrate that the visual tokens obtained by HOOK correspond to individual objects, which demonstrates homogeneity. HOOK outperformed Patch Embed by 6\% and 10\% in the two tasks and achieved state-of-the-art performance compared to the baselines used for comparison. Compared to Patch Embed, which requires more than one hundred tokens for one image, HOOK requires only 6 and 8 tokens for sparse and dense tasks, respectively, resulting in efficiency improvements of 1.5 to 2.8 times. The code is available at https://github.com/GeoX-Lab/Hook.
AI Empowered Channel Semantic Acquisition for 6G Integrated Sensing and Communication Networks
Jan 17, 2024
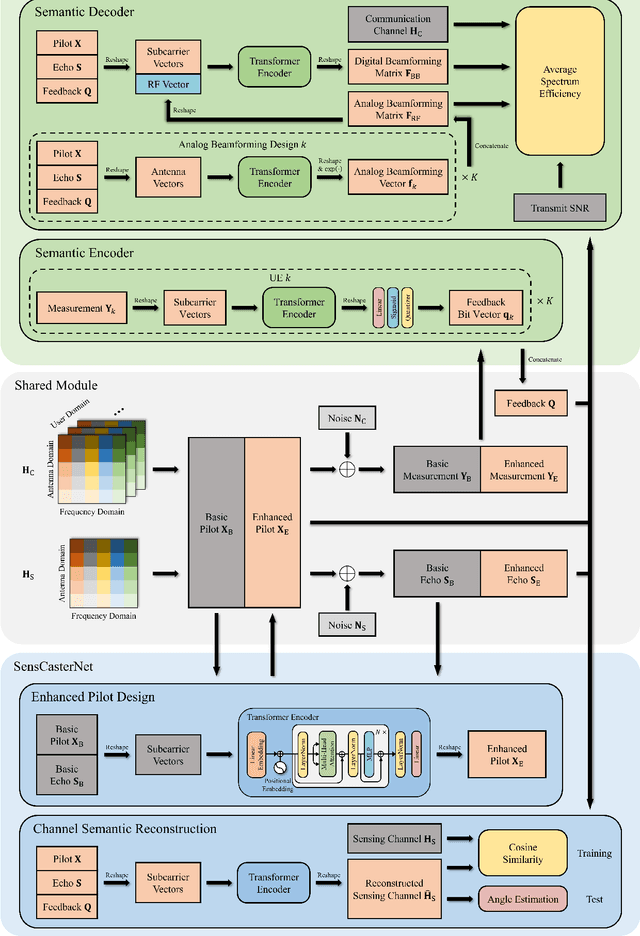
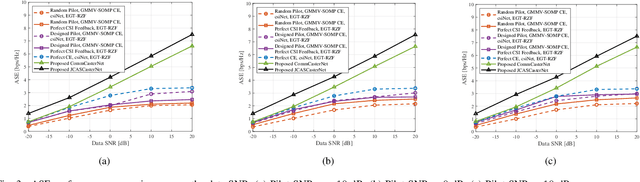

Motivated by the need for increased spectral efficiency and the proliferation of intelligent applications, the sixth-generation (6G) mobile network is anticipated to integrate the dual-functions of communication and sensing (C&S). Although the millimeter wave (mmWave) communication and mmWave radar share similar multiple-input multiple-output (MIMO) architecture for integration, the full potential of dual-function synergy remains to be exploited. In this paper, we commence by overviewing state-of-the-art schemes from the aspects of waveform design and signal processing. Nevertheless, these approaches face the dilemma of mutual compromise between C&S performance. To this end, we reveal and exploit the synergy between C&S. In the proposed framework, we introduce a two-stage frame structure and resort artificial intelligence (AI) to achieve the synergistic gain by designing a joint C&S channel semantic extraction and reconstruction network (JCASCasterNet). With just a cost-effective and energy-efficient single sensing antenna, the proposed scheme achieves enhanced overall performance while requiring only limited pilot and feedback signaling overhead. In the end, we outline the challenges that lie ahead in the future development of integrated sensing and communication networks, along with promising directions for further research.
Uncertainty Quantification using Generative Approach
Oct 13, 2023We present the Incremental Generative Monte Carlo (IGMC) method, designed to measure uncertainty in deep neural networks using deep generative approaches. IGMC iteratively trains generative models, adding their output to the dataset, to compute the posterior distribution of the expectation of a random variable. We provide a theoretical guarantee of the convergence rate of IGMC relative to the sample size and sampling depth. Due to its compatibility with deep generative approaches, IGMC is adaptable to both neural network classification and regression tasks. We empirically study the behavior of IGMC on the MNIST digit classification task.
Foundation Reinforcement Learning: towards Embodied Generalist Agents with Foundation Prior Assistance
Oct 10, 2023



Recently, people have shown that large-scale pre-training from internet-scale data is the key to building generalist models, as witnessed in NLP. To build embodied generalist agents, we and many other researchers hypothesize that such foundation prior is also an indispensable component. However, it is unclear what is the proper concrete form to represent those embodied foundation priors and how they should be used in the downstream task. In this paper, we propose an intuitive and effective set of embodied priors that consist of foundation policy, value, and success reward. The proposed priors are based on the goal-conditioned MDP. To verify their effectiveness, we instantiate an actor-critic method assisted by the priors, called Foundation Actor-Critic (FAC). We name our framework as Foundation Reinforcement Learning (FRL), since it completely relies on embodied foundation priors to explore, learn and reinforce. The benefits of FRL are threefold. (1) Sample efficient. With foundation priors, FAC learns significantly faster than traditional RL. Our evaluation on the Meta-World has proved that FAC can achieve 100% success rates for 7/8 tasks under less than 200k frames, which outperforms the baseline method with careful manual-designed rewards under 1M frames. (2) Robust to noisy priors. Our method tolerates the unavoidable noise in embodied foundation models. We show that FAC works well even under heavy noise or quantization errors. (3) Minimal human intervention: FAC completely learns from the foundation priors, without the need of human-specified dense reward, or providing teleoperated demos. Thus, FAC can be easily scaled up. We believe our FRL framework could enable the future robot to autonomously explore and learn without human intervention in the physical world. In summary, our proposed FRL is a novel and powerful learning paradigm, towards achieving embodied generalist agents.
GraSS: Contrastive Learning with Gradient Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation
Jul 03, 2023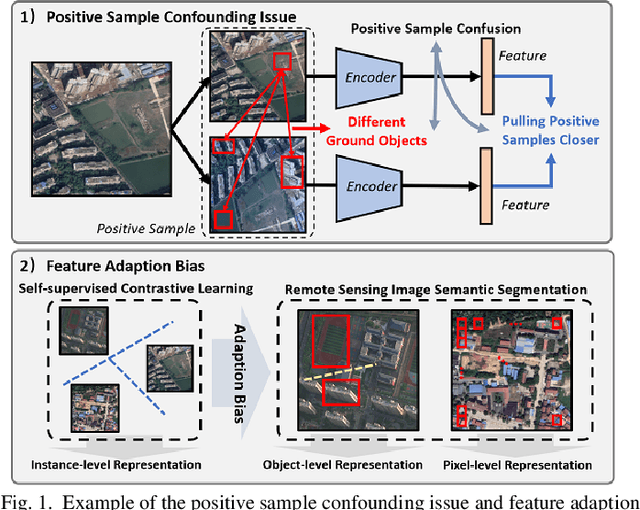

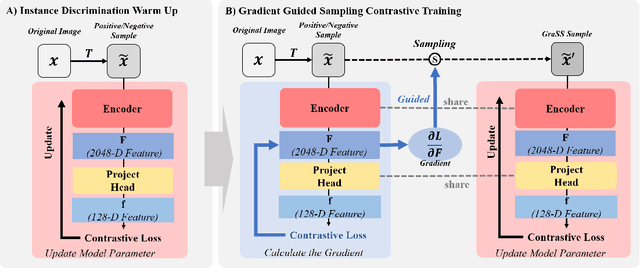
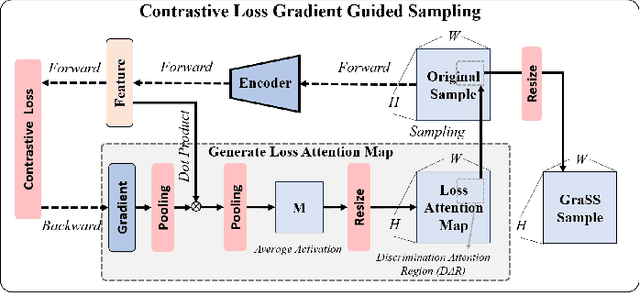
Self-supervised contrastive learning (SSCL) has achieved significant milestones in remote sensing image (RSI) understanding. Its essence lies in designing an unsupervised instance discrimination pretext task to extract image features from a large number of unlabeled images that are beneficial for downstream tasks. However, existing instance discrimination based SSCL suffer from two limitations when applied to the RSI semantic segmentation task: 1) Positive sample confounding issue; 2) Feature adaptation bias. It introduces a feature adaptation bias when applied to semantic segmentation tasks that require pixel-level or object-level features. In this study, We observed that the discrimination information can be mapped to specific regions in RSI through the gradient of unsupervised contrastive loss, these specific regions tend to contain singular ground objects. Based on this, we propose contrastive learning with Gradient guided Sampling Strategy (GraSS) for RSI semantic segmentation. GraSS consists of two stages: Instance Discrimination warm-up (ID warm-up) and Gradient guided Sampling contrastive training (GS training). The ID warm-up aims to provide initial discrimination information to the contrastive loss gradients. The GS training stage aims to utilize the discrimination information contained in the contrastive loss gradients and adaptively select regions in RSI patches that contain more singular ground objects, in order to construct new positive and negative samples. Experimental results on three open datasets demonstrate that GraSS effectively enhances the performance of SSCL in high-resolution RSI semantic segmentation. Compared to seven baseline methods from five different types of SSCL, GraSS achieves an average improvement of 1.57\% and a maximum improvement of 3.58\% in terms of mean intersection over the union. The source code is available at https://github.com/GeoX-Lab/GraSS
HAVANA: Hard negAtiVe sAmples aware self-supervised coNtrastive leArning for Airborne laser scanning point clouds semantic segmentation
Oct 19, 2022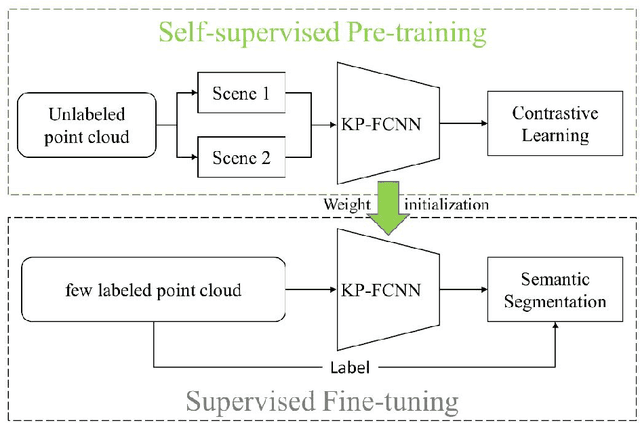
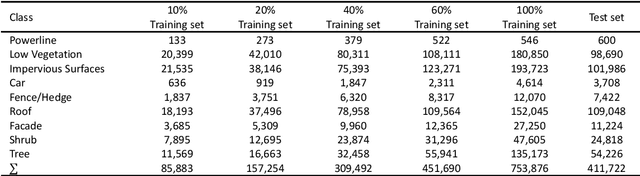
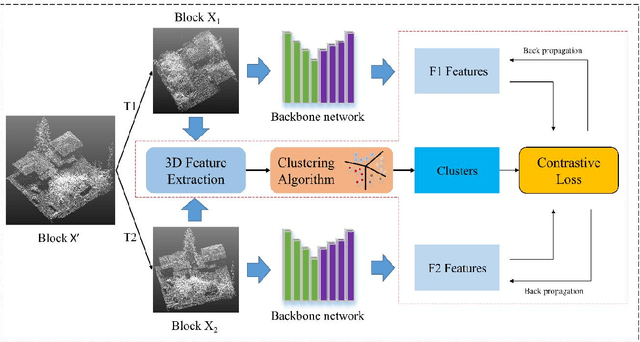
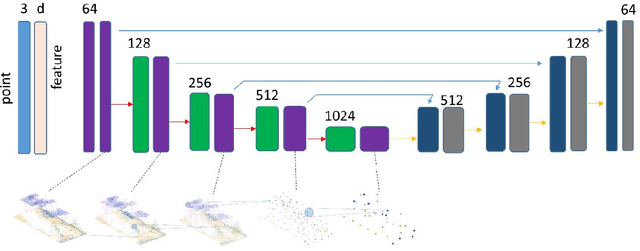
Deep Neural Network (DNN) based point cloud semantic segmentation has presented significant achievements on large-scale labeled aerial laser point cloud datasets. However, annotating such large-scaled point clouds is time-consuming. Due to density variations and spatial heterogeneity of the Airborne Laser Scanning (ALS) point clouds, DNNs lack generalization capability and thus lead to unpromising semantic segmentation, as the DNN trained in one region underperform when directly utilized in other regions. However, Self-Supervised Learning (SSL) is a promising way to solve this problem by pre-training a DNN model utilizing unlabeled samples followed by a fine-tuned downstream task involving very limited labels. Hence, this work proposes a hard-negative sample aware self-supervised contrastive learning method to pre-train the model for semantic segmentation. The traditional contrastive learning for point clouds selects the hardest negative samples by solely relying on the distance between the embedded features derived from the learning process, potentially evolving some negative samples from the same classes to reduce the contrastive learning effectiveness. Therefore, we design an AbsPAN (Absolute Positive And Negative samples) strategy based on k-means clustering to filter the possible false-negative samples. Experiments on two typical ALS benchmark datasets demonstrate that the proposed method is more appealing than supervised training schemes without pre-training. Especially when the labels are severely inadequate (10% of the ISPRS training set), the results obtained by the proposed HAVANA method still exceed 94% of the supervised paradigm performance with full training set.