 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDream.exe: Can Video Generation Models Dream Executable Robot Manipulation?
Jun 04, 2026Video generation models have made impressive strides in synthesizing visually compelling content, yet their outputs remain confined to the virtual domain. A natural question follows: how well do these models reflect the physical world when their generated videos leave the screen and enter reality? We propose robotic manipulation as a concrete, measurable window onto this question: if a model has truly internalized physical laws, the motion it depicts should translate into executable robot behavior. We introduce Dream$.$exe, an evaluation framework that operationalizes this criterion through a video-to-execution pipeline. Given a scene image and a task description, Dream$.$exe synthesizes a manipulation video, converts the generated motion into robot trajectories, and executes them in a physics simulator, yielding a grounding signal that purely visual metrics cannot offer. Using this pipeline, we evaluate 8 models spanning frontier closed-source generators, open-source generators, and robot-specific models. Our benchmark covers 101 manually curated manipulation tasks at three levels of physical complexity, measured across visual quality, trajectory fidelity, and execution success. Encouragingly, several models achieve measurable execution success, suggesting that generative priors learned from internet-scale data already encode meaningful physical knowledge. Yet visual quality proves a poor predictor of executability, exposing a dimension of model capability that standard visual evaluations do not capture. Dream$.$exe will be open-sourced at https://github.com/showlab/Dream.exe.
PanoAir: A Panoramic Visual-Inertial SLAM with Cross-Time Real-World UAV Dataset
Apr 01, 2026Accurate pose estimation is fundamental for unmanned aerial vehicle (UAV) applications, where Visual-Inertial SLAM (VI-SLAM) provides a cost-effective solution for localization and mapping. However, existing VI-SLAM methods mainly rely on sensors with limited fields of view (FoV), which can lead to drift and even failure in complex UAV scenarios. Although panoramic cameras provide omnidirectional perception to improve robustness, panoramic VI-SLAM and corresponding real-world datasets for UAVs remain underexplored. To address this limitation, we first construct a real-world panoramic visual-inertial dataset covering diverse flight conditions, including varying illumination, altitudes, trajectory lengths, and motion dynamics. To achieve accurate and robust pose estimation under such challenging UAV scenarios, we propose a panoramic VI-SLAM framework that exploits the omnidirectional FoV via the proposed panoramic feature extraction and panoramic loop closure, enhancing feature constraints and ensuring global consistency. Extensive experiments on both the proposed dataset and public benchmarks demonstrate that our method achieves superior accuracy, robustness, and consistency compared to existing approaches. Moreover, deployment on embedded platform validates its practical applicability, achieving comparable computational efficiency to PC implementations. The source code and dataset are publicly available at https://drive.google.com/file/d/1lG1Upn6yi-N6tYpEHAt6dfR1uhzNtWbT/view
You Only Look Omni Gradient Backpropagation for Moving Infrared Small Target Detection
Nov 17, 2025Moving infrared small target detection is a key component of infrared search and tracking systems, yet it remains extremely challenging due to low signal-to-clutter ratios, severe target-background imbalance, and weak discriminative features. Existing deep learning methods primarily focus on spatio-temporal feature aggregation, but their gains are limited, revealing that the fundamental bottleneck lies in ambiguous per-frame feature representations rather than spatio-temporal modeling itself. Motivated by this insight, we propose BP-FPN, a backpropagation-driven feature pyramid architecture that fundamentally rethinks feature learning for small target. BP-FPN introduces Gradient-Isolated Low-Level Shortcut (GILS) to efficiently incorporate fine-grained target details without inducing shortcut learning, and Directional Gradient Regularization (DGR) to enforce hierarchical feature consistency during backpropagation. The design is theoretically grounded, introduces negligible computational overhead, and can be seamlessly integrated into existing frameworks. Extensive experiments on multiple public datasets show that BP-FPN consistently establishes new state-of-the-art performance. To the best of our knowledge, it is the first FPN designed for this task entirely from the backpropagation perspective.
Beyond Motion Cues and Structural Sparsity: Revisiting Small Moving Target Detection
Sep 09, 2025Small moving target detection is crucial for many defense applications but remains highly challenging due to low signal-to-noise ratios, ambiguous visual cues, and cluttered backgrounds. In this work, we propose a novel deep learning framework that differs fundamentally from existing approaches, which often rely on target-specific features or motion cues and tend to lack robustness in complex environments. Our key insight is that small target detection and background discrimination are inherently coupled, even cluttered video backgrounds often exhibit strong low-rank structures that can serve as stable priors for detection. We reformulate the task as a tensor-based low-rank and sparse decomposition problem and conduct a theoretical analysis of the background, target, and noise components to guide model design. Building on these insights, we introduce TenRPCANet, a deep neural network that requires minimal assumptions about target characteristics. Specifically, we propose a tokenization strategy that implicitly enforces multi-order tensor low-rank priors through a self-attention mechanism. This mechanism captures both local and non-local self-similarity to model the low-rank background without relying on explicit iterative optimization. In addition, inspired by the sparse component update in tensor RPCA, we design a feature refinement module to enhance target saliency. The proposed method achieves state-of-the-art performance on two highly distinct and challenging tasks: multi-frame infrared small target detection and space object detection. These results demonstrate both the effectiveness and the generalizability of our approach.
It's Not the Target, It's the Background: Rethinking Infrared Small Target Detection via Deep Patch-Free Low-Rank Representations
Jun 12, 2025Infrared small target detection (IRSTD) remains a long-standing challenge in complex backgrounds due to low signal-to-clutter ratios (SCR), diverse target morphologies, and the absence of distinctive visual cues. While recent deep learning approaches aim to learn discriminative representations, the intrinsic variability and weak priors of small targets often lead to unstable performance. In this paper, we propose a novel end-to-end IRSTD framework, termed LRRNet, which leverages the low-rank property of infrared image backgrounds. Inspired by the physical compressibility of cluttered scenes, our approach adopts a compression--reconstruction--subtraction (CRS) paradigm to directly model structure-aware low-rank background representations in the image domain, without relying on patch-based processing or explicit matrix decomposition. To the best of our knowledge, this is the first work to directly learn low-rank background structures using deep neural networks in an end-to-end manner. Extensive experiments on multiple public datasets demonstrate that LRRNet outperforms 38 state-of-the-art methods in terms of detection accuracy, robustness, and computational efficiency. Remarkably, it achieves real-time performance with an average speed of 82.34 FPS. Evaluations on the challenging NoisySIRST dataset further confirm the model's resilience to sensor noise. The source code will be made publicly available upon acceptance.
Vision-Centric Representation-Efficient Fine-Tuning for Robust Universal Foreground Segmentation
Apr 20, 2025Foreground segmentation is crucial for scene understanding, yet parameter-efficient fine-tuning (PEFT) of vision foundation models (VFMs) often fails in complex scenarios, such as camouflage and infrared imagery. We attribute this challenge to the inherent texture bias in VFMs, which is exacerbated during fine-tuning and limits generalization in texture-sparse environments. To address this, we propose Ladder Shape-bias Representation Side-tuning (LSR-ST), a lightweight PEFT framework that enhances model robustness by introducing shape-biased inductive priors. LSR-ST captures shape-aware features using a simple HDConv Block, which integrates large-kernel attention and residual learning. The method satisfies three key conditions for inducing shape bias: large receptive fields, multi-order feature interactions, and sparse connectivity. Our analysis reveals that these improvements stem from representation efficiency-the ability to extract task-relevant, structurally grounded features while minimizing redundancy. We formalize this concept via Information Bottleneck theory and advocate for it as a key PEFT objective. Unlike traditional NLP paradigms that focus on optimizing parameters and memory, visual tasks require models that extract task-defined semantics, rather than just relying on pre-encoded features. This shift enables our approach to move beyond conventional trade-offs, offering more robust and generalizable solutions for vision tasks. With minimal changes to SAM2-UNet, LSR-ST achieves consistent improvements across 17 datasets and 6 tasks using only 4.719M trainable parameters. These results highlight the potential of representation efficiency for robust and adaptable VFMs within complex visual environments.
Low-Level Matters: An Efficient Hybrid Architecture for Robust Multi-frame Infrared Small Target Detection
Mar 04, 2025Multi-frame infrared small target detection (IRSTD) plays a crucial role in low-altitude and maritime surveillance. The hybrid architecture combining CNNs and Transformers shows great promise for enhancing multi-frame IRSTD performance. In this paper, we propose LVNet, a simple yet powerful hybrid architecture that redefines low-level feature learning in hybrid frameworks for multi-frame IRSTD. Our key insight is that the standard linear patch embeddings in Vision Transformers are insufficient for capturing the scale-sensitive local features critical to infrared small targets. To address this limitation, we introduce a multi-scale CNN frontend that explicitly models local features by leveraging the local spatial bias of convolution. Additionally, we design a U-shaped video Transformer for multi-frame spatiotemporal context modeling, effectively capturing the motion characteristics of targets. Experiments on the publicly available datasets IRDST and NUDT-MIRSDT demonstrate that LVNet outperforms existing state-of-the-art methods. Notably, compared to the current best-performing method, LMAFormer, LVNet achieves an improvement of 5.63\% / 18.36\% in nIoU, while using only 1/221 of the parameters and 1/92 / 1/21 of the computational cost. Ablation studies further validate the importance of low-level representation learning in hybrid architectures. Our code and trained models are available at https://github.com/ZhihuaShen/LVNet.
Learning Dynamic Local Context Representations for Infrared Small Target Detection
Dec 23, 2024Infrared small target detection (ISTD) is challenging due to complex backgrounds, low signal-to-clutter ratios, and varying target sizes and shapes. Effective detection relies on capturing local contextual information at the appropriate scale. However, small-kernel CNNs have limited receptive fields, leading to false alarms, while transformer models, with global receptive fields, often treat small targets as noise, resulting in miss-detections. Hybrid models struggle to bridge the semantic gap between CNNs and transformers, causing high complexity.To address these challenges, we propose LCRNet, a novel method that learns dynamic local context representations for ISTD. The model consists of three components: (1) C2FBlock, inspired by PDE solvers, for efficient small target information capture; (2) DLC-Attention, a large-kernel attention mechanism that dynamically builds context and reduces feature redundancy; and (3) HLKConv, a hierarchical convolution operator based on large-kernel decomposition that preserves sparsity and mitigates the drawbacks of dilated convolutions. Despite its simplicity, with only 1.65M parameters, LCRNet achieves state-of-the-art (SOTA) performance.Experiments on multiple datasets, comparing LCRNet with 33 SOTA methods, demonstrate its superior performance and efficiency.
HAVANA: Hard negAtiVe sAmples aware self-supervised coNtrastive leArning for Airborne laser scanning point clouds semantic segmentation
Oct 19, 2022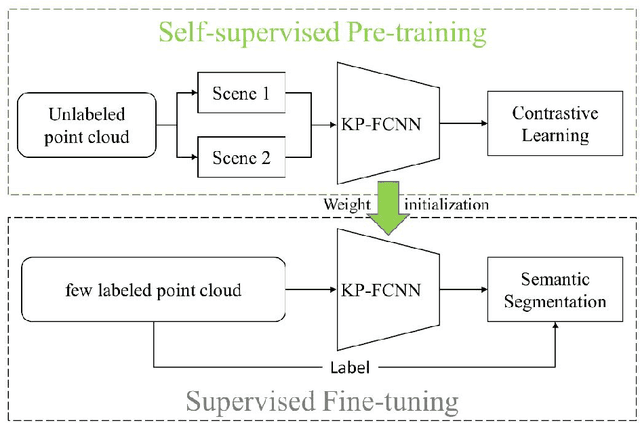
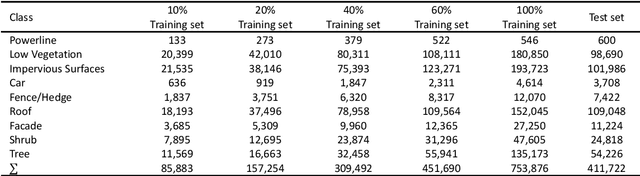
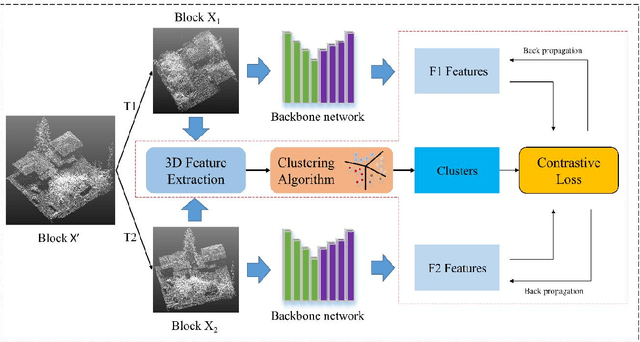
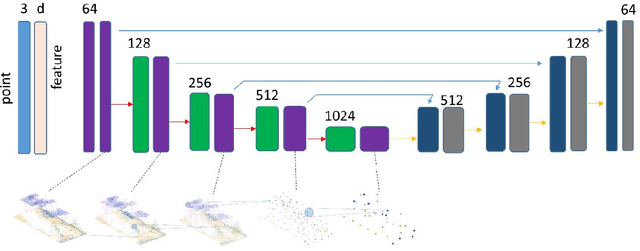
Deep Neural Network (DNN) based point cloud semantic segmentation has presented significant achievements on large-scale labeled aerial laser point cloud datasets. However, annotating such large-scaled point clouds is time-consuming. Due to density variations and spatial heterogeneity of the Airborne Laser Scanning (ALS) point clouds, DNNs lack generalization capability and thus lead to unpromising semantic segmentation, as the DNN trained in one region underperform when directly utilized in other regions. However, Self-Supervised Learning (SSL) is a promising way to solve this problem by pre-training a DNN model utilizing unlabeled samples followed by a fine-tuned downstream task involving very limited labels. Hence, this work proposes a hard-negative sample aware self-supervised contrastive learning method to pre-train the model for semantic segmentation. The traditional contrastive learning for point clouds selects the hardest negative samples by solely relying on the distance between the embedded features derived from the learning process, potentially evolving some negative samples from the same classes to reduce the contrastive learning effectiveness. Therefore, we design an AbsPAN (Absolute Positive And Negative samples) strategy based on k-means clustering to filter the possible false-negative samples. Experiments on two typical ALS benchmark datasets demonstrate that the proposed method is more appealing than supervised training schemes without pre-training. Especially when the labels are severely inadequate (10% of the ISPRS training set), the results obtained by the proposed HAVANA method still exceed 94% of the supervised paradigm performance with full training set.