 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamoyeds: Accelerating MoE Models with Structured Sparsity Leveraging Sparse Tensor Cores
Mar 13, 2025The escalating size of Mixture-of-Experts (MoE) based Large Language Models (LLMs) presents significant computational and memory challenges, necessitating innovative solutions to enhance efficiency without compromising model accuracy. Structured sparsity emerges as a compelling strategy to address these challenges by leveraging the emerging sparse computing hardware. Prior works mainly focus on the sparsity in model parameters, neglecting the inherent sparse patterns in activations. This oversight can lead to additional computational costs associated with activations, potentially resulting in suboptimal performance. This paper presents Samoyeds, an innovative acceleration system for MoE LLMs utilizing Sparse Tensor Cores (SpTCs). Samoyeds is the first to apply sparsity simultaneously to both activations and model parameters. It introduces a bespoke sparse data format tailored for MoE computation and develops a specialized sparse-sparse matrix multiplication kernel. Furthermore, Samoyeds incorporates systematic optimizations specifically designed for the execution of dual-side structured sparse MoE LLMs on SpTCs, further enhancing system performance. Evaluations show that Samoyeds outperforms SOTA works by up to 1.99$\times$ at the kernel level and 1.58$\times$ at the model level. Moreover, it enhances memory efficiency, increasing maximum supported batch sizes by 4.41$\times$ on average. Additionally, Samoyeds surpasses existing SOTA structured sparse solutions in both model accuracy and hardware portability.
HAVANA: Hard negAtiVe sAmples aware self-supervised coNtrastive leArning for Airborne laser scanning point clouds semantic segmentation
Oct 19, 2022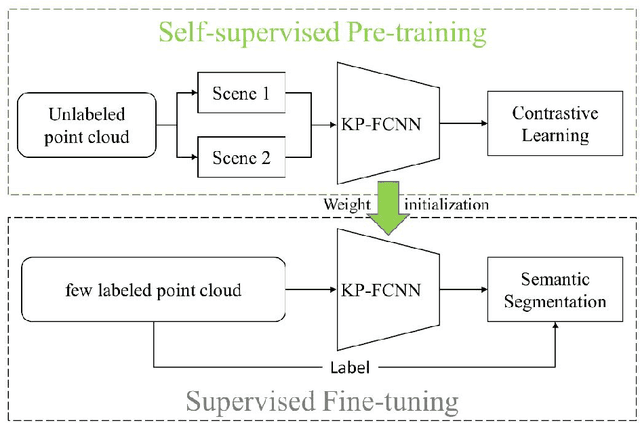
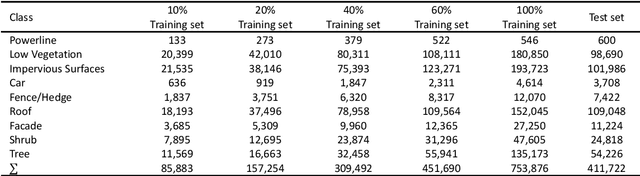
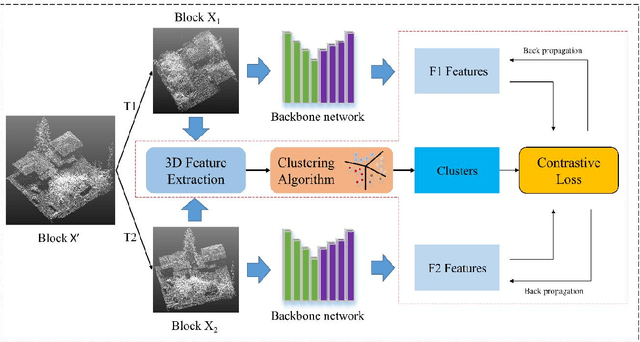
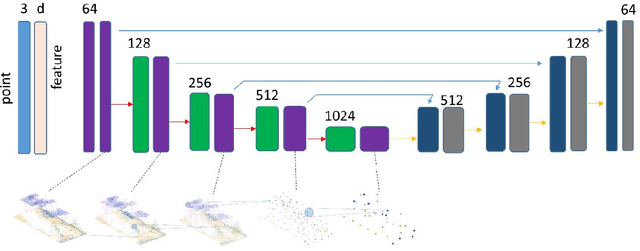
Deep Neural Network (DNN) based point cloud semantic segmentation has presented significant achievements on large-scale labeled aerial laser point cloud datasets. However, annotating such large-scaled point clouds is time-consuming. Due to density variations and spatial heterogeneity of the Airborne Laser Scanning (ALS) point clouds, DNNs lack generalization capability and thus lead to unpromising semantic segmentation, as the DNN trained in one region underperform when directly utilized in other regions. However, Self-Supervised Learning (SSL) is a promising way to solve this problem by pre-training a DNN model utilizing unlabeled samples followed by a fine-tuned downstream task involving very limited labels. Hence, this work proposes a hard-negative sample aware self-supervised contrastive learning method to pre-train the model for semantic segmentation. The traditional contrastive learning for point clouds selects the hardest negative samples by solely relying on the distance between the embedded features derived from the learning process, potentially evolving some negative samples from the same classes to reduce the contrastive learning effectiveness. Therefore, we design an AbsPAN (Absolute Positive And Negative samples) strategy based on k-means clustering to filter the possible false-negative samples. Experiments on two typical ALS benchmark datasets demonstrate that the proposed method is more appealing than supervised training schemes without pre-training. Especially when the labels are severely inadequate (10% of the ISPRS training set), the results obtained by the proposed HAVANA method still exceed 94% of the supervised paradigm performance with full training set.