 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamoyeds: Accelerating MoE Models with Structured Sparsity Leveraging Sparse Tensor Cores
Mar 13, 2025The escalating size of Mixture-of-Experts (MoE) based Large Language Models (LLMs) presents significant computational and memory challenges, necessitating innovative solutions to enhance efficiency without compromising model accuracy. Structured sparsity emerges as a compelling strategy to address these challenges by leveraging the emerging sparse computing hardware. Prior works mainly focus on the sparsity in model parameters, neglecting the inherent sparse patterns in activations. This oversight can lead to additional computational costs associated with activations, potentially resulting in suboptimal performance. This paper presents Samoyeds, an innovative acceleration system for MoE LLMs utilizing Sparse Tensor Cores (SpTCs). Samoyeds is the first to apply sparsity simultaneously to both activations and model parameters. It introduces a bespoke sparse data format tailored for MoE computation and develops a specialized sparse-sparse matrix multiplication kernel. Furthermore, Samoyeds incorporates systematic optimizations specifically designed for the execution of dual-side structured sparse MoE LLMs on SpTCs, further enhancing system performance. Evaluations show that Samoyeds outperforms SOTA works by up to 1.99$\times$ at the kernel level and 1.58$\times$ at the model level. Moreover, it enhances memory efficiency, increasing maximum supported batch sizes by 4.41$\times$ on average. Additionally, Samoyeds surpasses existing SOTA structured sparse solutions in both model accuracy and hardware portability.
Exploiting Fine-grained Face Forgery Clues via Progressive Enhancement Learning
Dec 28, 2021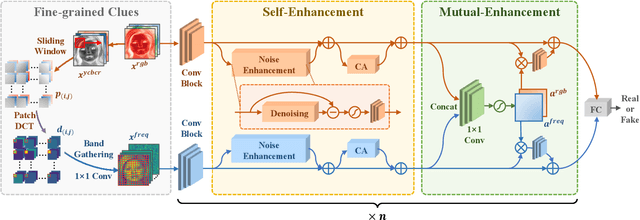
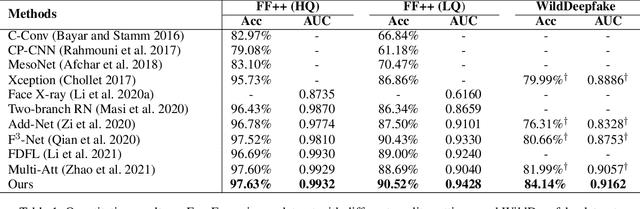
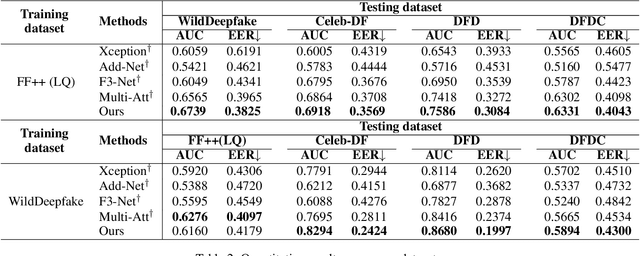

With the rapid development of facial forgery techniques, forgery detection has attracted more and more attention due to security concerns. Existing approaches attempt to use frequency information to mine subtle artifacts under high-quality forged faces. However, the exploitation of frequency information is coarse-grained, and more importantly, their vanilla learning process struggles to extract fine-grained forgery traces. To address this issue, we propose a progressive enhancement learning framework to exploit both the RGB and fine-grained frequency clues. Specifically, we perform a fine-grained decomposition of RGB images to completely decouple the real and fake traces in the frequency space. Subsequently, we propose a progressive enhancement learning framework based on a two-branch network, combined with self-enhancement and mutual-enhancement modules. The self-enhancement module captures the traces in different input spaces based on spatial noise enhancement and channel attention. The Mutual-enhancement module concurrently enhances RGB and frequency features by communicating in the shared spatial dimension. The progressive enhancement process facilitates the learning of discriminative features with fine-grained face forgery clues. Extensive experiments on several datasets show that our method outperforms the state-of-the-art face forgery detection methods.
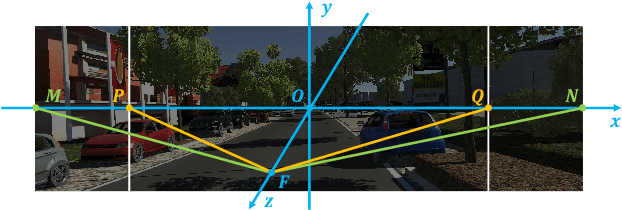
PIT: Position-Invariant Transform for Cross-FoV Domain Adaptation
Aug 16, 2021

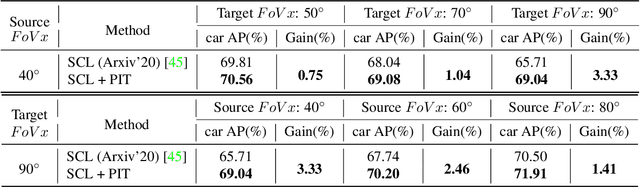

Cross-domain object detection and semantic segmentation have witnessed impressive progress recently. Existing approaches mainly consider the domain shift resulting from external environments including the changes of background, illumination or weather, while distinct camera intrinsic parameters appear commonly in different domains, and their influence for domain adaptation has been very rarely explored. In this paper, we observe that the Field of View (FoV) gap induces noticeable instance appearance differences between the source and target domains. We further discover that the FoV gap between two domains impairs domain adaptation performance under both the FoV-increasing (source FoV < target FoV) and FoV-decreasing cases. Motivated by the observations, we propose the \textbf{Position-Invariant Transform} (PIT) to better align images in different domains. We also introduce a reverse PIT for mapping the transformed/aligned images back to the original image space and design a loss re-weighting strategy to accelerate the training process. Our method can be easily plugged into existing cross-domain detection/segmentation frameworks while bringing about negligible computational overhead. Extensive experiments demonstrate that our method can soundly boost the performance on both cross-domain object detection and segmentation for state-of-the-art techniques. Our code is available at https://github.com/sheepooo/PIT-Position-Invariant-Transform.
Self-Adversarial Disentangling for Specific Domain Adaptation
Aug 11, 2021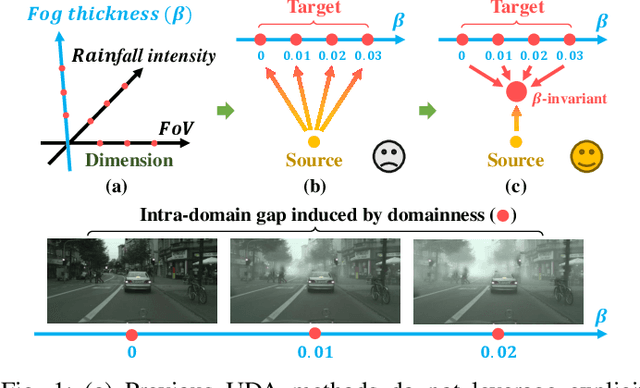
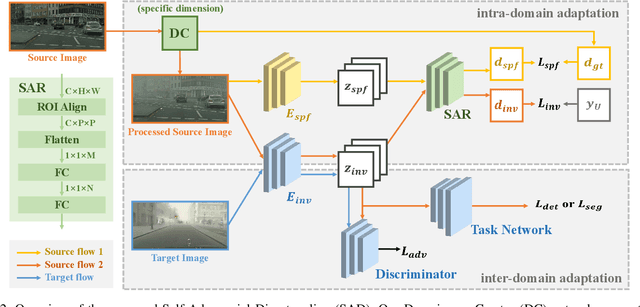

Domain adaptation aims to bridge the domain shifts between the source and target domains. These shifts may span different dimensions such as fog, rainfall, etc. However, recent methods typically do not consider explicit prior knowledge on a specific dimension, thus leading to less desired adaptation performance. In this paper, we study a practical setting called Specific Domain Adaptation (SDA) that aligns the source and target domains in a demanded-specific dimension. Within this setting, we observe the intra-domain gap induced by different domainness (i.e., numerical magnitudes of this dimension) is crucial when adapting to a specific domain. To address the problem, we propose a novel Self-Adversarial Disentangling (SAD) framework. In particular, given a specific dimension, we first enrich the source domain by introducing a domainness creator with providing additional supervisory signals. Guided by the created domainness, we design a self-adversarial regularizer and two loss functions to jointly disentangle the latent representations into domainness-specific and domainness-invariant features, thus mitigating the intra-domain gap. Our method can be easily taken as a plug-and-play framework and does not introduce any extra costs in the inference time. We achieve consistent improvements over state-of-the-art methods in both object detection and semantic segmentation tasks.
Context-Aware Mixup for Domain Adaptive Semantic Segmentation
Aug 11, 2021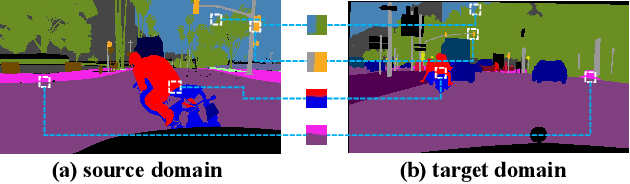
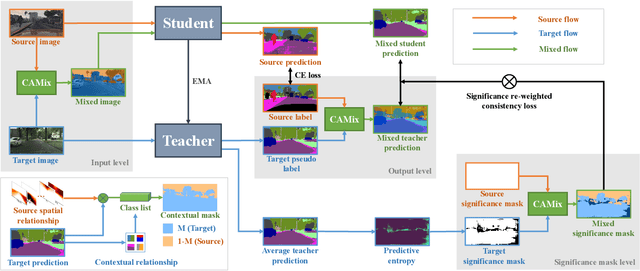

Unsupervised domain adaptation (UDA) aims to adapt a model of the labeled source domain to an unlabeled target domain. Although the domain shifts may exist in various dimensions such as appearance, textures, etc, the contextual dependency, which is generally shared across different domains, is neglected by recent methods. In this paper, we utilize this important clue as explicit prior knowledge and propose end-to-end Context-Aware Mixup (CAMix) for domain adaptive semantic segmentation. Firstly, we design a contextual mask generation strategy by leveraging accumulated spatial distributions and contextual relationships. The generated contextual mask is critical in this work and will guide the domain mixup. In addition, we define the significance mask to indicate where the pixels are credible. To alleviate the over-alignment (e.g., early performance degradation), the source and target significance masks are mixed based on the contextual mask into the mixed significance mask, and we introduce a significance-reweighted consistency loss on it. Experimental results show that the proposed method outperforms the state-of-the-art methods by a large margin on two widely-used domain adaptation benchmarks, i.e., GTAV $\rightarrow $ Cityscapes and SYNTHIA $\rightarrow $ Cityscapes.