 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDTracker: Synthetic Data Based Multi-Object Tracking
Mar 26, 2023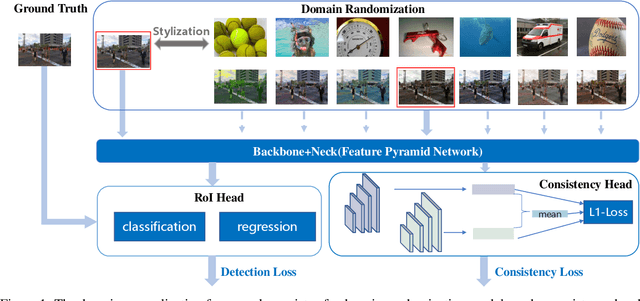
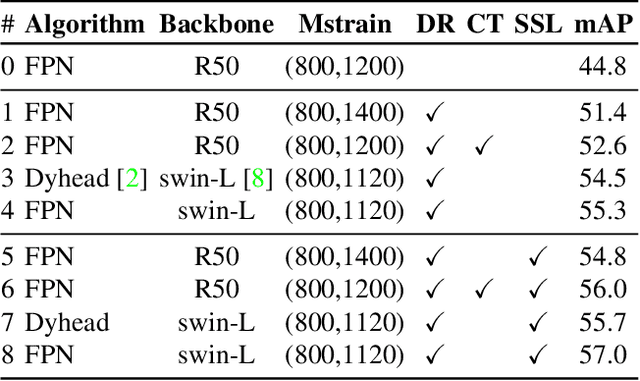
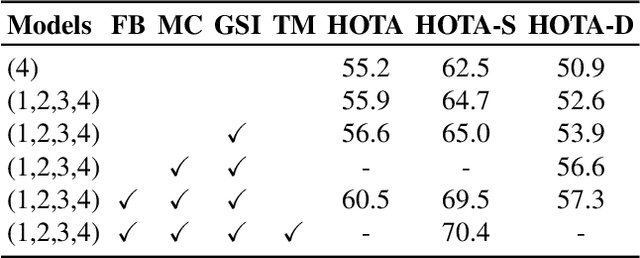
We present SDTracker, a method that harnesses the potential of synthetic data for multi-object tracking of real-world scenes in a domain generalization and semi-supervised fashion. First, we use the ImageNet dataset as an auxiliary to randomize the style of synthetic data. With out-of-domain data, we further enforce pyramid consistency loss across different "stylized" images from the same sample to learn domain invariant features. Second, we adopt the pseudo-labeling method to effectively utilize the unlabeled MOT17 training data. To obtain high-quality pseudo-labels, we apply proximal policy optimization (PPO2) algorithm to search confidence thresholds for each sequence. When using the unlabeled MOT17 training set, combined with the pure-motion tracking strategy upgraded via developed post-processing, we finally reach 61.4 HOTA.
Rethinking Efficient Lane Detection via Curve Modeling
Mar 04, 2022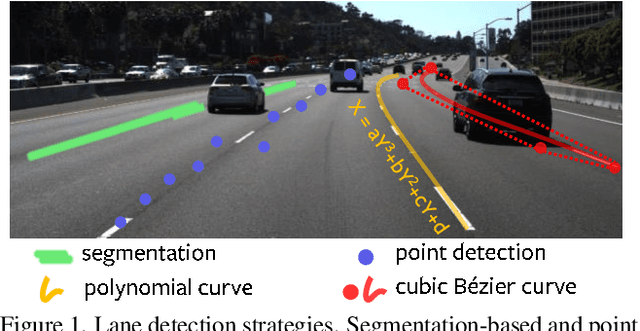
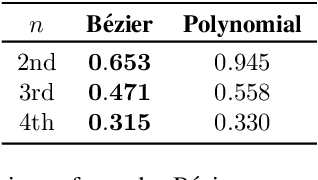
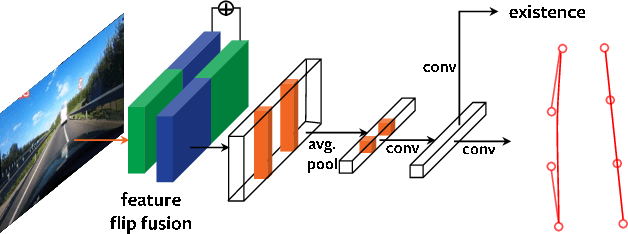

This paper presents a novel parametric curve-based method for lane detection in RGB images. Unlike state-of-the-art segmentation-based and point detection-based methods that typically require heuristics to either decode predictions or formulate a large sum of anchors, the curve-based methods can learn holistic lane representations naturally. To handle the optimization difficulties of existing polynomial curve methods, we propose to exploit the parametric B\'ezier curve due to its ease of computation, stability, and high freedom degrees of transformations. In addition, we propose the deformable convolution-based feature flip fusion, for exploiting the symmetry properties of lanes in driving scenes. The proposed method achieves a new state-of-the-art performance on the popular LLAMAS benchmark. It also achieves favorable accuracy on the TuSimple and CULane datasets, while retaining both low latency (> 150 FPS) and small model size (< 10M). Our method can serve as a new baseline, to shed the light on the parametric curves modeling for lane detection. Codes of our model and PytorchAutoDrive: a unified framework for self-driving perception, are available at: https://github.com/voldemortX/pytorch-auto-drive .
PIT: Position-Invariant Transform for Cross-FoV Domain Adaptation
Aug 16, 2021

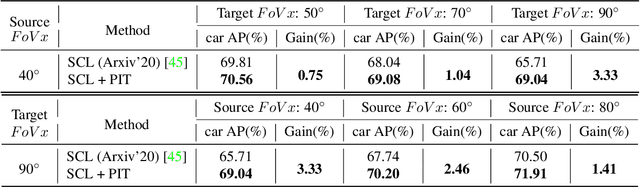

Cross-domain object detection and semantic segmentation have witnessed impressive progress recently. Existing approaches mainly consider the domain shift resulting from external environments including the changes of background, illumination or weather, while distinct camera intrinsic parameters appear commonly in different domains, and their influence for domain adaptation has been very rarely explored. In this paper, we observe that the Field of View (FoV) gap induces noticeable instance appearance differences between the source and target domains. We further discover that the FoV gap between two domains impairs domain adaptation performance under both the FoV-increasing (source FoV < target FoV) and FoV-decreasing cases. Motivated by the observations, we propose the \textbf{Position-Invariant Transform} (PIT) to better align images in different domains. We also introduce a reverse PIT for mapping the transformed/aligned images back to the original image space and design a loss re-weighting strategy to accelerate the training process. Our method can be easily plugged into existing cross-domain detection/segmentation frameworks while bringing about negligible computational overhead. Extensive experiments demonstrate that our method can soundly boost the performance on both cross-domain object detection and segmentation for state-of-the-art techniques. Our code is available at https://github.com/sheepooo/PIT-Position-Invariant-Transform.
Semi-supervised 3D Object Detection via Adaptive Pseudo-Labeling
Aug 15, 2021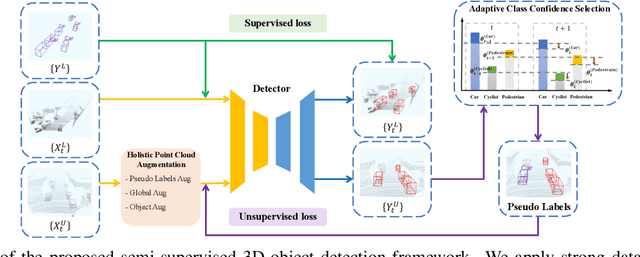
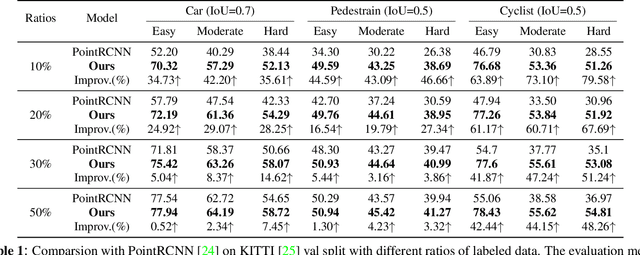
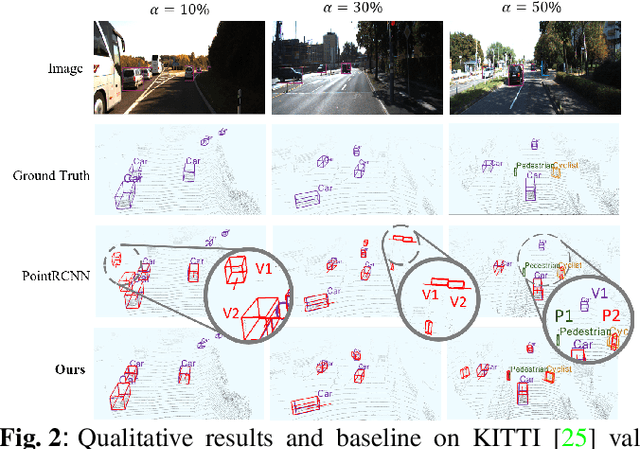
3D object detection is an important task in computer vision. Most existing methods require a large number of high-quality 3D annotations, which are expensive to collect. Especially for outdoor scenes, the problem becomes more severe due to the sparseness of the point cloud and the complexity of urban scenes. Semi-supervised learning is a promising technique to mitigate the data annotation issue. Inspired by this, we propose a novel semi-supervised framework based on pseudo-labeling for outdoor 3D object detection tasks. We design the Adaptive Class Confidence Selection module (ACCS) to generate high-quality pseudo-labels. Besides, we propose Holistic Point Cloud Augmentation (HPCA) for unlabeled data to improve robustness. Experiments on the KITTI benchmark demonstrate the effectiveness of our method.
Self-Adversarial Disentangling for Specific Domain Adaptation
Aug 11, 2021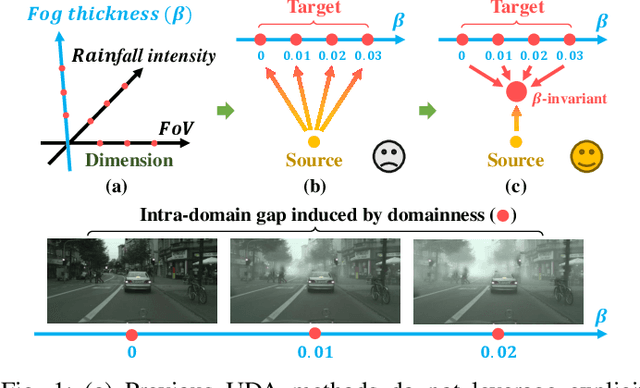
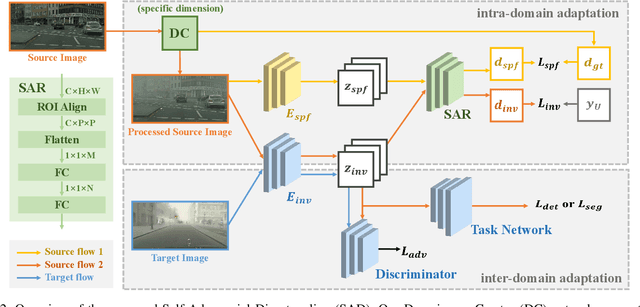
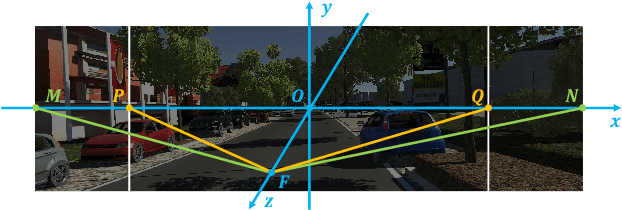

Domain adaptation aims to bridge the domain shifts between the source and target domains. These shifts may span different dimensions such as fog, rainfall, etc. However, recent methods typically do not consider explicit prior knowledge on a specific dimension, thus leading to less desired adaptation performance. In this paper, we study a practical setting called Specific Domain Adaptation (SDA) that aligns the source and target domains in a demanded-specific dimension. Within this setting, we observe the intra-domain gap induced by different domainness (i.e., numerical magnitudes of this dimension) is crucial when adapting to a specific domain. To address the problem, we propose a novel Self-Adversarial Disentangling (SAD) framework. In particular, given a specific dimension, we first enrich the source domain by introducing a domainness creator with providing additional supervisory signals. Guided by the created domainness, we design a self-adversarial regularizer and two loss functions to jointly disentangle the latent representations into domainness-specific and domainness-invariant features, thus mitigating the intra-domain gap. Our method can be easily taken as a plug-and-play framework and does not introduce any extra costs in the inference time. We achieve consistent improvements over state-of-the-art methods in both object detection and semantic segmentation tasks.
Context-Aware Mixup for Domain Adaptive Semantic Segmentation
Aug 11, 2021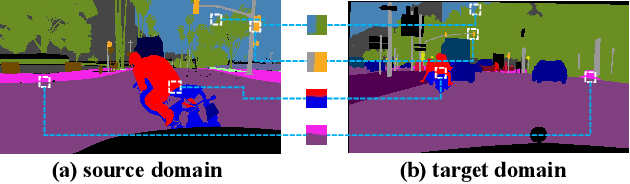
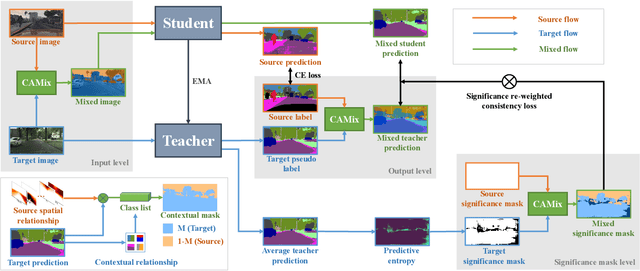

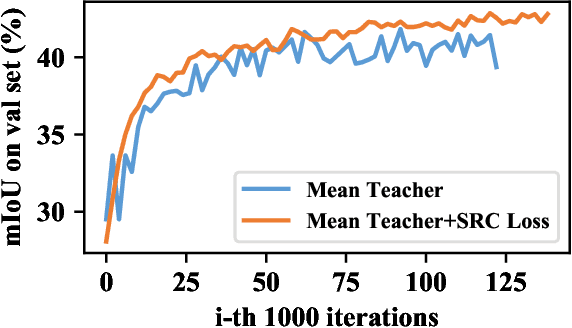
Unsupervised domain adaptation (UDA) aims to adapt a model of the labeled source domain to an unlabeled target domain. Although the domain shifts may exist in various dimensions such as appearance, textures, etc, the contextual dependency, which is generally shared across different domains, is neglected by recent methods. In this paper, we utilize this important clue as explicit prior knowledge and propose end-to-end Context-Aware Mixup (CAMix) for domain adaptive semantic segmentation. Firstly, we design a contextual mask generation strategy by leveraging accumulated spatial distributions and contextual relationships. The generated contextual mask is critical in this work and will guide the domain mixup. In addition, we define the significance mask to indicate where the pixels are credible. To alleviate the over-alignment (e.g., early performance degradation), the source and target significance masks are mixed based on the contextual mask into the mixed significance mask, and we introduce a significance-reweighted consistency loss on it. Experimental results show that the proposed method outperforms the state-of-the-art methods by a large margin on two widely-used domain adaptation benchmarks, i.e., GTAV $\rightarrow $ Cityscapes and SYNTHIA $\rightarrow $ Cityscapes.
Uncertainty-Aware Consistency Regularization for Cross-Domain Semantic Segmentation
Apr 19, 2020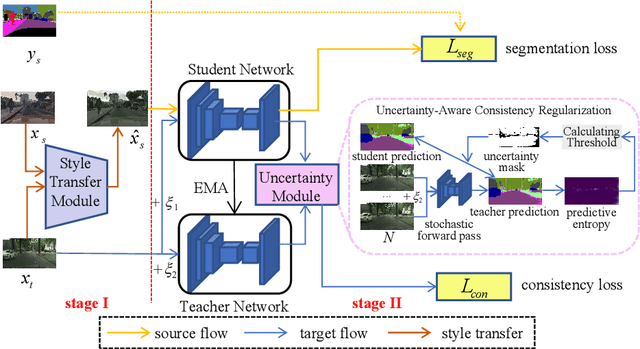

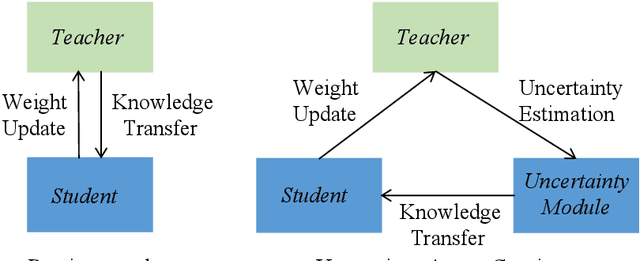
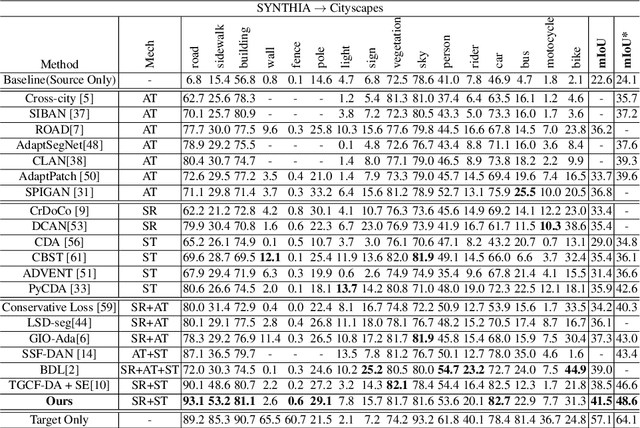
Unsupervised domain adaptation (UDA) aims to adapt existing models of the source domain to a new target domain with only unlabeled data. The main challenge to UDA lies in how to reduce the domain gap between the source domain and the target domain. Existing approaches of cross-domain semantic segmentation usually employ a consistency regularization on the target prediction of student model and teacher model respectively under different perturbations. However, previous works do not consider the reliability of the predicted target samples, which could harm the learning process by generating unreasonable guidance for the student model. In this paper, we propose an uncertainty-aware consistency regularization method to tackle this issue for semantic segmentation. By exploiting the latent uncertainty information of the target samples, more meaningful and reliable knowledge from the teacher model would be transferred to the student model. The experimental evaluation has shown that the proposed method outperforms the state-of-the-art methods by around $3\% \sim 5\%$ improvement on two domain adaptation benchmarks, i.e. GTAV $\rightarrow $ Cityscapes and SYNTHIA $\rightarrow $ Cityscapes.
Semi-Supervised Semantic Segmentation via Dynamic Self-Training and Class-Balanced Curriculum
Apr 18, 2020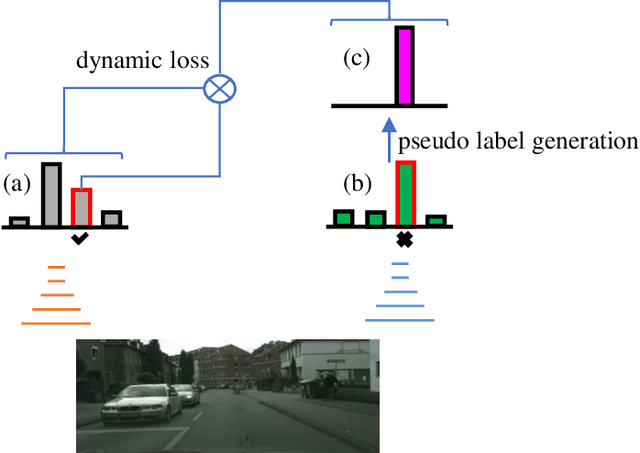

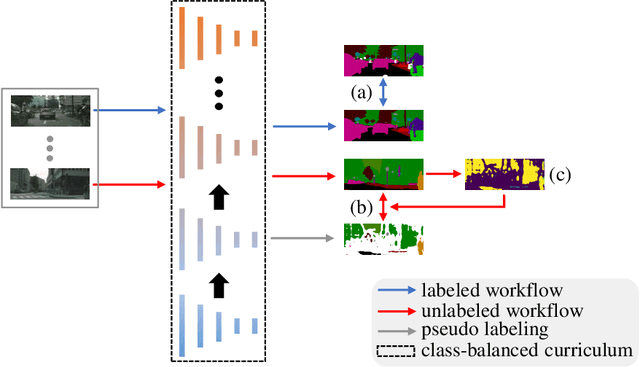
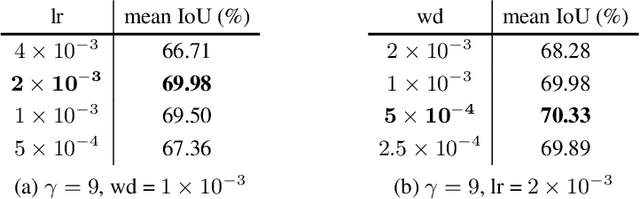
In this work, we propose a novel and concise approach for semi-supervised semantic segmentation. The major challenge of this task lies in how to exploit unlabeled data efficiently and thoroughly. Previous state-of-the-art methods utilize unlabeled data by GAN-based self-training or consistency regularization. However, these methods either suffer from noisy self-supervision and class-imbalance, resulting in a low unlabeled data utilization rate, or do not consider the apparent link between self-training and consistency regularization. Our method, Dynamic Self-Training and Class-Balanced Curriculum (DST-CBC), exploits inter-model disagreement by prediction confidence to construct a dynamic loss robust against pseudo label noise, enabling it to extend pseudo labeling to a class-balanced curriculum learning process. While we further show that our method implicitly includes consistency regularization. Thus, DST-CBC not only exploits unlabeled data efficiently, but also thoroughly utilizes $all$ unlabeled data. Without using adversarial training or any kind of modification to the network architecture, DST-CBC outperforms existing methods on different datasets across all labeled ratios, bringing semi-supervised learning yet another step closer to match the performance of fully-supervised learning for semantic segmentation. Our code and data splits are available at: https://github.com/voldemortX/DST-CBC .