 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesaTask: Towards Task-Driven Tabletop Scene Generation via 3D Spatial Reasoning
Sep 26, 2025
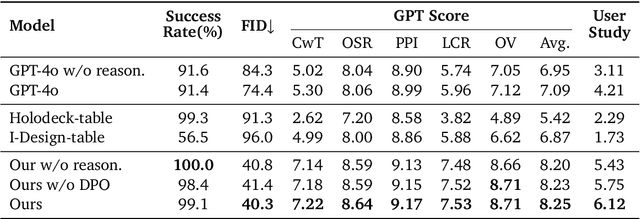
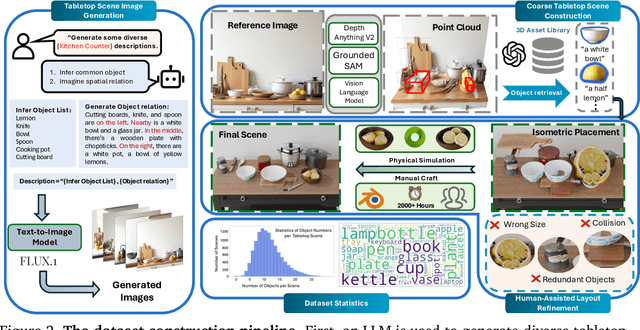
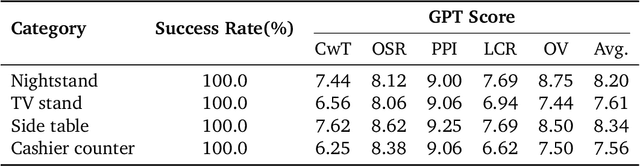
The ability of robots to interpret human instructions and execute manipulation tasks necessitates the availability of task-relevant tabletop scenes for training. However, traditional methods for creating these scenes rely on time-consuming manual layout design or purely randomized layouts, which are limited in terms of plausibility or alignment with the tasks. In this paper, we formulate a novel task, namely task-oriented tabletop scene generation, which poses significant challenges due to the substantial gap between high-level task instructions and the tabletop scenes. To support research on such a challenging task, we introduce MesaTask-10K, a large-scale dataset comprising approximately 10,700 synthetic tabletop scenes with manually crafted layouts that ensure realistic layouts and intricate inter-object relations. To bridge the gap between tasks and scenes, we propose a Spatial Reasoning Chain that decomposes the generation process into object inference, spatial interrelation reasoning, and scene graph construction for the final 3D layout. We present MesaTask, an LLM-based framework that utilizes this reasoning chain and is further enhanced with DPO algorithms to generate physically plausible tabletop scenes that align well with given task descriptions. Exhaustive experiments demonstrate the superior performance of MesaTask compared to baselines in generating task-conforming tabletop scenes with realistic layouts. Project page is at https://mesatask.github.io/
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jun 24, 2024While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
ClotheDreamer: Text-Guided Garment Generation with 3D Gaussians
Jun 24, 2024High-fidelity 3D garment synthesis from text is desirable yet challenging for digital avatar creation. Recent diffusion-based approaches via Score Distillation Sampling (SDS) have enabled new possibilities but either intricately couple with human body or struggle to reuse. We introduce ClotheDreamer, a 3D Gaussian-based method for generating wearable, production-ready 3D garment assets from text prompts. We propose a novel representation Disentangled Clothe Gaussian Splatting (DCGS) to enable separate optimization. DCGS represents clothed avatar as one Gaussian model but freezes body Gaussian splats. To enhance quality and completeness, we incorporate bidirectional SDS to supervise clothed avatar and garment RGBD renderings respectively with pose conditions and propose a new pruning strategy for loose clothing. Our approach can also support custom clothing templates as input. Benefiting from our design, the synthetic 3D garment can be easily applied to virtual try-on and support physically accurate animation. Extensive experiments showcase our method's superior and competitive performance. Our project page is at https://ggxxii.github.io/clothedreamer.
Learning Topology Uniformed Face Mesh by Volume Rendering for Multi-view Reconstruction
Apr 08, 2024Face meshes in consistent topology serve as the foundation for many face-related applications, such as 3DMM constrained face reconstruction and expression retargeting. Traditional methods commonly acquire topology uniformed face meshes by two separate steps: multi-view stereo (MVS) to reconstruct shapes followed by non-rigid registration to align topology, but struggles with handling noise and non-lambertian surfaces. Recently neural volume rendering techniques have been rapidly evolved and shown great advantages in 3D reconstruction or novel view synthesis. Our goal is to leverage the superiority of neural volume rendering into multi-view reconstruction of face mesh with consistent topology. We propose a mesh volume rendering method that enables directly optimizing mesh geometry while preserving topology, and learning implicit features to model complex facial appearance from multi-view images. The key innovation lies in spreading sparse mesh features into the surrounding space to simulate radiance field required for volume rendering, which facilitates backpropagation of gradients from images to mesh geometry and implicit appearance features. Our proposed feature spreading module exhibits deformation invariance, enabling photorealistic rendering seamlessly after mesh editing. We conduct experiments on multi-view face image dataset to evaluate the reconstruction and implement an application for photorealistic rendering of animated face mesh.
Semi-supervised 3D Object Detection via Adaptive Pseudo-Labeling
Aug 15, 2021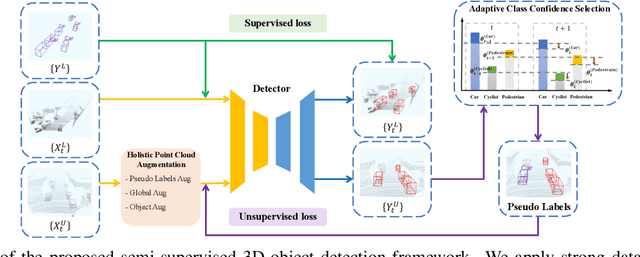
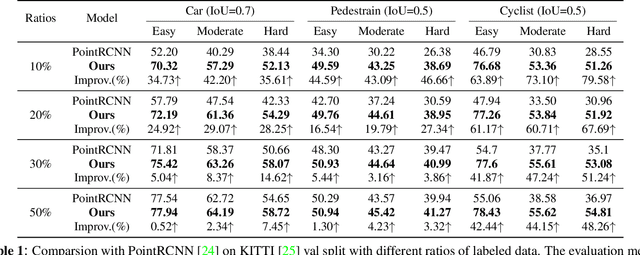
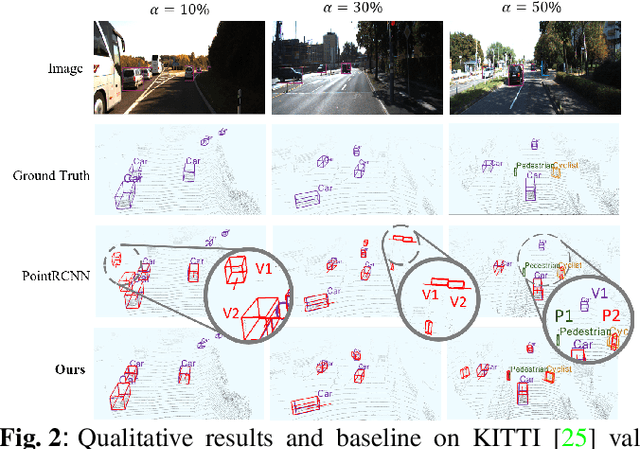
3D object detection is an important task in computer vision. Most existing methods require a large number of high-quality 3D annotations, which are expensive to collect. Especially for outdoor scenes, the problem becomes more severe due to the sparseness of the point cloud and the complexity of urban scenes. Semi-supervised learning is a promising technique to mitigate the data annotation issue. Inspired by this, we propose a novel semi-supervised framework based on pseudo-labeling for outdoor 3D object detection tasks. We design the Adaptive Class Confidence Selection module (ACCS) to generate high-quality pseudo-labels. Besides, we propose Holistic Point Cloud Augmentation (HPCA) for unlabeled data to improve robustness. Experiments on the KITTI benchmark demonstrate the effectiveness of our method.