 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMAN:Scaling 3D Human Gaussian Generation with Millions of Assets
Apr 09, 20253D human digitization has long been a highly pursued yet challenging task. Existing methods aim to generate high-quality 3D digital humans from single or multiple views, but remain primarily constrained by current paradigms and the scarcity of 3D human assets. Specifically, recent approaches fall into several paradigms: optimization-based and feed-forward (both single-view regression and multi-view generation with reconstruction). However, they are limited by slow speed, low quality, cascade reasoning, and ambiguity in mapping low-dimensional planes to high-dimensional space due to occlusion and invisibility, respectively. Furthermore, existing 3D human assets remain small-scale, insufficient for large-scale training. To address these challenges, we propose a latent space generation paradigm for 3D human digitization, which involves compressing multi-view images into Gaussians via a UV-structured VAE, along with DiT-based conditional generation, we transform the ill-posed low-to-high-dimensional mapping problem into a learnable distribution shift, which also supports end-to-end inference. In addition, we employ the multi-view optimization approach combined with synthetic data to construct the HGS-1M dataset, which contains $1$ million 3D Gaussian assets to support the large-scale training. Experimental results demonstrate that our paradigm, powered by large-scale training, produces high-quality 3D human Gaussians with intricate textures, facial details, and loose clothing deformation.
Diffusion Implicit Policy for Unpaired Scene-aware Motion Synthesis
Dec 03, 2024
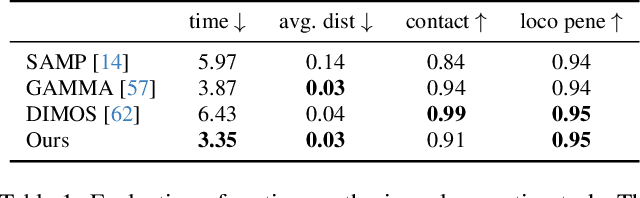


Human motion generation is a long-standing problem, and scene-aware motion synthesis has been widely researched recently due to its numerous applications. Prevailing methods rely heavily on paired motion-scene data whose quantity is limited. Meanwhile, it is difficult to generalize to diverse scenes when trained only on a few specific ones. Thus, we propose a unified framework, termed Diffusion Implicit Policy (DIP), for scene-aware motion synthesis, where paired motion-scene data are no longer necessary. In this framework, we disentangle human-scene interaction from motion synthesis during training and then introduce an interaction-based implicit policy into motion diffusion during inference. Synthesized motion can be derived through iterative diffusion denoising and implicit policy optimization, thus motion naturalness and interaction plausibility can be maintained simultaneously. The proposed implicit policy optimizes the intermediate noised motion in a GAN Inversion manner to maintain motion continuity and control keyframe poses though the ControlNet branch and motion inpainting. For long-term motion synthesis, we introduce motion blending for stable transitions between multiple sub-tasks, where motions are fused in rotation power space and translation linear space. The proposed method is evaluated on synthesized scenes with ShapeNet furniture, and real scenes from PROX and Replica. Results show that our framework presents better motion naturalness and interaction plausibility than cutting-edge methods. This also indicates the feasibility of utilizing the DIP for motion synthesis in more general tasks and versatile scenes. https://jingyugong.github.io/DiffusionImplicitPolicy/
MatPilot: an LLM-enabled AI Materials Scientist under the Framework of Human-Machine Collaboration
Nov 10, 2024The rapid evolution of artificial intelligence, particularly large language models, presents unprecedented opportunities for materials science research. We proposed and developed an AI materials scientist named MatPilot, which has shown encouraging abilities in the discovery of new materials. The core strength of MatPilot is its natural language interactive human-machine collaboration, which augments the research capabilities of human scientist teams through a multi-agent system. MatPilot integrates unique cognitive abilities, extensive accumulated experience, and ongoing curiosity of human-beings with the AI agents' capabilities of advanced abstraction, complex knowledge storage and high-dimensional information processing. It could generate scientific hypotheses and experimental schemes, and employ predictive models and optimization algorithms to drive an automated experimental platform for experiments. It turns out that our system demonstrates capabilities for efficient validation, continuous learning, and iterative optimization.
In-situ Self-optimization of Quantum Dot Emission for Lasers by Machine-Learning Assisted Epitaxy
Nov 01, 2024Traditional methods for optimizing light source emissions rely on a time-consuming trial-and-error approach. While in-situ optimization of light source gain media emission during growth is ideal, it has yet to be realized. In this work, we integrate in-situ reflection high-energy electron diffraction (RHEED) with machine learning (ML) to correlate the surface reconstruction with the photoluminescence (PL) of InAs/GaAs quantum dots (QDs), which serve as the active region of lasers. A lightweight ResNet-GLAM model is employed for the real-time processing of RHEED data as input, enabling effective identification of optical performance. This approach guides the dynamic optimization of growth parameters, allowing real-time feedback control to adjust the QDs emission for lasers. We successfully optimized InAs QDs on GaAs substrates, with a 3.2-fold increase in PL intensity and a reduction in full width at half maximum (FWHM) from 36.69 meV to 28.17 meV under initially suboptimal growth conditions. Our automated, in-situ self-optimized lasers with 5-layer InAs QDs achieved electrically pumped continuous-wave operation at 1240 nm with a low threshold current of 150 A/cm2 at room temperature, an excellent performance comparable to samples grown through traditional manual multi-parameter optimization methods. These results mark a significant step toward intelligent, low-cost, and reproductive light emitters production.
Emphasizing Semantic Consistency of Salient Posture for Speech-Driven Gesture Generation
Oct 17, 2024
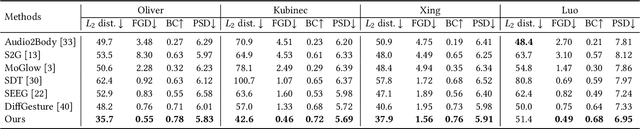
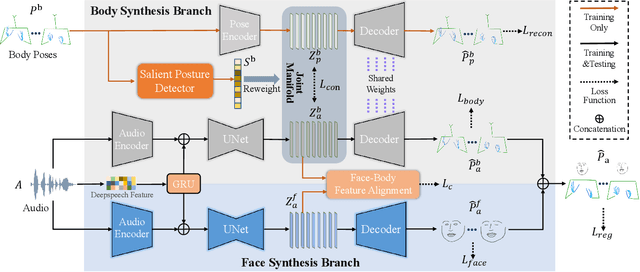
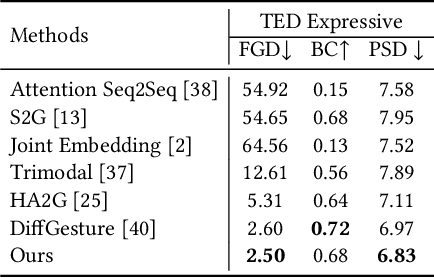
Speech-driven gesture generation aims at synthesizing a gesture sequence synchronized with the input speech signal. Previous methods leverage neural networks to directly map a compact audio representation to the gesture sequence, ignoring the semantic association of different modalities and failing to deal with salient gestures. In this paper, we propose a novel speech-driven gesture generation method by emphasizing the semantic consistency of salient posture. Specifically, we first learn a joint manifold space for the individual representation of audio and body pose to exploit the inherent semantic association between two modalities, and propose to enforce semantic consistency via a consistency loss. Furthermore, we emphasize the semantic consistency of salient postures by introducing a weakly-supervised detector to identify salient postures, and reweighting the consistency loss to focus more on learning the correspondence between salient postures and the high-level semantics of speech content. In addition, we propose to extract audio features dedicated to facial expression and body gesture separately, and design separate branches for face and body gesture synthesis. Extensive experimental results demonstrate the superiority of our method over the state-of-the-art approaches.
PointDGMamba: Domain Generalization of Point Cloud Classification via Generalized State Space Model
Aug 24, 2024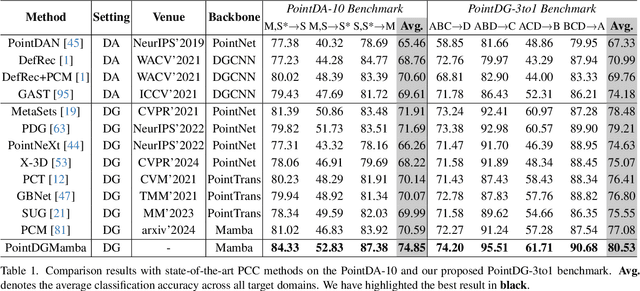
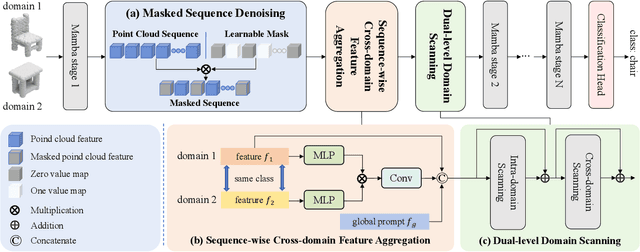

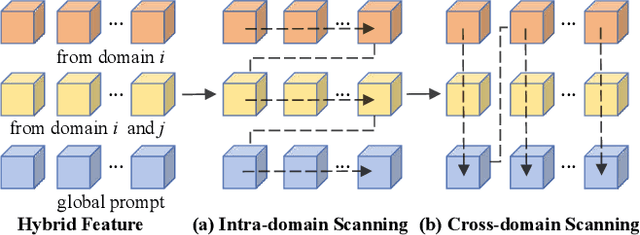
Domain Generalization (DG) has been recently explored to improve the generalizability of point cloud classification (PCC) models toward unseen domains. However, they often suffer from limited receptive fields or quadratic complexity due to the use of convolution neural networks or vision Transformers. In this paper, we present the first work that studies the generalizability of state space models (SSMs) in DG PCC and find that directly applying SSMs into DG PCC will encounter several challenges: the inherent topology of the point cloud tends to be disrupted and leads to noise accumulation during the serialization stage. Besides, the lack of designs in domain-agnostic feature learning and data scanning will introduce unanticipated domain-specific information into the 3D sequence data. To this end, we propose a novel framework, PointDGMamba, that excels in strong generalizability toward unseen domains and has the advantages of global receptive fields and efficient linear complexity. PointDGMamba consists of three innovative components: Masked Sequence Denoising (MSD), Sequence-wise Cross-domain Feature Aggregation (SCFA), and Dual-level Domain Scanning (DDS). In particular, MSD selectively masks out the noised point tokens of the point cloud sequences, SCFA introduces cross-domain but same-class point cloud features to encourage the model to learn how to extract more generalized features. DDS includes intra-domain scanning and cross-domain scanning to facilitate information exchange between features. In addition, we propose a new and more challenging benchmark PointDG-3to1 for multi-domain generalization. Extensive experiments demonstrate the effectiveness and state-of-the-art performance of our presented PointDGMamba.
Continuous Piecewise-Affine Based Motion Model for Image Animation
Jan 17, 2024Image animation aims to bring static images to life according to driving videos and create engaging visual content that can be used for various purposes such as animation, entertainment, and education. Recent unsupervised methods utilize affine and thin-plate spline transformations based on keypoints to transfer the motion in driving frames to the source image. However, limited by the expressive power of the transformations used, these methods always produce poor results when the gap between the motion in the driving frame and the source image is large. To address this issue, we propose to model motion from the source image to the driving frame in highly-expressive diffeomorphism spaces. Firstly, we introduce Continuous Piecewise-Affine based (CPAB) transformation to model the motion and present a well-designed inference algorithm to generate CPAB transformation from control keypoints. Secondly, we propose a SAM-guided keypoint semantic loss to further constrain the keypoint extraction process and improve the semantic consistency between the corresponding keypoints on the source and driving images. Finally, we design a structure alignment loss to align the structure-related features extracted from driving and generated images, thus helping the generator generate results that are more consistent with the driving action. Extensive experiments on four datasets demonstrate the effectiveness of our method against state-of-the-art competitors quantitatively and qualitatively. Code will be publicly available at: https://github.com/DevilPG/AAAI2024-CPABMM.
Semi-supervised 3D Object Detection via Adaptive Pseudo-Labeling
Aug 15, 2021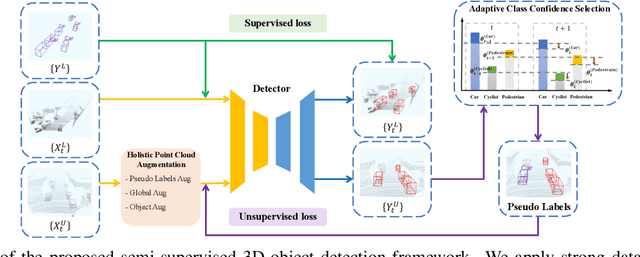
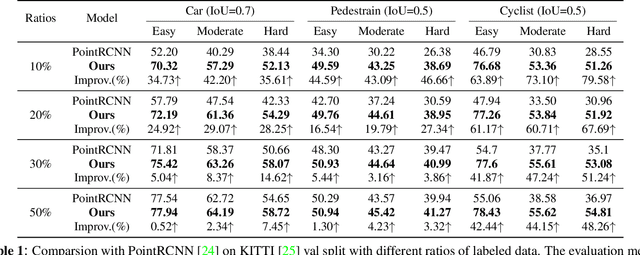
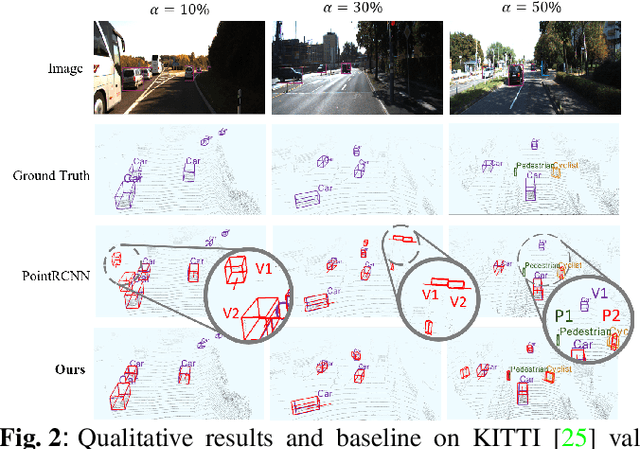
3D object detection is an important task in computer vision. Most existing methods require a large number of high-quality 3D annotations, which are expensive to collect. Especially for outdoor scenes, the problem becomes more severe due to the sparseness of the point cloud and the complexity of urban scenes. Semi-supervised learning is a promising technique to mitigate the data annotation issue. Inspired by this, we propose a novel semi-supervised framework based on pseudo-labeling for outdoor 3D object detection tasks. We design the Adaptive Class Confidence Selection module (ACCS) to generate high-quality pseudo-labels. Besides, we propose Holistic Point Cloud Augmentation (HPCA) for unlabeled data to improve robustness. Experiments on the KITTI benchmark demonstrate the effectiveness of our method.