 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscherVerse: An Open World Benchmark and Dataset for Teleo-Spatial Intelligence with Physical-Dynamic and Intent-Driven Understanding
Jan 04, 2026The ability to reason about spatial dynamics is a cornerstone of intelligence, yet current research overlooks the human intent behind spatial changes. To address these limitations, we introduce Teleo-Spatial Intelligence (TSI), a new paradigm that unifies two critical pillars: Physical-Dynamic Reasoning--understanding the physical principles of object interactions--and Intent-Driven Reasoning--inferring the human goals behind these actions. To catalyze research in TSI, we present EscherVerse, consisting of a large-scale, open-world benchmark (Escher-Bench), a dataset (Escher-35k), and models (Escher series). Derived from real-world videos, EscherVerse moves beyond constrained settings to explicitly evaluate an agent's ability to reason about object permanence, state transitions, and trajectory prediction in dynamic, human-centric scenarios. Crucially, it is the first benchmark to systematically assess Intent-Driven Reasoning, challenging models to connect physical events to their underlying human purposes. Our work, including a novel data curation pipeline, provides a foundational resource to advance spatial intelligence from passive scene description toward a holistic, purpose-driven understanding of the world.
UniForward: Unified 3D Scene and Semantic Field Reconstruction via Feed-Forward Gaussian Splatting from Only Sparse-View Images
Jun 11, 2025We propose a feed-forward Gaussian Splatting model that unifies 3D scene and semantic field reconstruction. Combining 3D scenes with semantic fields facilitates the perception and understanding of the surrounding environment. However, key challenges include embedding semantics into 3D representations, achieving generalizable real-time reconstruction, and ensuring practical applicability by using only images as input without camera parameters or ground truth depth. To this end, we propose UniForward, a feed-forward model to predict 3D Gaussians with anisotropic semantic features from only uncalibrated and unposed sparse-view images. To enable the unified representation of the 3D scene and semantic field, we embed semantic features into 3D Gaussians and predict them through a dual-branch decoupled decoder. During training, we propose a loss-guided view sampler to sample views from easy to hard, eliminating the need for ground truth depth or masks required by previous methods and stabilizing the training process. The whole model can be trained end-to-end using a photometric loss and a distillation loss that leverages semantic features from a pre-trained 2D semantic model. At the inference stage, our UniForward can reconstruct 3D scenes and the corresponding semantic fields in real time from only sparse-view images. The reconstructed 3D scenes achieve high-quality rendering, and the reconstructed 3D semantic field enables the rendering of view-consistent semantic features from arbitrary views, which can be further decoded into dense segmentation masks in an open-vocabulary manner. Experiments on novel view synthesis and novel view segmentation demonstrate that our method achieves state-of-the-art performances for unifying 3D scene and semantic field reconstruction.
DORAEMON: Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation
May 29, 2025Adaptive navigation in unfamiliar environments is crucial for household service robots but remains challenging due to the need for both low-level path planning and high-level scene understanding. While recent vision-language model (VLM) based zero-shot approaches reduce dependence on prior maps and scene-specific training data, they face significant limitations: spatiotemporal discontinuity from discrete observations, unstructured memory representations, and insufficient task understanding leading to navigation failures. We propose DORAEMON (Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation), a novel cognitive-inspired framework consisting of Ventral and Dorsal Streams that mimics human navigation capabilities. The Dorsal Stream implements the Hierarchical Semantic-Spatial Fusion and Topology Map to handle spatiotemporal discontinuities, while the Ventral Stream combines RAG-VLM and Policy-VLM to improve decision-making. Our approach also develops Nav-Ensurance to ensure navigation safety and efficiency. We evaluate DORAEMON on the HM3D, MP3D, and GOAT datasets, where it achieves state-of-the-art performance on both success rate (SR) and success weighted by path length (SPL) metrics, significantly outperforming existing methods. We also introduce a new evaluation metric (AORI) to assess navigation intelligence better. Comprehensive experiments demonstrate DORAEMON's effectiveness in zero-shot autonomous navigation without requiring prior map building or pre-training.
Reconstructing In-the-Wild Open-Vocabulary Human-Object Interactions
Mar 20, 2025Reconstructing human-object interactions (HOI) from single images is fundamental in computer vision. Existing methods are primarily trained and tested on indoor scenes due to the lack of 3D data, particularly constrained by the object variety, making it challenging to generalize to real-world scenes with a wide range of objects. The limitations of previous 3D HOI datasets were primarily due to the difficulty in acquiring 3D object assets. However, with the development of 3D reconstruction from single images, recently it has become possible to reconstruct various objects from 2D HOI images. We therefore propose a pipeline for annotating fine-grained 3D humans, objects, and their interactions from single images. We annotated 2.5k+ 3D HOI assets from existing 2D HOI datasets and built the first open-vocabulary in-the-wild 3D HOI dataset Open3DHOI, to serve as a future test set. Moreover, we design a novel Gaussian-HOI optimizer, which efficiently reconstructs the spatial interactions between humans and objects while learning the contact regions. Besides the 3D HOI reconstruction, we also propose several new tasks for 3D HOI understanding to pave the way for future work. Data and code will be publicly available at https://wenboran2002.github.io/3dhoi.
DAPoinTr: Domain Adaptive Point Transformer for Point Cloud Completion
Dec 26, 2024



Point Transformers (PoinTr) have shown great potential in point cloud completion recently. Nevertheless, effective domain adaptation that improves transferability toward target domains remains unexplored. In this paper, we delve into this topic and empirically discover that direct feature alignment on point Transformer's CNN backbone only brings limited improvements since it cannot guarantee sequence-wise domain-invariant features in the Transformer. To this end, we propose a pioneering Domain Adaptive Point Transformer (DAPoinTr) framework for point cloud completion. DAPoinTr consists of three key components: Domain Query-based Feature Alignment (DQFA), Point Token-wise Feature alignment (PTFA), and Voted Prediction Consistency (VPC). In particular, DQFA is presented to narrow the global domain gaps from the sequence via the presented domain proxy and domain query at the Transformer encoder and decoder, respectively. PTFA is proposed to close the local domain shifts by aligning the tokens, \emph{i.e.,} point proxy and dynamic query, at the Transformer encoder and decoder, respectively. VPC is designed to consider different Transformer decoders as multiple of experts (MoE) for ensembled prediction voting and pseudo-label generation. Extensive experiments with visualization on several domain adaptation benchmarks demonstrate the effectiveness and superiority of our DAPoinTr compared with state-of-the-art methods. Code will be publicly available at: https://github.com/Yinghui-Li-New/DAPoinTr
Diffusion Implicit Policy for Unpaired Scene-aware Motion Synthesis
Dec 03, 2024
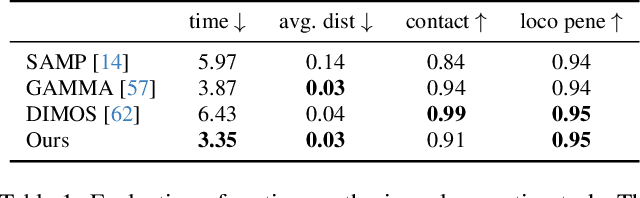


Human motion generation is a long-standing problem, and scene-aware motion synthesis has been widely researched recently due to its numerous applications. Prevailing methods rely heavily on paired motion-scene data whose quantity is limited. Meanwhile, it is difficult to generalize to diverse scenes when trained only on a few specific ones. Thus, we propose a unified framework, termed Diffusion Implicit Policy (DIP), for scene-aware motion synthesis, where paired motion-scene data are no longer necessary. In this framework, we disentangle human-scene interaction from motion synthesis during training and then introduce an interaction-based implicit policy into motion diffusion during inference. Synthesized motion can be derived through iterative diffusion denoising and implicit policy optimization, thus motion naturalness and interaction plausibility can be maintained simultaneously. The proposed implicit policy optimizes the intermediate noised motion in a GAN Inversion manner to maintain motion continuity and control keyframe poses though the ControlNet branch and motion inpainting. For long-term motion synthesis, we introduce motion blending for stable transitions between multiple sub-tasks, where motions are fused in rotation power space and translation linear space. The proposed method is evaluated on synthesized scenes with ShapeNet furniture, and real scenes from PROX and Replica. Results show that our framework presents better motion naturalness and interaction plausibility than cutting-edge methods. This also indicates the feasibility of utilizing the DIP for motion synthesis in more general tasks and versatile scenes. https://jingyugong.github.io/DiffusionImplicitPolicy/
Textual Decomposition Then Sub-motion-space Scattering for Open-Vocabulary Motion Generation
Nov 06, 2024



Text-to-motion generation is a crucial task in computer vision, which generates the target 3D motion by the given text. The existing annotated datasets are limited in scale, resulting in most existing methods overfitting to the small datasets and unable to generalize to the motions of the open domain. Some methods attempt to solve the open-vocabulary motion generation problem by aligning to the CLIP space or using the Pretrain-then-Finetuning paradigm. However, the current annotated dataset's limited scale only allows them to achieve mapping from sub-text-space to sub-motion-space, instead of mapping between full-text-space and full-motion-space (full mapping), which is the key to attaining open-vocabulary motion generation. To this end, this paper proposes to leverage the atomic motion (simple body part motions over a short time period) as an intermediate representation, and leverage two orderly coupled steps, i.e., Textual Decomposition and Sub-motion-space Scattering, to address the full mapping problem. For Textual Decomposition, we design a fine-grained description conversion algorithm, and combine it with the generalization ability of a large language model to convert any given motion text into atomic texts. Sub-motion-space Scattering learns the compositional process from atomic motions to the target motions, to make the learned sub-motion-space scattered to form the full-motion-space. For a given motion of the open domain, it transforms the extrapolation into interpolation and thereby significantly improves generalization. Our network, $DSO$-Net, combines textual $d$ecomposition and sub-motion-space $s$cattering to solve the $o$pen-vocabulary motion generation. Extensive experiments demonstrate that our DSO-Net achieves significant improvements over the state-of-the-art methods on open-vocabulary motion generation. Code is available at https://vankouf.github.io/DSONet/.
Emphasizing Semantic Consistency of Salient Posture for Speech-Driven Gesture Generation
Oct 17, 2024
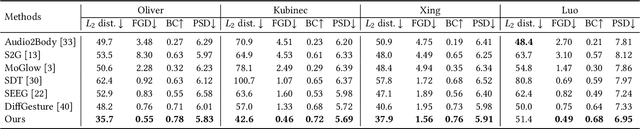
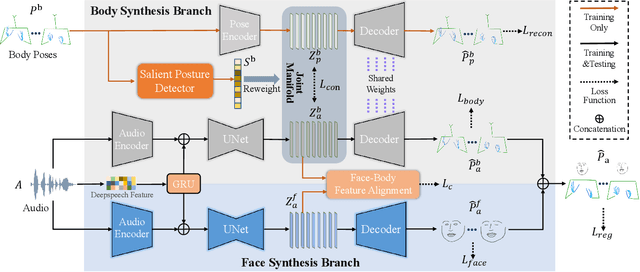
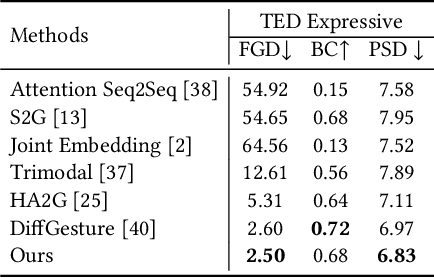
Speech-driven gesture generation aims at synthesizing a gesture sequence synchronized with the input speech signal. Previous methods leverage neural networks to directly map a compact audio representation to the gesture sequence, ignoring the semantic association of different modalities and failing to deal with salient gestures. In this paper, we propose a novel speech-driven gesture generation method by emphasizing the semantic consistency of salient posture. Specifically, we first learn a joint manifold space for the individual representation of audio and body pose to exploit the inherent semantic association between two modalities, and propose to enforce semantic consistency via a consistency loss. Furthermore, we emphasize the semantic consistency of salient postures by introducing a weakly-supervised detector to identify salient postures, and reweighting the consistency loss to focus more on learning the correspondence between salient postures and the high-level semantics of speech content. In addition, we propose to extract audio features dedicated to facial expression and body gesture separately, and design separate branches for face and body gesture synthesis. Extensive experimental results demonstrate the superiority of our method over the state-of-the-art approaches.
FreeMotion: A Unified Framework for Number-free Text-to-Motion Synthesis
May 24, 2024



Text-to-motion synthesis is a crucial task in computer vision. Existing methods are limited in their universality, as they are tailored for single-person or two-person scenarios and can not be applied to generate motions for more individuals. To achieve the number-free motion synthesis, this paper reconsiders motion generation and proposes to unify the single and multi-person motion by the conditional motion distribution. Furthermore, a generation module and an interaction module are designed for our FreeMotion framework to decouple the process of conditional motion generation and finally support the number-free motion synthesis. Besides, based on our framework, the current single-person motion spatial control method could be seamlessly integrated, achieving precise control of multi-person motion. Extensive experiments demonstrate the superior performance of our method and our capability to infer single and multi-human motions simultaneously.
DEMOS: Dynamic Environment Motion Synthesis in 3D Scenes via Local Spherical-BEV Perception
Mar 04, 2024


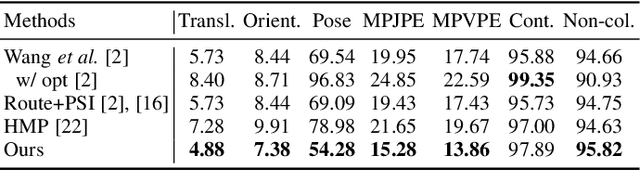
Motion synthesis in real-world 3D scenes has recently attracted much attention. However, the static environment assumption made by most current methods usually cannot be satisfied especially for real-time motion synthesis in scanned point cloud scenes, if multiple dynamic objects exist, e.g., moving persons or vehicles. To handle this problem, we propose the first Dynamic Environment MOtion Synthesis framework (DEMOS) to predict future motion instantly according to the current scene, and use it to dynamically update the latent motion for final motion synthesis. Concretely, we propose a Spherical-BEV perception method to extract local scene features that are specifically designed for instant scene-aware motion prediction. Then, we design a time-variant motion blending to fuse the new predicted motions into the latent motion, and the final motion is derived from the updated latent motions, benefitting both from motion-prior and iterative methods. We unify the data format of two prevailing datasets, PROX and GTA-IM, and take them for motion synthesis evaluation in 3D scenes. We also assess the effectiveness of the proposed method in dynamic environments from GTA-IM and Semantic3D to check the responsiveness. The results show our method outperforms previous works significantly and has great performance in handling dynamic environments.