 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDTracker: Synthetic Data Based Multi-Object Tracking
Mar 26, 2023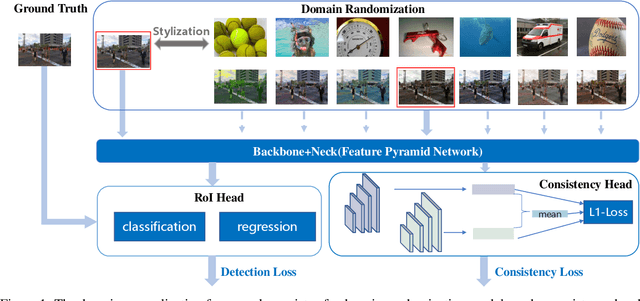
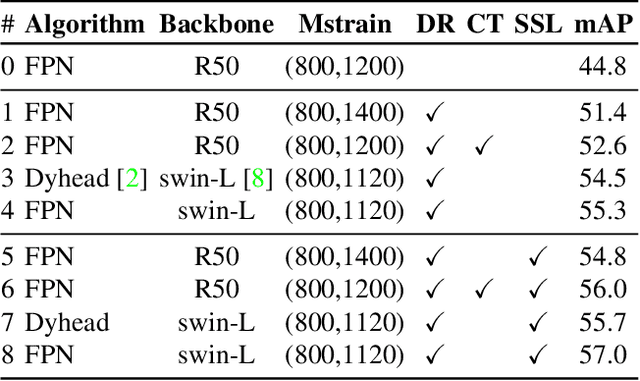
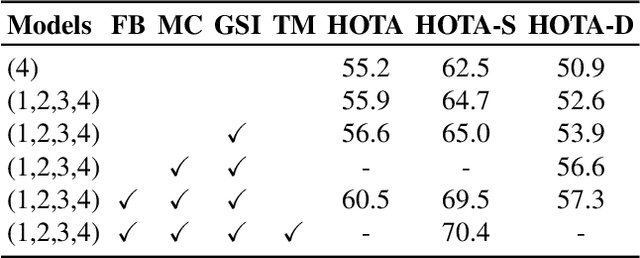
We present SDTracker, a method that harnesses the potential of synthetic data for multi-object tracking of real-world scenes in a domain generalization and semi-supervised fashion. First, we use the ImageNet dataset as an auxiliary to randomize the style of synthetic data. With out-of-domain data, we further enforce pyramid consistency loss across different "stylized" images from the same sample to learn domain invariant features. Second, we adopt the pseudo-labeling method to effectively utilize the unlabeled MOT17 training data. To obtain high-quality pseudo-labels, we apply proximal policy optimization (PPO2) algorithm to search confidence thresholds for each sequence. When using the unlabeled MOT17 training set, combined with the pure-motion tracking strategy upgraded via developed post-processing, we finally reach 61.4 HOTA.
Pseudo-Labeled Auto-Curriculum Learning for Semi-Supervised Keypoint Localization
Jan 24, 2022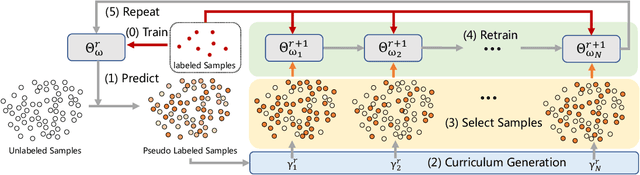


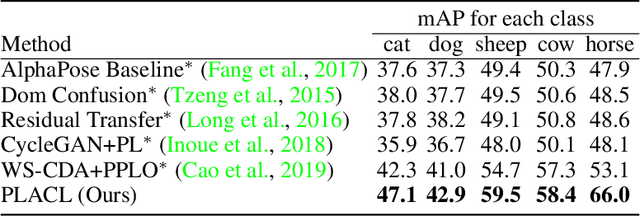
Localizing keypoints of an object is a basic visual problem. However, supervised learning of a keypoint localization network often requires a large amount of data, which is expensive and time-consuming to obtain. To remedy this, there is an ever-growing interest in semi-supervised learning (SSL), which leverages a small set of labeled data along with a large set of unlabeled data. Among these SSL approaches, pseudo-labeling (PL) is one of the most popular. PL approaches apply pseudo-labels to unlabeled data, and then train the model with a combination of the labeled and pseudo-labeled data iteratively. The key to the success of PL is the selection of high-quality pseudo-labeled samples. Previous works mostly select training samples by manually setting a single confidence threshold. We propose to automatically select reliable pseudo-labeled samples with a series of dynamic thresholds, which constitutes a learning curriculum. Extensive experiments on six keypoint localization benchmark datasets demonstrate that the proposed approach significantly outperforms the previous state-of-the-art SSL approaches.
ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
May 21, 2021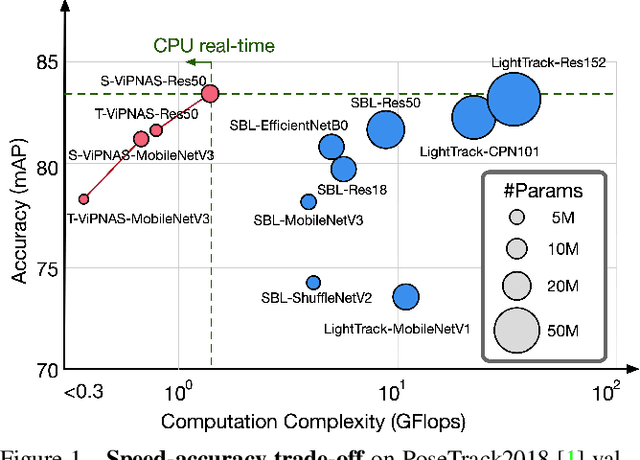
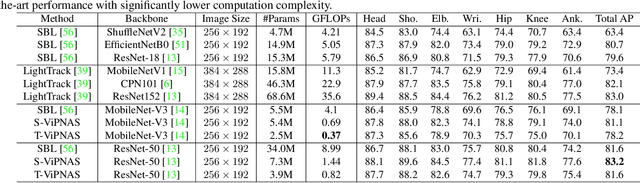
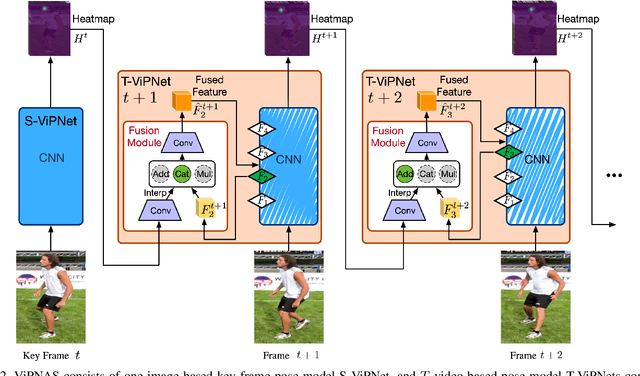
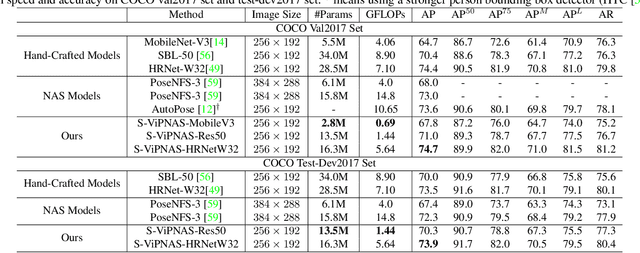
Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.