 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraSS: Contrastive Learning with Gradient Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation
Jul 03, 2023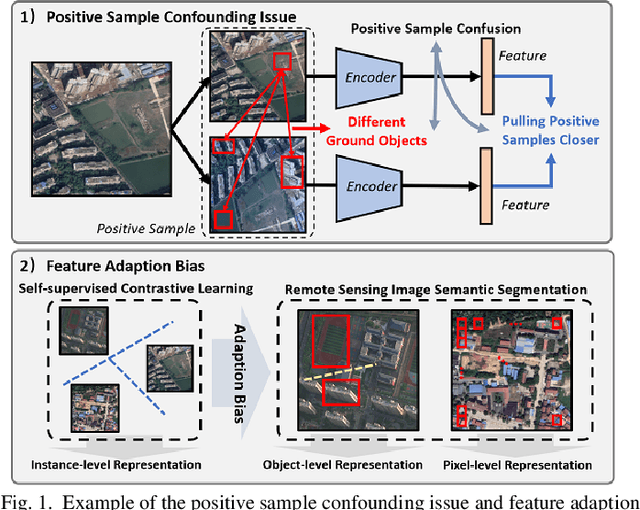

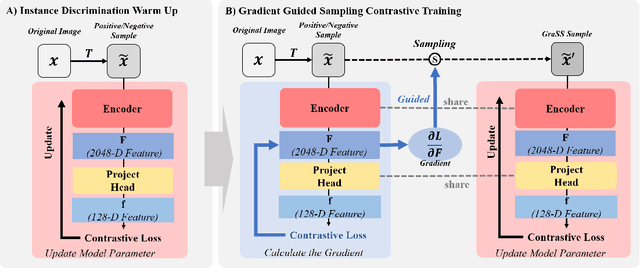
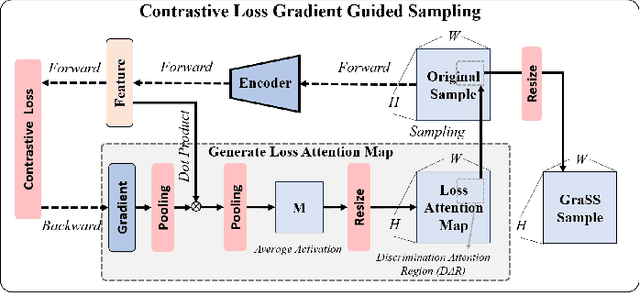
Self-supervised contrastive learning (SSCL) has achieved significant milestones in remote sensing image (RSI) understanding. Its essence lies in designing an unsupervised instance discrimination pretext task to extract image features from a large number of unlabeled images that are beneficial for downstream tasks. However, existing instance discrimination based SSCL suffer from two limitations when applied to the RSI semantic segmentation task: 1) Positive sample confounding issue; 2) Feature adaptation bias. It introduces a feature adaptation bias when applied to semantic segmentation tasks that require pixel-level or object-level features. In this study, We observed that the discrimination information can be mapped to specific regions in RSI through the gradient of unsupervised contrastive loss, these specific regions tend to contain singular ground objects. Based on this, we propose contrastive learning with Gradient guided Sampling Strategy (GraSS) for RSI semantic segmentation. GraSS consists of two stages: Instance Discrimination warm-up (ID warm-up) and Gradient guided Sampling contrastive training (GS training). The ID warm-up aims to provide initial discrimination information to the contrastive loss gradients. The GS training stage aims to utilize the discrimination information contained in the contrastive loss gradients and adaptively select regions in RSI patches that contain more singular ground objects, in order to construct new positive and negative samples. Experimental results on three open datasets demonstrate that GraSS effectively enhances the performance of SSCL in high-resolution RSI semantic segmentation. Compared to seven baseline methods from five different types of SSCL, GraSS achieves an average improvement of 1.57\% and a maximum improvement of 3.58\% in terms of mean intersection over the union. The source code is available at https://github.com/GeoX-Lab/GraSS
Data Augmentation for Environmental Sound Classification Using Diffusion Probabilistic Model with Top-k Selection Discriminator
Apr 04, 2023


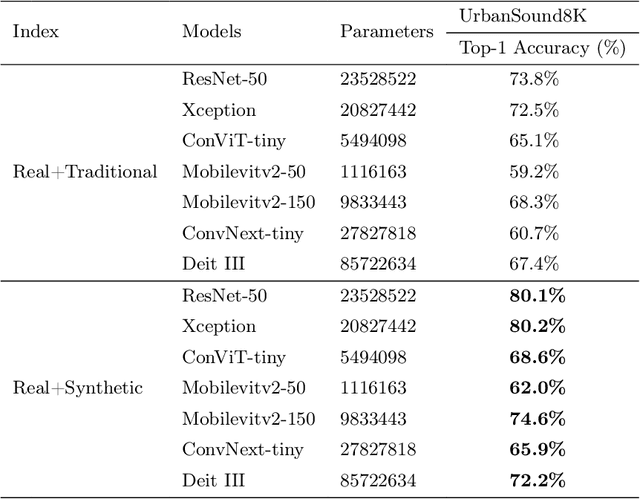
Despite consistent advancement in powerful deep learning techniques in recent years, large amounts of training data are still necessary for the models to avoid overfitting. Synthetic datasets using generative adversarial networks (GAN) have recently been generated to overcome this problem. Nevertheless, despite advancements, GAN-based methods are usually hard to train or fail to generate high-quality data samples. In this paper, we propose an environmental sound classification augmentation technique based on the diffusion probabilistic model with DPM-Solver$++$ for fast sampling. In addition, to ensure the quality of the generated spectrograms, we train a top-k selection discriminator on the dataset. According to the experiment results, the synthesized spectrograms have similar features to the original dataset and can significantly increase the classification accuracy of different state-of-the-art models compared with traditional data augmentation techniques. The public code is available on https://github.com/JNAIC/DPMs-for-Audio-Data-Augmentation.