 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Generative Data Augmentation: A Comprehensive Survey
Sep 30, 2023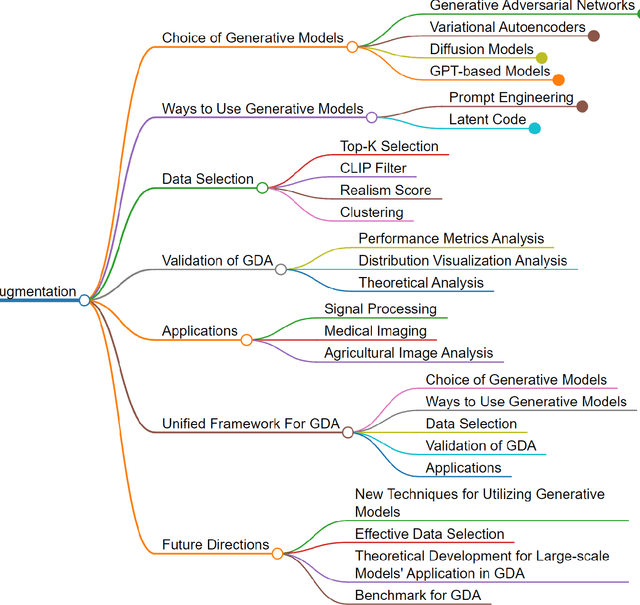

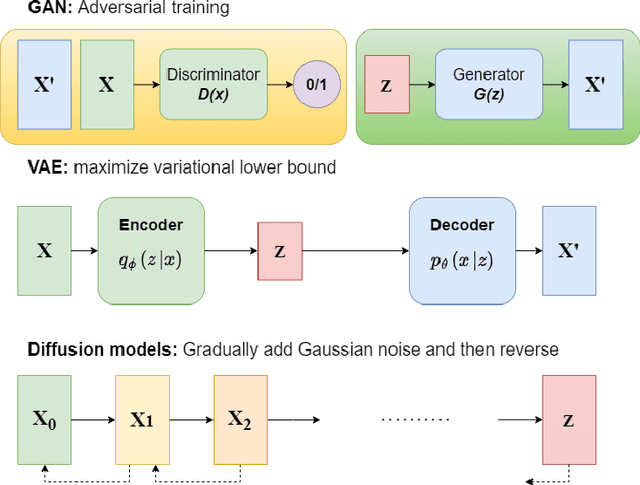
Generative data augmentation (GDA) has emerged as a promising technique to alleviate data scarcity in machine learning applications. This thesis presents a comprehensive survey and unified framework of the GDA landscape. We first provide an overview of GDA, discussing its motivation, taxonomy, and key distinctions from synthetic data generation. We then systematically analyze the critical aspects of GDA - selection of generative models, techniques to utilize them, data selection methodologies, validation approaches, and diverse applications. Our proposed unified framework categorizes the extensive GDA literature, revealing gaps such as the lack of universal benchmarks. The thesis summarises promising research directions, including , effective data selection, theoretical development for large-scale models' application in GDA and establishing a benchmark for GDA. By laying a structured foundation, this thesis aims to nurture more cohesive development and accelerate progress in the vital arena of generative data augmentation.
Adaptive Growth: Real-time CNN Layer Expansion
Sep 06, 2023



Deep Neural Networks (DNNs) have shown unparalleled achievements in numerous applications, reflecting their proficiency in managing vast data sets. Yet, their static structure limits their adaptability in ever-changing environments. This research presents a new algorithm that allows the convolutional layer of a Convolutional Neural Network (CNN) to dynamically evolve based on data input, while still being seamlessly integrated into existing DNNs. Instead of a rigid architecture, our approach iteratively introduces kernels to the convolutional layer, gauging its real-time response to varying data. This process is refined by evaluating the layer's capacity to discern image features, guiding its growth. Remarkably, our unsupervised method has outstripped its supervised counterparts across diverse datasets like MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100. It also showcases enhanced adaptability in transfer learning scenarios. By introducing a data-driven model scalability strategy, we are filling a void in deep learning, leading to more flexible and efficient DNNs suited for dynamic settings. Code:(https://github.com/YunjieZhu/Extensible-Convolutional-Layer-git-version).
Data Augmentation for Environmental Sound Classification Using Diffusion Probabilistic Model with Top-k Selection Discriminator
Apr 04, 2023


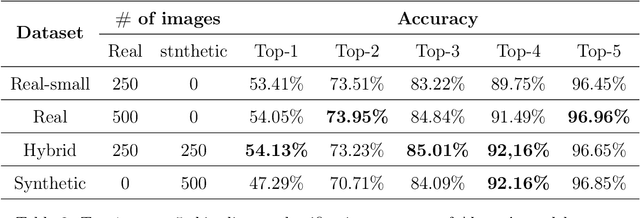
Despite consistent advancement in powerful deep learning techniques in recent years, large amounts of training data are still necessary for the models to avoid overfitting. Synthetic datasets using generative adversarial networks (GAN) have recently been generated to overcome this problem. Nevertheless, despite advancements, GAN-based methods are usually hard to train or fail to generate high-quality data samples. In this paper, we propose an environmental sound classification augmentation technique based on the diffusion probabilistic model with DPM-Solver$++$ for fast sampling. In addition, to ensure the quality of the generated spectrograms, we train a top-k selection discriminator on the dataset. According to the experiment results, the synthesized spectrograms have similar features to the original dataset and can significantly increase the classification accuracy of different state-of-the-art models compared with traditional data augmentation techniques. The public code is available on https://github.com/JNAIC/DPMs-for-Audio-Data-Augmentation.
Effective Audio Classification Network Based on Paired Inverse Pyramid Structure and Dense MLP Block
Nov 05, 2022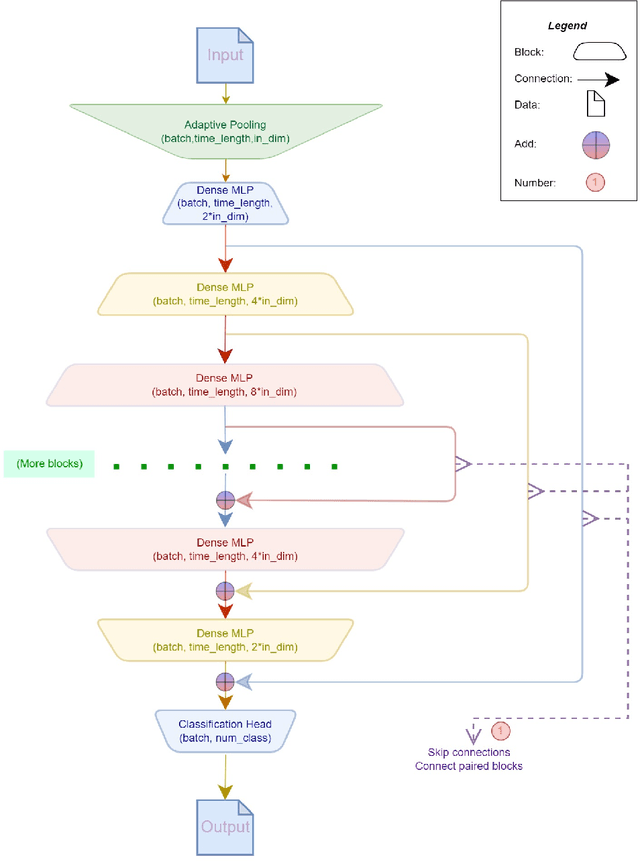
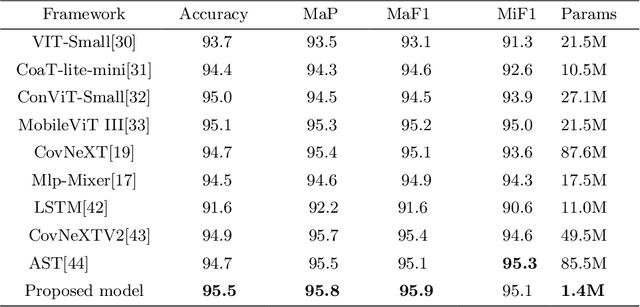
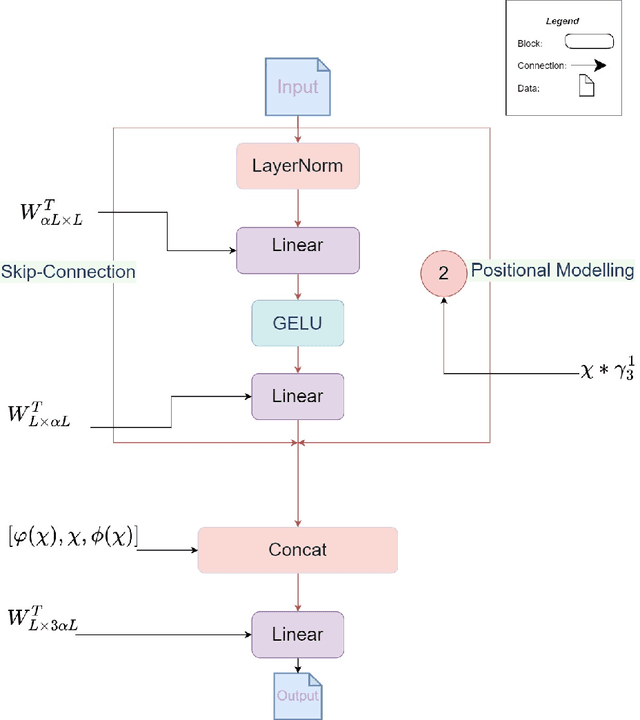
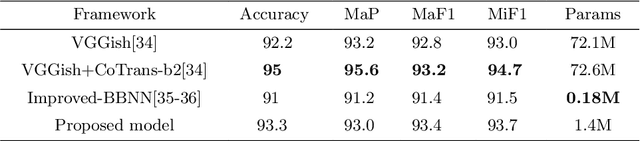
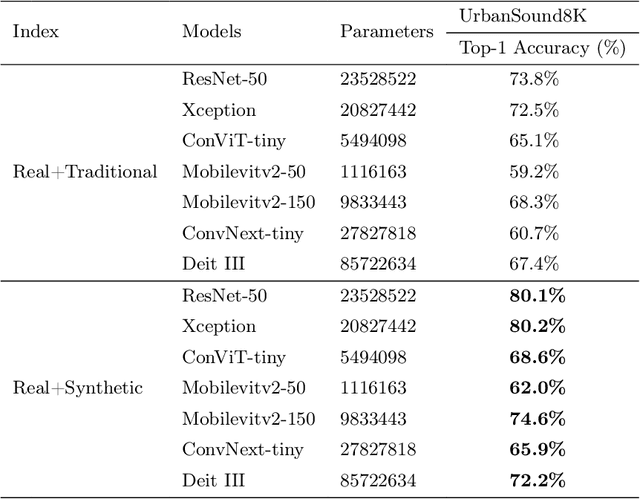
Recently, massive architectures based on Convolutional Neural Network (CNN) and self-attention mechanisms have become necessary for audio classification. While these techniques are state-of-the-art, these works' effectiveness can only be guaranteed with huge computational costs and parameters, large amounts of data augmentation, transfer from large datasets and some other tricks. By utilizing the lightweight nature of audio, we propose an efficient network structure called Paired Inverse Pyramid Structure (PIP) and a network called Paired Inverse Pyramid Structure MLP Network (PIPMN). The PIPMN reaches 96\% of Environmental Sound Classification (ESC) accuracy on the UrbanSound8K dataset and 93.2\% of Music Genre Classification (MGC) on the GTAZN dataset, with only 1 million parameters. Both of the results are achieved without data augmentation or model transfer. Public code is available at: https://github.com/JNAIC/PIPMN