 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Audio Classification Network Based on Paired Inverse Pyramid Structure and Dense MLP Block
Nov 05, 2022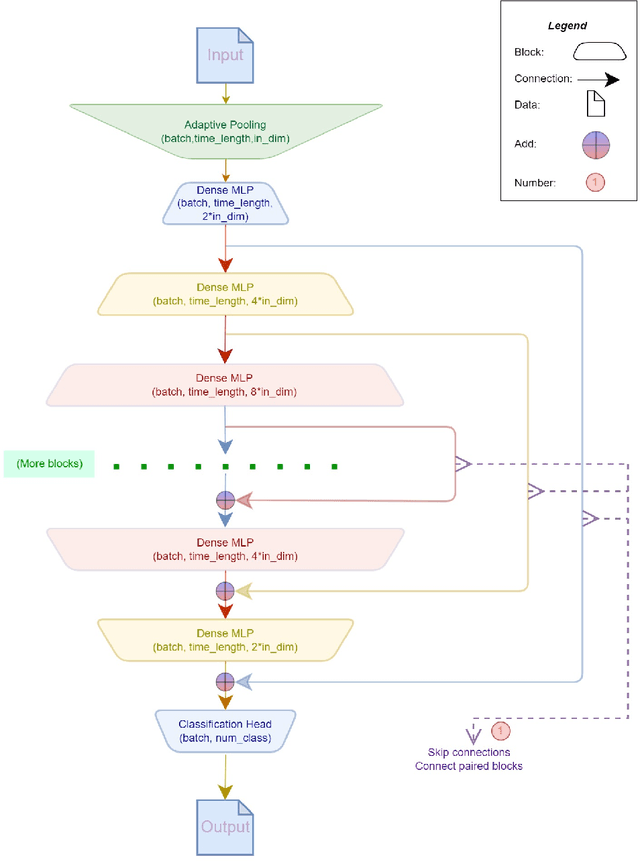
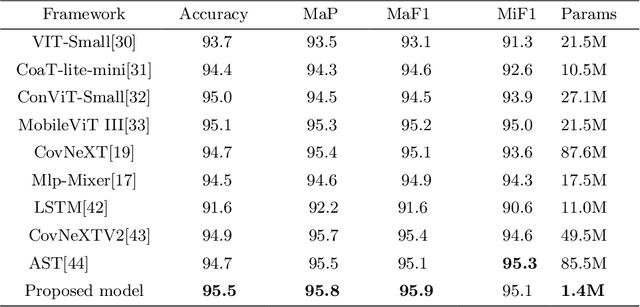
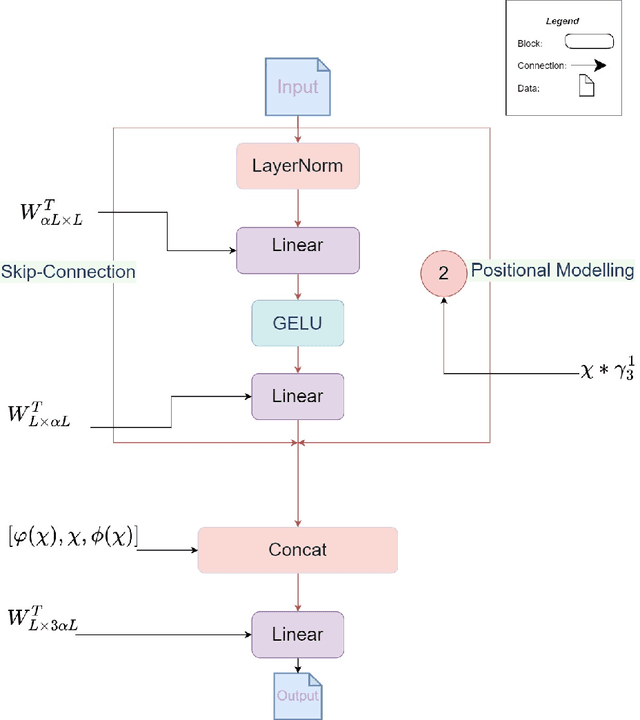
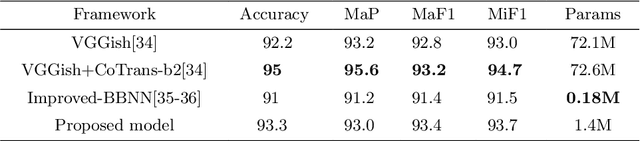
Recently, massive architectures based on Convolutional Neural Network (CNN) and self-attention mechanisms have become necessary for audio classification. While these techniques are state-of-the-art, these works' effectiveness can only be guaranteed with huge computational costs and parameters, large amounts of data augmentation, transfer from large datasets and some other tricks. By utilizing the lightweight nature of audio, we propose an efficient network structure called Paired Inverse Pyramid Structure (PIP) and a network called Paired Inverse Pyramid Structure MLP Network (PIPMN). The PIPMN reaches 96\% of Environmental Sound Classification (ESC) accuracy on the UrbanSound8K dataset and 93.2\% of Music Genre Classification (MGC) on the GTAZN dataset, with only 1 million parameters. Both of the results are achieved without data augmentation or model transfer. Public code is available at: https://github.com/JNAIC/PIPMN