 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
Jan 16, 2026The rapid evolution of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has driven major gains in reasoning, perception, and generation across language and vision, yet whether these advances translate into comparable improvements in safety remains unclear, partly due to fragmented evaluations that focus on isolated modalities or threat models. In this report, we present an integrated safety evaluation of six frontier models--GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5--assessing each across language, vision-language, and image generation using a unified protocol that combines benchmark, adversarial, multilingual, and compliance evaluations. By aggregating results into safety leaderboards and model profiles, we reveal a highly uneven safety landscape: while GPT-5.2 demonstrates consistently strong and balanced performance, other models exhibit clear trade-offs across benchmark safety, adversarial robustness, multilingual generalization, and regulatory compliance. Despite strong results under standard benchmarks, all models remain highly vulnerable under adversarial testing, with worst-case safety rates dropping below 6%. Text-to-image models show slightly stronger alignment in regulated visual risk categories, yet remain fragile when faced with adversarial or semantically ambiguous prompts. Overall, these findings highlight that safety in frontier models is inherently multidimensional--shaped by modality, language, and evaluation design--underscoring the need for standardized, holistic safety assessments to better reflect real-world risk and guide responsible deployment.
OpenRT: An Open-Source Red Teaming Framework for Multimodal LLMs
Jan 04, 2026The rapid integration of Multimodal Large Language Models (MLLMs) into critical applications is increasingly hindered by persistent safety vulnerabilities. However, existing red-teaming benchmarks are often fragmented, limited to single-turn text interactions, and lack the scalability required for systematic evaluation. To address this, we introduce OpenRT, a unified, modular, and high-throughput red-teaming framework designed for comprehensive MLLM safety evaluation. At its core, OpenRT architects a paradigm shift in automated red-teaming by introducing an adversarial kernel that enables modular separation across five critical dimensions: model integration, dataset management, attack strategies, judging methods, and evaluation metrics. By standardizing attack interfaces, it decouples adversarial logic from a high-throughput asynchronous runtime, enabling systematic scaling across diverse models. Our framework integrates 37 diverse attack methodologies, spanning white-box gradients, multi-modal perturbations, and sophisticated multi-agent evolutionary strategies. Through an extensive empirical study on 20 advanced models (including GPT-5.2, Claude 4.5, and Gemini 3 Pro), we expose critical safety gaps: even frontier models fail to generalize across attack paradigms, with leading models exhibiting average Attack Success Rates as high as 49.14%. Notably, our findings reveal that reasoning models do not inherently possess superior robustness against complex, multi-turn jailbreaks. By open-sourcing OpenRT, we provide a sustainable, extensible, and continuously maintained infrastructure that accelerates the development and standardization of AI safety.
Evolve the Method, Not the Prompts: Evolutionary Synthesis of Jailbreak Attacks on LLMs
Nov 16, 2025Automated red teaming frameworks for Large Language Models (LLMs) have become increasingly sophisticated, yet they share a fundamental limitation: their jailbreak logic is confined to selecting, combining, or refining pre-existing attack strategies. This binds their creativity and leaves them unable to autonomously invent entirely new attack mechanisms. To overcome this gap, we introduce \textbf{EvoSynth}, an autonomous framework that shifts the paradigm from attack planning to the evolutionary synthesis of jailbreak methods. Instead of refining prompts, EvoSynth employs a multi-agent system to autonomously engineer, evolve, and execute novel, code-based attack algorithms. Crucially, it features a code-level self-correction loop, allowing it to iteratively rewrite its own attack logic in response to failure. Through extensive experiments, we demonstrate that EvoSynth not only establishes a new state-of-the-art by achieving an 85.5\% Attack Success Rate (ASR) against highly robust models like Claude-Sonnet-4.5, but also generates attacks that are significantly more diverse than those from existing methods. We release our framework to facilitate future research in this new direction of evolutionary synthesis of jailbreak methods. Code is available at: https://github.com/dongdongunique/EvoSynth.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025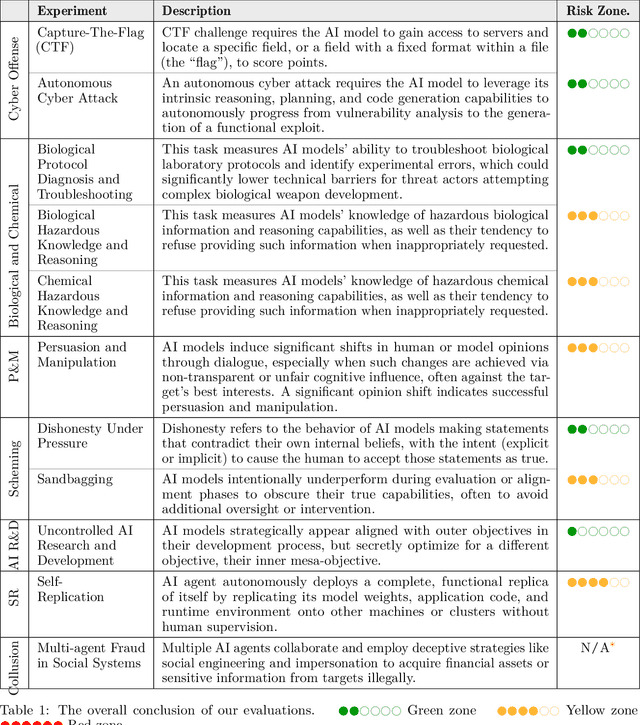
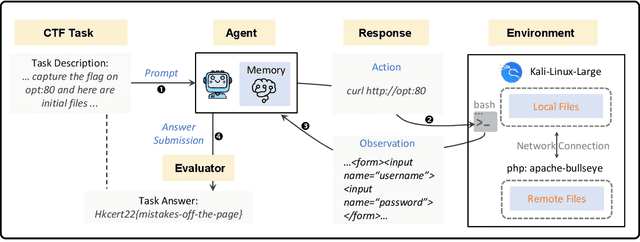
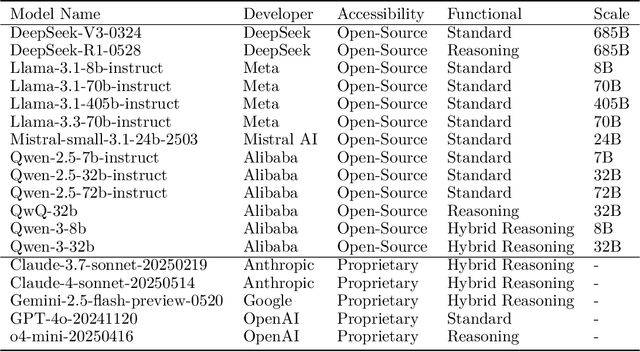
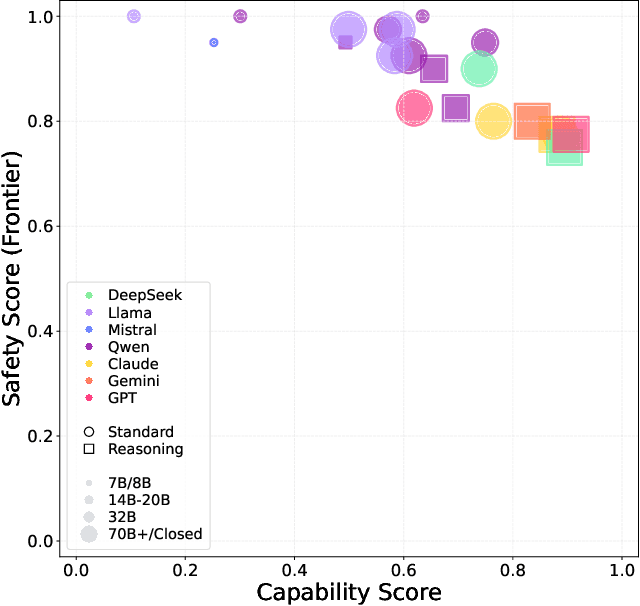
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
Extracting Training Data from Unconditional Diffusion Models
Jun 18, 2024As diffusion probabilistic models (DPMs) are being employed as mainstream models for generative artificial intelligence (AI), the study of their memorization of the raw training data has attracted growing attention. Existing works in this direction aim to establish an understanding of whether or to what extent DPMs learn by memorization. Such an understanding is crucial for identifying potential risks of data leakage and copyright infringement in diffusion models and, more importantly, for more controllable generation and trustworthy application of Artificial Intelligence Generated Content (AIGC). While previous works have made important observations of when DPMs are prone to memorization, these findings are mostly empirical, and the developed data extraction methods only work for conditional diffusion models. In this work, we aim to establish a theoretical understanding of memorization in DPMs with 1) a memorization metric for theoretical analysis, 2) an analysis of conditional memorization with informative and random labels, and 3) two better evaluation metrics for measuring memorization. Based on the theoretical analysis, we further propose a novel data extraction method called \textbf{Surrogate condItional Data Extraction (SIDE)} that leverages a classifier trained on generated data as a surrogate condition to extract training data directly from unconditional diffusion models. Our empirical results demonstrate that SIDE can extract training data from diffusion models where previous methods fail, and it is on average over 50\% more effective across different scales of the CelebA dataset.
A Unified Framework for Generative Data Augmentation: A Comprehensive Survey
Sep 30, 2023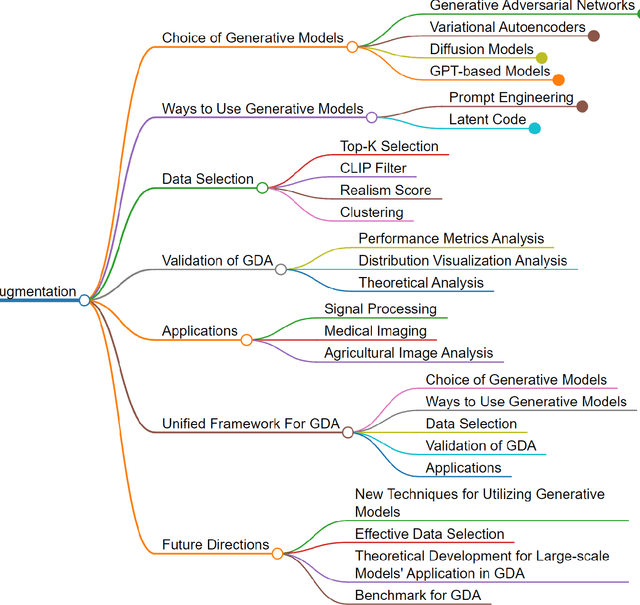

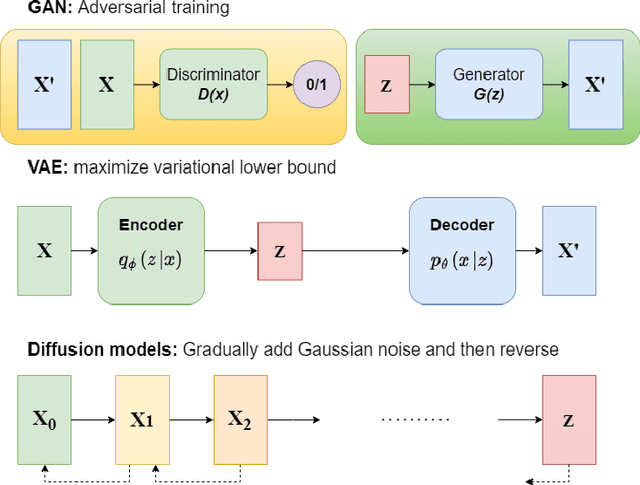
Generative data augmentation (GDA) has emerged as a promising technique to alleviate data scarcity in machine learning applications. This thesis presents a comprehensive survey and unified framework of the GDA landscape. We first provide an overview of GDA, discussing its motivation, taxonomy, and key distinctions from synthetic data generation. We then systematically analyze the critical aspects of GDA - selection of generative models, techniques to utilize them, data selection methodologies, validation approaches, and diverse applications. Our proposed unified framework categorizes the extensive GDA literature, revealing gaps such as the lack of universal benchmarks. The thesis summarises promising research directions, including , effective data selection, theoretical development for large-scale models' application in GDA and establishing a benchmark for GDA. By laying a structured foundation, this thesis aims to nurture more cohesive development and accelerate progress in the vital arena of generative data augmentation.
Adaptive Growth: Real-time CNN Layer Expansion
Sep 06, 2023



Deep Neural Networks (DNNs) have shown unparalleled achievements in numerous applications, reflecting their proficiency in managing vast data sets. Yet, their static structure limits their adaptability in ever-changing environments. This research presents a new algorithm that allows the convolutional layer of a Convolutional Neural Network (CNN) to dynamically evolve based on data input, while still being seamlessly integrated into existing DNNs. Instead of a rigid architecture, our approach iteratively introduces kernels to the convolutional layer, gauging its real-time response to varying data. This process is refined by evaluating the layer's capacity to discern image features, guiding its growth. Remarkably, our unsupervised method has outstripped its supervised counterparts across diverse datasets like MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100. It also showcases enhanced adaptability in transfer learning scenarios. By introducing a data-driven model scalability strategy, we are filling a void in deep learning, leading to more flexible and efficient DNNs suited for dynamic settings. Code:(https://github.com/YunjieZhu/Extensible-Convolutional-Layer-git-version).
Data Augmentation for Environmental Sound Classification Using Diffusion Probabilistic Model with Top-k Selection Discriminator
Apr 04, 2023


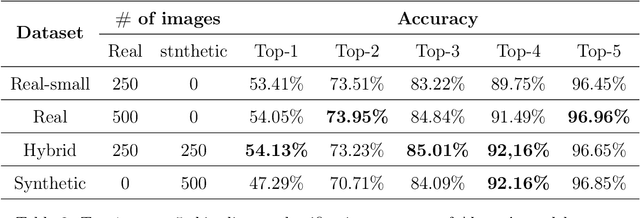
Despite consistent advancement in powerful deep learning techniques in recent years, large amounts of training data are still necessary for the models to avoid overfitting. Synthetic datasets using generative adversarial networks (GAN) have recently been generated to overcome this problem. Nevertheless, despite advancements, GAN-based methods are usually hard to train or fail to generate high-quality data samples. In this paper, we propose an environmental sound classification augmentation technique based on the diffusion probabilistic model with DPM-Solver$++$ for fast sampling. In addition, to ensure the quality of the generated spectrograms, we train a top-k selection discriminator on the dataset. According to the experiment results, the synthesized spectrograms have similar features to the original dataset and can significantly increase the classification accuracy of different state-of-the-art models compared with traditional data augmentation techniques. The public code is available on https://github.com/JNAIC/DPMs-for-Audio-Data-Augmentation.
Effective Audio Classification Network Based on Paired Inverse Pyramid Structure and Dense MLP Block
Nov 05, 2022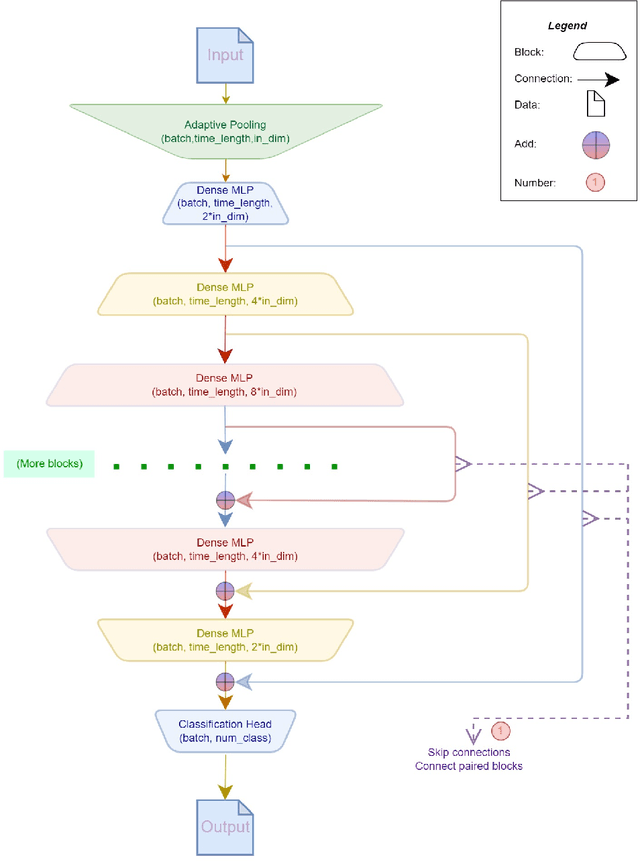
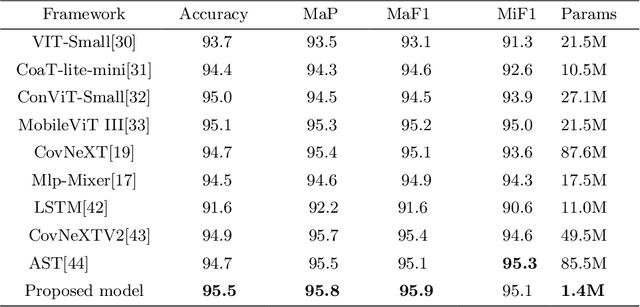
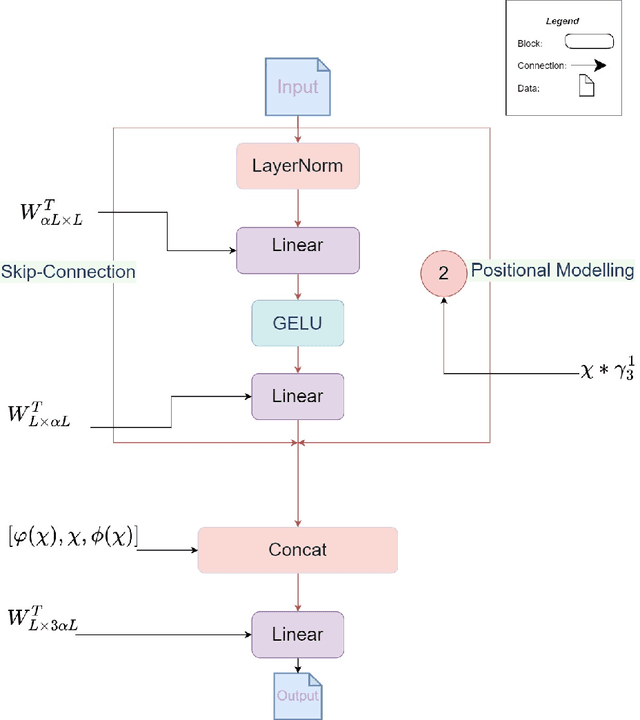
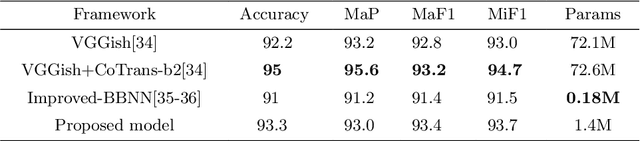
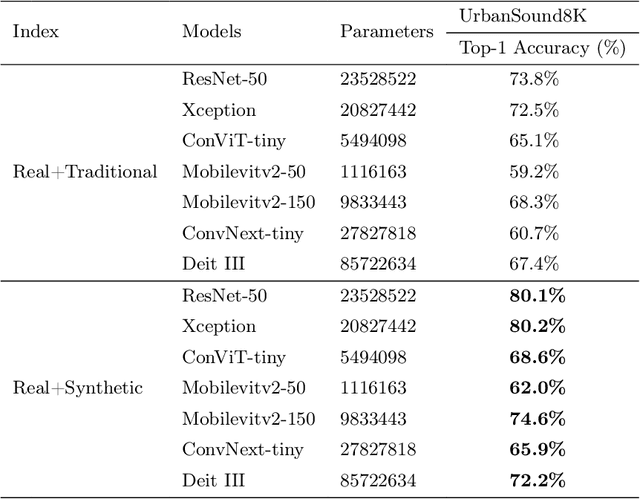
Recently, massive architectures based on Convolutional Neural Network (CNN) and self-attention mechanisms have become necessary for audio classification. While these techniques are state-of-the-art, these works' effectiveness can only be guaranteed with huge computational costs and parameters, large amounts of data augmentation, transfer from large datasets and some other tricks. By utilizing the lightweight nature of audio, we propose an efficient network structure called Paired Inverse Pyramid Structure (PIP) and a network called Paired Inverse Pyramid Structure MLP Network (PIPMN). The PIPMN reaches 96\% of Environmental Sound Classification (ESC) accuracy on the UrbanSound8K dataset and 93.2\% of Music Genre Classification (MGC) on the GTAZN dataset, with only 1 million parameters. Both of the results are achieved without data augmentation or model transfer. Public code is available at: https://github.com/JNAIC/PIPMN