 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual LLM Upcycling: A Predictor-Gated Bank-Wise Sparsity Training Recipe for Dense-to-Sparse LLMs
Jun 09, 2026We study dense-to-sparse continual training as a way to construct channel-sparse large language models from dense checkpoints. Starting from a Qwen2.5-8B dense backbone, we continue training at 32K context and introduce a predictor-gated sparse SwiGLU FFN in the 32K stage. For each token and layer, we use a low-rank predictor to produce FFN-channel routing logits. We then apply a bank-wise top-k rule to retain 16 channels in every 64-channel bank, yielding 4x sparsity in the FFN intermediate activation. Unlike post-hoc sparse inference methods, the routing module is placed on the main language modeling path and optimized during continual training, enabling the dense model to be upcycled into a hardware-oriented sparse model. We report the architecture, training recipe, benchmark performance, and training lessons. We also identify a layer-local long-context failure mode on RULER-CWE and propose a single-layer repair algorithm that substantially improves the affected length range.
From Noise to Intent: Anchoring Generative VLA Policies with Residual Bridges
Apr 23, 2026Bridging high-level semantic understanding with low-level physical control remains a persistent challenge in embodied intelligence, stemming from the fundamental spatiotemporal scale mismatch between cognition and action. Existing generative VLA policies typically adopt a "Generation-from-Noise" paradigm, which disregards this disparity, leading to representation inefficiency and weak condition alignment during optimization. In this work, we propose ResVLA, an architecture that shifts the paradigm to "Refinement-from-Intent." Recognizing that robotic motion naturally decomposes into global intent and local dynamics, ResVLA utilizes spectral analysis to decouple control into a deterministic low-frequency anchor and a stochastic high-frequency residual. By anchoring the generative process on the predicted intent, our model focuses strictly on refining local dynamics via a residual diffusion bridge. Extensive simulation experiments show that ResVLA achieves competitive performance, strong robustness to language and robot embodiment perturbations, and faster convergence than standard generative baselines. It also demonstrates strong performance in real-world robot experiments.
LLM-Bootstrapped Targeted Finding Guidance for Factual MLLM-based Medical Report Generation
Feb 28, 2026The automatic generation of medical reports utilizing Multimodal Large Language Models (MLLMs) frequently encounters challenges related to factual instability, which may manifest as the omission of findings or the incorporation of inaccurate information, thereby constraining their applicability in clinical settings. Current methodologies typically produce reports based directly on image features, which inherently lack a definitive factual basis. In response to this limitation, we introduce Fact-Flow, an innovative framework that separates the process of visual fact identification from the generation of reports. This is achieved by initially predicting clinical findings from the image, which subsequently directs the MLLM to produce a report that is factually precise. A pivotal advancement of our approach is a pipeline that leverages a Large Language Model (LLM) to autonomously create a dataset of labeled medical findings, effectively eliminating the need for expensive manual annotation. Extensive experimental evaluations conducted on two disease-focused medical datasets validate the efficacy of our method, demonstrating a significant enhancement in factual accuracy compared to state-of-the-art models, while concurrently preserving high standards of text quality.
Casting a SPELL: Sentence Pairing Exploration for LLM Limitation-breaking
Dec 24, 2025Large language models (LLMs) have revolutionized software development through AI-assisted coding tools, enabling developers with limited programming expertise to create sophisticated applications. However, this accessibility extends to malicious actors who may exploit these powerful tools to generate harmful software. Existing jailbreaking research primarily focuses on general attack scenarios against LLMs, with limited exploration of malicious code generation as a jailbreak target. To address this gap, we propose SPELL, a comprehensive testing framework specifically designed to evaluate the weakness of security alignment in malicious code generation. Our framework employs a time-division selection strategy that systematically constructs jailbreaking prompts by intelligently combining sentences from a prior knowledge dataset, balancing exploration of novel attack patterns with exploitation of successful techniques. Extensive evaluation across three advanced code models (GPT-4.1, Claude-3.5, and Qwen2.5-Coder) demonstrates SPELL's effectiveness, achieving attack success rates of 83.75%, 19.38%, and 68.12% respectively across eight malicious code categories. The generated prompts successfully produce malicious code in real-world AI development tools such as Cursor, with outputs confirmed as malicious by state-of-the-art detection systems at rates exceeding 73%. These findings reveal significant security gaps in current LLM implementations and provide valuable insights for improving AI safety alignment in code generation applications.
Multimodal Magic Elevating Depression Detection with a Fusion of Text and Audio Intelligence
Jan 31, 2025This study proposes an innovative multimodal fusion model based on a teacher-student architecture to enhance the accuracy of depression classification. Our designed model addresses the limitations of traditional methods in feature fusion and modality weight allocation by introducing multi-head attention mechanisms and weighted multimodal transfer learning. Leveraging the DAIC-WOZ dataset, the student fusion model, guided by textual and auditory teacher models, achieves significant improvements in classification accuracy. Ablation experiments demonstrate that the proposed model attains an F1 score of 99. 1% on the test set, significantly outperforming unimodal and conventional approaches. Our method effectively captures the complementarity between textual and audio features while dynamically adjusting the contributions of the teacher models to enhance generalization capabilities. The experimental results highlight the robustness and adaptability of the proposed framework in handling complex multimodal data. This research provides a novel technical framework for multimodal large model learning in depression analysis, offering new insights into addressing the limitations of existing methods in modality fusion and feature extraction.
Optical Wireless Communications: Enabling the Next Generation Network of Networks
Dec 21, 2024



Optical wireless communication (OWC) is a promising technology anticipated to play a key role in the next-generation network of networks. To this end, this paper details the potential of OWC, as a complementary technology to traditional radio frequency communications, in enhancing networking capabilities beyond conventional terrestrial networks. Several usage scenarios and the current state of development are presented. Furthermore, a summary of existing challenges and opportunities are provided. Emerging technologies aimed at further enhancing future OWC capabilities are introduced. Additionally, value-added OWC-based technologies that leverage the unique properties of light are discussed, including applications such as positioning and gesture recognition. The paper concludes with the reflection that OWC provides unique functionalities that can play a crucial role in building convergent and resilient future network of networks.
Flexible and Scalable Deep Dendritic Spiking Neural Networks with Multiple Nonlinear Branching
Dec 09, 2024Recent advances in spiking neural networks (SNNs) have a predominant focus on network architectures, while relatively little attention has been paid to the underlying neuron model. The point neuron models, a cornerstone of deep SNNs, pose a bottleneck on the network-level expressivity since they depict somatic dynamics only. In contrast, the multi-compartment models in neuroscience offer remarkable expressivity by introducing dendritic morphology and dynamics, but remain underexplored in deep learning due to their unaffordable computational cost and inflexibility. To combine the advantages of both sides for a flexible, efficient yet more powerful model, we propose the dendritic spiking neuron (DendSN) incorporating multiple dendritic branches with nonlinear dynamics. Compared to the point spiking neurons, DendSN exhibits significantly higher expressivity. DendSN's flexibility enables its seamless integration into diverse deep SNN architectures. To accelerate dendritic SNNs (DendSNNs), we parallelize dendritic state updates across time steps, and develop Triton kernels for GPU-level acceleration. As a result, we can construct large-scale DendSNNs with depth comparable to their point SNN counterparts. Next, we comprehensively evaluate DendSNNs' performance on various demanding tasks. By modulating dendritic branch strengths using a context signal, catastrophic forgetting of DendSNNs is substantially mitigated. Moreover, DendSNNs demonstrate enhanced robustness against noise and adversarial attacks compared to point SNNs, and excel in few-shot learning settings. Our work firstly demonstrates the possibility of training bio-plausible dendritic SNNs with depths and scales comparable to traditional point SNNs, and reveals superior expressivity and robustness of reduced dendritic neuron models in deep learning, thereby offering a fresh perspective on advancing neural network design.
Comprehensive Online Training and Deployment for Spiking Neural Networks
Oct 10, 2024Spiking Neural Networks (SNNs) are considered to have enormous potential in the future development of Artificial Intelligence (AI) due to their brain-inspired and energy-efficient properties. In the current supervised learning domain of SNNs, compared to vanilla Spatial-Temporal Back-propagation (STBP) training, online training can effectively overcome the risk of GPU memory explosion and has received widespread academic attention. However, the current proposed online training methods cannot tackle the inseparability problem of temporal dependent gradients and merely aim to optimize the training memory, resulting in no performance advantages compared to the STBP training models in the inference phase. To address the aforementioned challenges, we propose Efficient Multi-Precision Firing (EM-PF) model, which is a family of advanced spiking models based on floating-point spikes and binary synaptic weights. We point out that EM-PF model can effectively separate temporal gradients and achieve full-stage optimization towards computation speed and memory footprint. Experimental results have demonstrated that EM-PF model can be flexibly combined with various techniques including random back-propagation, parallel computation and channel attention mechanism, to achieve state-of-the-art performance with extremely low computational overhead in the field of online learning.
SCUNet++: Swin-UNet and CNN Bottleneck Hybrid Architecture with Multi-Fusion Dense Skip Connection for Pulmonary Embolism CT Image Segmentation
Jan 03, 2024Pulmonary embolism (PE) is a prevalent lung disease that can lead to right ventricular hypertrophy and failure in severe cases, ranking second in severity only to myocardial infarction and sudden death. Pulmonary artery CT angiography (CTPA) is a widely used diagnostic method for PE. However, PE detection presents challenges in clinical practice due to limitations in imaging technology. CTPA can produce noises similar to PE, making confirmation of its presence time-consuming and prone to overdiagnosis. Nevertheless, the traditional segmentation method of PE can not fully consider the hierarchical structure of features, local and global spatial features of PE CT images. In this paper, we propose an automatic PE segmentation method called SCUNet++ (Swin Conv UNet++). This method incorporates multiple fusion dense skip connections between the encoder and decoder, utilizing the Swin Transformer as the encoder. And fuses features of different scales in the decoder subnetwork to compensate for spatial information loss caused by the inevitable downsampling in Swin-UNet or other state-of-the-art methods, effectively solving the above problem. We provide a theoretical analysis of this method in detail and validate it on publicly available PE CT image datasets FUMPE and CAD-PE. The experimental results indicate that our proposed method achieved a Dice similarity coefficient (DSC) of 83.47% and a Hausdorff distance 95th percentile (HD95) of 3.83 on the FUMPE dataset, as well as a DSC of 83.42% and an HD95 of 5.10 on the CAD-PE dataset. These findings demonstrate that our method exhibits strong performance in PE segmentation tasks, potentially enhancing the accuracy of automatic segmentation of PE and providing a powerful diagnostic tool for clinical physicians. Our source code and new FUMPE dataset are available at https://github.com/JustlfC03/SCUNet-plusplus.
* 10 pages, 7 figures, accept WACV2024
Data Augmentation for Environmental Sound Classification Using Diffusion Probabilistic Model with Top-k Selection Discriminator
Apr 04, 2023


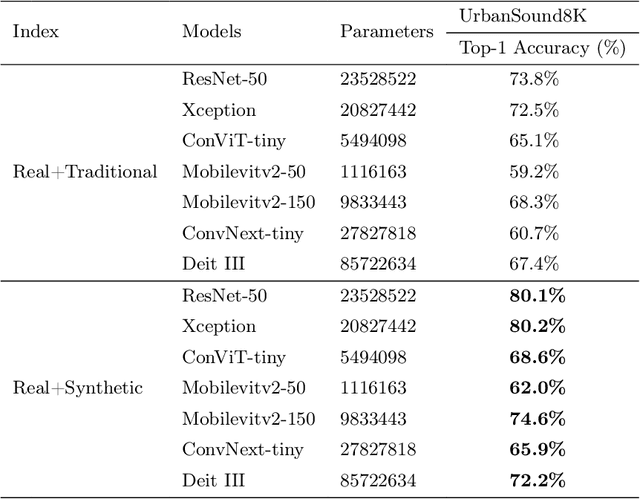
Despite consistent advancement in powerful deep learning techniques in recent years, large amounts of training data are still necessary for the models to avoid overfitting. Synthetic datasets using generative adversarial networks (GAN) have recently been generated to overcome this problem. Nevertheless, despite advancements, GAN-based methods are usually hard to train or fail to generate high-quality data samples. In this paper, we propose an environmental sound classification augmentation technique based on the diffusion probabilistic model with DPM-Solver$++$ for fast sampling. In addition, to ensure the quality of the generated spectrograms, we train a top-k selection discriminator on the dataset. According to the experiment results, the synthesized spectrograms have similar features to the original dataset and can significantly increase the classification accuracy of different state-of-the-art models compared with traditional data augmentation techniques. The public code is available on https://github.com/JNAIC/DPMs-for-Audio-Data-Augmentation.