 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Self-Prediction Enhancement for Spiking Neurons
Jan 29, 2026Spiking Neural Networks (SNNs) are highly energy-efficient due to event-driven, sparse computation, but their training is challenged by spike non-differentiability and trade-offs among performance, efficiency, and biological plausibility. Crucially, mainstream SNNs ignore predictive coding, a core cortical mechanism where the brain predicts inputs and encodes errors for efficient perception. Inspired by this, we propose a self-prediction enhanced spiking neuron method that generates an internal prediction current from its input-output history to modulate membrane potential. This design offers dual advantages, it creates a continuous gradient path that alleviates vanishing gradients and boosts training stability and accuracy, while also aligning with biological principles, which resembles distal dendritic modulation and error-driven synaptic plasticity. Experiments show consistent performance gains across diverse architectures, neuron types, time steps, and tasks demonstrating broad applicability for enhancing SNNs.
Error Amplification Limits ANN-to-SNN Conversion in Continuous Control
Jan 29, 2026Spiking Neural Networks (SNNs) can achieve competitive performance by converting already existing well-trained Artificial Neural Networks (ANNs), avoiding further costly training. This property is particularly attractive in Reinforcement Learning (RL), where training through environment interaction is expensive and potentially unsafe. However, existing conversion methods perform poorly in continuous control, where suitable baselines are largely absent. We identify error amplification as the key cause: small action approximation errors become temporally correlated across decision steps, inducing cumulative state distribution shift and severe performance degradation. To address this issue, we propose Cross-Step Residual Potential Initialization (CRPI), a lightweight training-free mechanism that carries over residual membrane potentials across decision steps to suppress temporally correlated errors. Experiments on continuous control benchmarks with both vector and visual observations demonstrate that CRPI can be integrated into existing conversion pipelines and substantially recovers lost performance. Our results highlight continuous control as a critical and challenging benchmark for ANN-to-SNN conversion, where small errors can be strongly amplified and impact performance.
Unlearning of Knowledge Graph Embedding via Preference Optimization
Jul 28, 2025



Existing knowledge graphs (KGs) inevitably contain outdated or erroneous knowledge that needs to be removed from knowledge graph embedding (KGE) models. To address this challenge, knowledge unlearning can be applied to eliminate specific information while preserving the integrity of the remaining knowledge in KGs. Existing unlearning methods can generally be categorized into exact unlearning and approximate unlearning. However, exact unlearning requires high training costs while approximate unlearning faces two issues when applied to KGs due to the inherent connectivity of triples: (1) It fails to fully remove targeted information, as forgetting triples can still be inferred from remaining ones. (2) It focuses on local data for specific removal, which weakens the remaining knowledge in the forgetting boundary. To address these issues, we propose GraphDPO, a novel approximate unlearning framework based on direct preference optimization (DPO). Firstly, to effectively remove forgetting triples, we reframe unlearning as a preference optimization problem, where the model is trained by DPO to prefer reconstructed alternatives over the original forgetting triples. This formulation penalizes reliance on forgettable knowledge, mitigating incomplete forgetting caused by KG connectivity. Moreover, we introduce an out-boundary sampling strategy to construct preference pairs with minimal semantic overlap, weakening the connection between forgetting and retained knowledge. Secondly, to preserve boundary knowledge, we introduce a boundary recall mechanism that replays and distills relevant information both within and across time steps. We construct eight unlearning datasets across four popular KGs with varying unlearning rates. Experiments show that GraphDPO outperforms state-of-the-art baselines by up to 10.1% in MRR_Avg and 14.0% in MRR_F1.
Proxy Target: Bridging the Gap Between Discrete Spiking Neural Networks and Continuous Control
May 30, 2025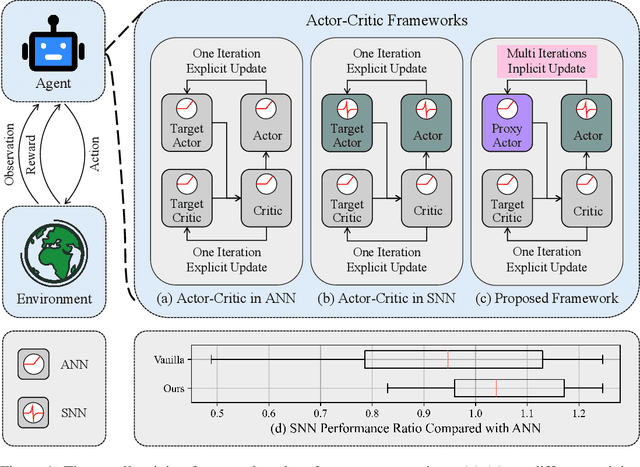
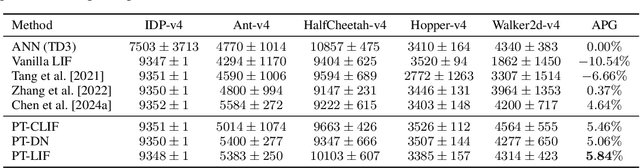
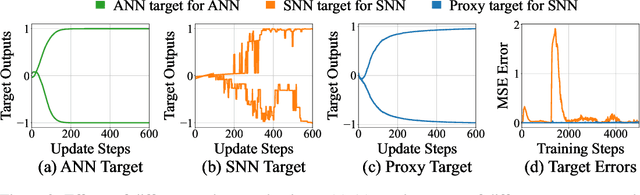

Spiking Neural Networks (SNNs) offer low-latency and energy-efficient decision making through neuromorphic hardware, making them compelling for Reinforcement Learning (RL) in resource-constrained edge devices. Recent studies in this field directly replace Artificial Neural Networks (ANNs) by SNNs in existing RL frameworks, overlooking whether the RL algorithm is suitable for SNNs. However, most RL algorithms in continuous control are designed tailored to ANNs, including the target network soft updates mechanism, which conflict with the discrete, non-differentiable dynamics of SNN spikes. We identify that this mismatch destabilizes SNN training in continuous control tasks. To bridge this gap between discrete SNN and continuous control, we propose a novel proxy target framework. The continuous and differentiable dynamics of the proxy target enable smooth updates, bypassing the incompatibility of SNN spikes, stabilizing the RL algorithms. Since the proxy network operates only during training, the SNN retains its energy efficiency during deployment without inference overhead. Extensive experiments on continuous control benchmarks demonstrate that compared to vanilla SNNs, the proxy target framework enables SNNs to achieve up to 32% higher performance across different spiking neurons. Notably, we are the first to surpass ANN performance in continuous control with simple Leaky-Integrate-and-Fire (LIF) neurons. This work motivates a new class of SNN-friendly RL algorithms tailored to SNN's characteristics, paving the way for neuromorphic agents that combine high performance with low power consumption.
Comprehensive Online Training and Deployment for Spiking Neural Networks
Oct 10, 2024Spiking Neural Networks (SNNs) are considered to have enormous potential in the future development of Artificial Intelligence (AI) due to their brain-inspired and energy-efficient properties. In the current supervised learning domain of SNNs, compared to vanilla Spatial-Temporal Back-propagation (STBP) training, online training can effectively overcome the risk of GPU memory explosion and has received widespread academic attention. However, the current proposed online training methods cannot tackle the inseparability problem of temporal dependent gradients and merely aim to optimize the training memory, resulting in no performance advantages compared to the STBP training models in the inference phase. To address the aforementioned challenges, we propose Efficient Multi-Precision Firing (EM-PF) model, which is a family of advanced spiking models based on floating-point spikes and binary synaptic weights. We point out that EM-PF model can effectively separate temporal gradients and achieve full-stage optimization towards computation speed and memory footprint. Experimental results have demonstrated that EM-PF model can be flexibly combined with various techniques including random back-propagation, parallel computation and channel attention mechanism, to achieve state-of-the-art performance with extremely low computational overhead in the field of online learning.
Fast and Continual Knowledge Graph Embedding via Incremental LoRA
Jul 08, 2024



Continual Knowledge Graph Embedding (CKGE) aims to efficiently learn new knowledge and simultaneously preserve old knowledge. Dominant approaches primarily focus on alleviating catastrophic forgetting of old knowledge but neglect efficient learning for the emergence of new knowledge. However, in real-world scenarios, knowledge graphs (KGs) are continuously growing, which brings a significant challenge to fine-tuning KGE models efficiently. To address this issue, we propose a fast CKGE framework (\model), incorporating an incremental low-rank adapter (\mec) mechanism to efficiently acquire new knowledge while preserving old knowledge. Specifically, to mitigate catastrophic forgetting, \model\ isolates and allocates new knowledge to specific layers based on the fine-grained influence between old and new KGs. Subsequently, to accelerate fine-tuning, \model\ devises an efficient \mec\ mechanism, which embeds the specific layers into incremental low-rank adapters with fewer training parameters. Moreover, \mec\ introduces adaptive rank allocation, which makes the LoRA aware of the importance of entities and adjusts its rank scale adaptively. We conduct experiments on four public datasets and two new datasets with a larger initial scale. Experimental results demonstrate that \model\ can reduce training time by 34\%-49\% while still achieving competitive link prediction performance against state-of-the-art models on four public datasets (average MRR score of 21.0\% vs. 21.1\%).Meanwhile, on two newly constructed datasets, \model\ saves 51\%-68\% training time and improves link prediction performance by 1.5\%.
STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Jun 27, 2024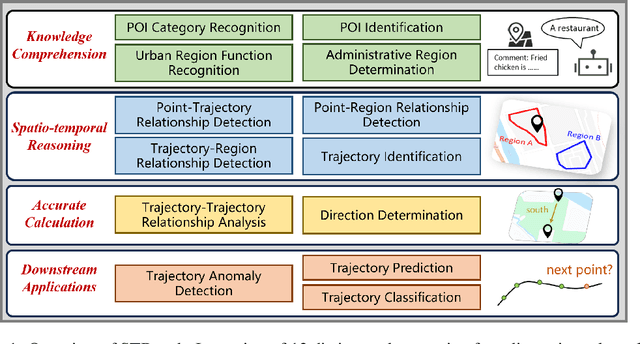

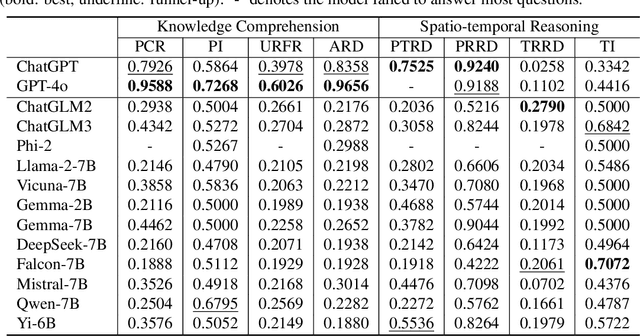
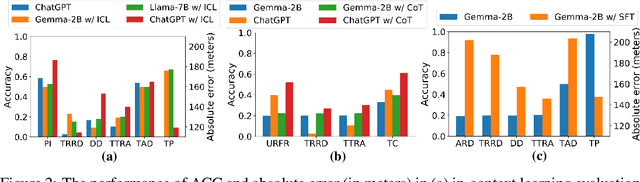
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
Empirical Analysis of Dialogue Relation Extraction with Large Language Models
Apr 27, 2024Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction
Apr 27, 2024
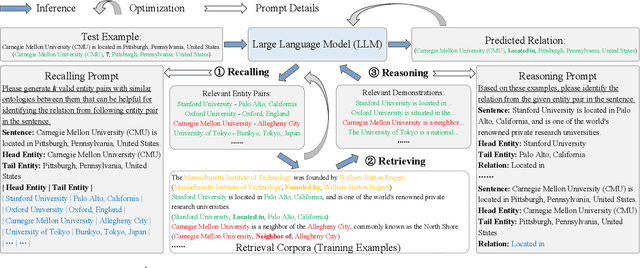
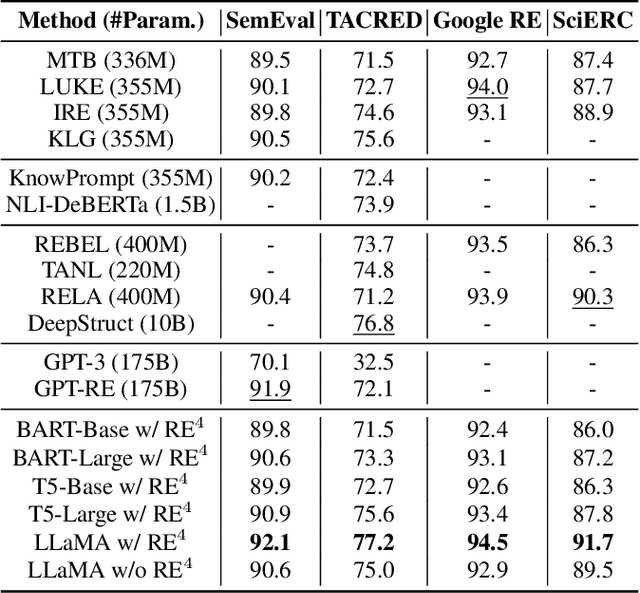
Relation extraction (RE) aims to identify relations between entities mentioned in texts. Although large language models (LLMs) have demonstrated impressive in-context learning (ICL) abilities in various tasks, they still suffer from poor performances compared to most supervised fine-tuned RE methods. Utilizing ICL for RE with LLMs encounters two challenges: (1) retrieving good demonstrations from training examples, and (2) enabling LLMs exhibit strong ICL abilities in RE. On the one hand, retrieving good demonstrations is a non-trivial process in RE, which easily results in low relevance regarding entities and relations. On the other hand, ICL with an LLM achieves poor performance in RE while RE is different from language modeling in nature or the LLM is not large enough. In this work, we propose a novel recall-retrieve-reason RE framework that synergizes LLMs with retrieval corpora (training examples) to enable relevant retrieving and reliable in-context reasoning. Specifically, we distill the consistently ontological knowledge from training datasets to let LLMs generate relevant entity pairs grounded by retrieval corpora as valid queries. These entity pairs are then used to retrieve relevant training examples from the retrieval corpora as demonstrations for LLMs to conduct better ICL via instruction tuning. Extensive experiments on different LLMs and RE datasets demonstrate that our method generates relevant and valid entity pairs and boosts ICL abilities of LLMs, achieving competitive or new state-of-the-art performance on sentence-level RE compared to previous supervised fine-tuning methods and ICL-based methods.
Meta In-Context Learning Makes Large Language Models Better Zero and Few-Shot Relation Extractors
Apr 27, 2024



Relation extraction (RE) is an important task that aims to identify the relationships between entities in texts. While large language models (LLMs) have revealed remarkable in-context learning (ICL) capability for general zero and few-shot learning, recent studies indicate that current LLMs still struggle with zero and few-shot RE. Previous studies are mainly dedicated to design prompt formats and select good examples for improving ICL-based RE. Although both factors are vital for ICL, if one can fundamentally boost the ICL capability of LLMs in RE, the zero and few-shot RE performance via ICL would be significantly improved. To this end, we introduce \textsc{Micre} (\textbf{M}eta \textbf{I}n-\textbf{C}ontext learning of LLMs for \textbf{R}elation \textbf{E}xtraction), a new meta-training framework for zero and few-shot RE where an LLM is tuned to do ICL on a diverse collection of RE datasets (i.e., learning to learn in context for RE). Through meta-training, the model becomes more effectively to learn a new RE task in context by conditioning on a few training examples with no parameter updates or task-specific templates at inference time, enabling better zero and few-shot task generalization. We experiment \textsc{Micre} on various LLMs with different model scales and 12 public RE datasets, and then evaluate it on unseen RE benchmarks under zero and few-shot settings. \textsc{Micre} delivers comparable or superior performance compared to a range of baselines including supervised fine-tuning and typical in-context learning methods. We find that the gains are particular significant for larger model scales, and using a diverse set of the meta-training RE datasets is key to improvements. Empirically, we show that \textsc{Micre} can transfer the relation semantic knowledge via relation label name during inference on target RE datasets.