 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Instructive In-Context Learning with Tabular Prompting for Relational Triple Extraction
Feb 21, 2024

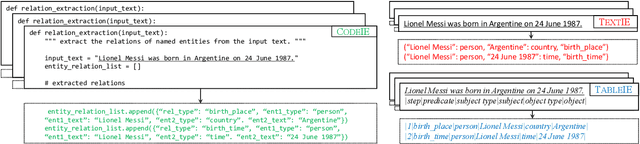
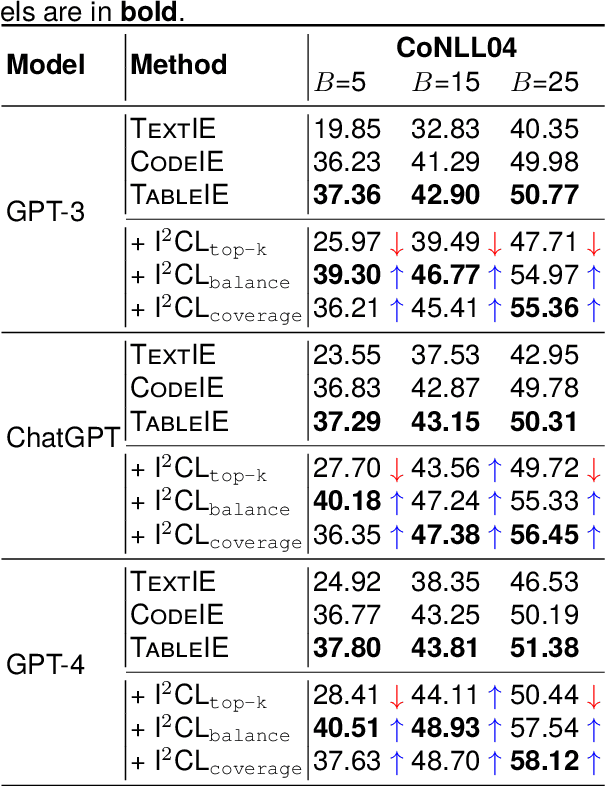
The in-context learning (ICL) for relational triple extraction (RTE) has achieved promising performance, but still encounters two key challenges: (1) how to design effective prompts and (2) how to select proper demonstrations. Existing methods, however, fail to address these challenges appropriately. On the one hand, they usually recast RTE task to text-to-text prompting formats, which is unnatural and results in a mismatch between the output format at the pre-training time and the inference time for large language models (LLMs). On the other hand, they only utilize surface natural language features and lack consideration of triple semantics in sample selection. These issues are blocking improved performance in ICL for RTE, thus we aim to tackle prompt designing and sample selection challenges simultaneously. To this end, we devise a tabular prompting for RTE (\textsc{TableIE}) which frames RTE task into a table generation task to incorporate explicit structured information into ICL, facilitating conversion of outputs to RTE structures. Then we propose instructive in-context learning (I$^2$CL) which only selects and annotates a few samples considering internal triple semantics in massive unlabeled samples.
FastRE: Towards Fast Relation Extraction with Convolutional Encoder and Improved Cascade Binary Tagging Framework
May 05, 2022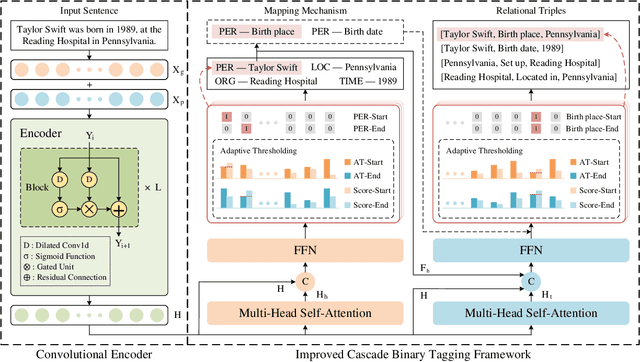
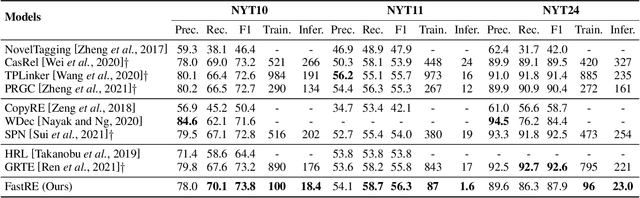
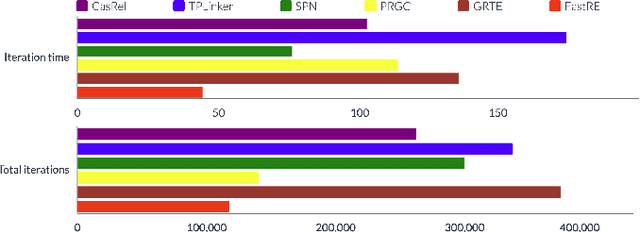
Recent work for extracting relations from texts has achieved excellent performance. However, most existing methods pay less attention to the efficiency, making it still challenging to quickly extract relations from massive or streaming text data in realistic scenarios. The main efficiency bottleneck is that these methods use a Transformer-based pre-trained language model for encoding, which heavily affects the training speed and inference speed. To address this issue, we propose a fast relation extraction model (FastRE) based on convolutional encoder and improved cascade binary tagging framework. Compared to previous work, FastRE employs several innovations to improve efficiency while also keeping promising performance. Concretely, FastRE adopts a novel convolutional encoder architecture combined with dilated convolution, gated unit and residual connection, which significantly reduces the computation cost of training and inference, while maintaining the satisfactory performance. Moreover, to improve the cascade binary tagging framework, FastRE first introduces a type-relation mapping mechanism to accelerate tagging efficiency and alleviate relation redundancy, and then utilizes a position-dependent adaptive thresholding strategy to obtain higher tagging accuracy and better model generalization. Experimental results demonstrate that FastRE is well balanced between efficiency and performance, and achieves 3-10x training speed, 7-15x inference speed faster, and 1/100 parameters compared to the state-of-the-art models, while the performance is still competitive.