 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMMD: A pose-guided multi-view multi-modal diffusion for person generation
Dec 17, 2025



Generating consistent human images with controllable pose and appearance is essential for applications in virtual try on, image editing, and digital human creation. Current methods often suffer from occlusions, garment style drift, and pose misalignment. We propose Pose-guided Multi-view Multimodal Diffusion (PMMD), a diffusion framework that synthesizes photorealistic person images conditioned on multi-view references, pose maps, and text prompts. A multimodal encoder jointly models visual views, pose features, and semantic descriptions, which reduces cross modal discrepancy and improves identity fidelity. We further design a ResCVA module to enhance local detail while preserving global structure, and a cross modal fusion module that integrates image semantics with text throughout the denoising pipeline. Experiments on the DeepFashion MultiModal dataset show that PMMD outperforms representative baselines in consistency, detail preservation, and controllability. Project page and code are available at https://github.com/ZANMANGLOOPYE/PMMD.
Unlearning of Knowledge Graph Embedding via Preference Optimization
Jul 28, 2025



Existing knowledge graphs (KGs) inevitably contain outdated or erroneous knowledge that needs to be removed from knowledge graph embedding (KGE) models. To address this challenge, knowledge unlearning can be applied to eliminate specific information while preserving the integrity of the remaining knowledge in KGs. Existing unlearning methods can generally be categorized into exact unlearning and approximate unlearning. However, exact unlearning requires high training costs while approximate unlearning faces two issues when applied to KGs due to the inherent connectivity of triples: (1) It fails to fully remove targeted information, as forgetting triples can still be inferred from remaining ones. (2) It focuses on local data for specific removal, which weakens the remaining knowledge in the forgetting boundary. To address these issues, we propose GraphDPO, a novel approximate unlearning framework based on direct preference optimization (DPO). Firstly, to effectively remove forgetting triples, we reframe unlearning as a preference optimization problem, where the model is trained by DPO to prefer reconstructed alternatives over the original forgetting triples. This formulation penalizes reliance on forgettable knowledge, mitigating incomplete forgetting caused by KG connectivity. Moreover, we introduce an out-boundary sampling strategy to construct preference pairs with minimal semantic overlap, weakening the connection between forgetting and retained knowledge. Secondly, to preserve boundary knowledge, we introduce a boundary recall mechanism that replays and distills relevant information both within and across time steps. We construct eight unlearning datasets across four popular KGs with varying unlearning rates. Experiments show that GraphDPO outperforms state-of-the-art baselines by up to 10.1% in MRR_Avg and 14.0% in MRR_F1.
Domain-Hierarchy Adaptation via Chain of Iterative Reasoning for Few-shot Hierarchical Text Classification
Jul 12, 2024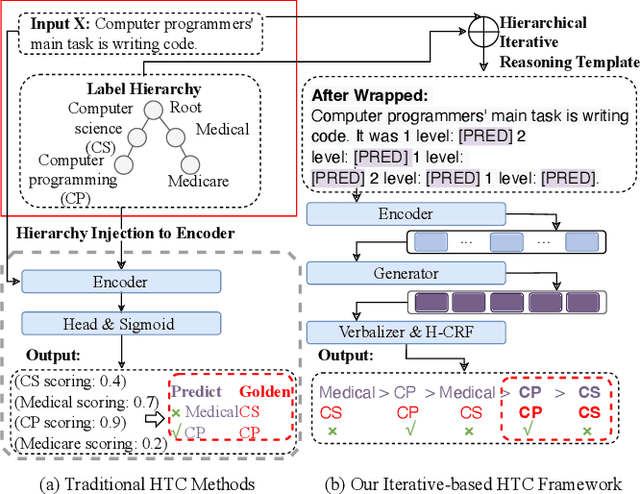
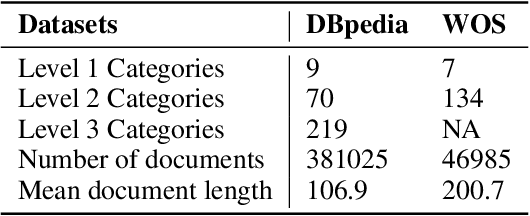
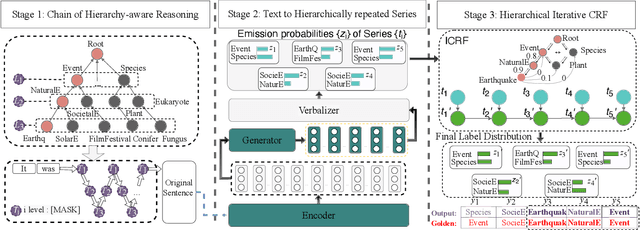
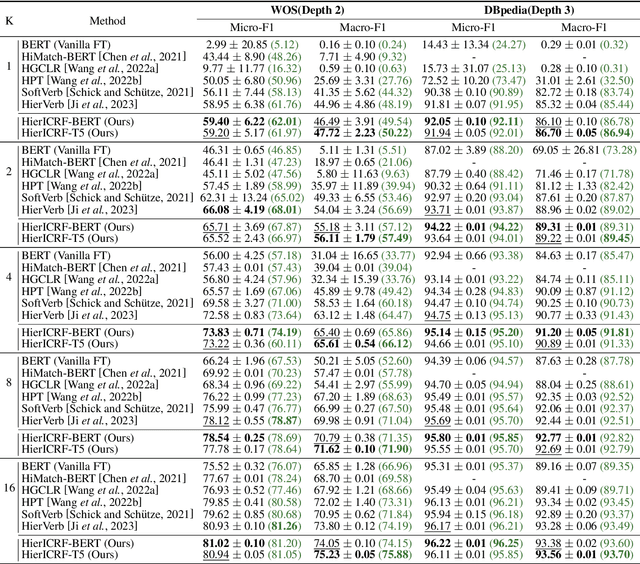
Recently, various pre-trained language models (PLMs) have been proposed to prove their impressive performances on a wide range of few-shot tasks. However, limited by the unstructured prior knowledge in PLMs, it is difficult to maintain consistent performance on complex structured scenarios, such as hierarchical text classification (HTC), especially when the downstream data is extremely scarce. The main challenge is how to transfer the unstructured semantic space in PLMs to the downstream domain hierarchy. Unlike previous work on HTC which directly performs multi-label classification or uses graph neural network (GNN) to inject label hierarchy, in this work, we study the HTC problem under a few-shot setting to adapt knowledge in PLMs from an unstructured manner to the downstream hierarchy. Technically, we design a simple yet effective method named Hierarchical Iterative Conditional Random Field (HierICRF) to search the most domain-challenging directions and exquisitely crafts domain-hierarchy adaptation as a hierarchical iterative language modeling problem, and then it encourages the model to make hierarchical consistency self-correction during the inference, thereby achieving knowledge transfer with hierarchical consistency preservation. We perform HierICRF on various architectures, and extensive experiments on two popular HTC datasets demonstrate that prompt with HierICRF significantly boosts the few-shot HTC performance with an average Micro-F1 by 28.80% to 1.50% and Macro-F1 by 36.29% to 1.5% over the previous state-of-the-art (SOTA) baselines under few-shot settings, while remaining SOTA hierarchical consistency performance.
Fast and Continual Knowledge Graph Embedding via Incremental LoRA
Jul 08, 2024



Continual Knowledge Graph Embedding (CKGE) aims to efficiently learn new knowledge and simultaneously preserve old knowledge. Dominant approaches primarily focus on alleviating catastrophic forgetting of old knowledge but neglect efficient learning for the emergence of new knowledge. However, in real-world scenarios, knowledge graphs (KGs) are continuously growing, which brings a significant challenge to fine-tuning KGE models efficiently. To address this issue, we propose a fast CKGE framework (\model), incorporating an incremental low-rank adapter (\mec) mechanism to efficiently acquire new knowledge while preserving old knowledge. Specifically, to mitigate catastrophic forgetting, \model\ isolates and allocates new knowledge to specific layers based on the fine-grained influence between old and new KGs. Subsequently, to accelerate fine-tuning, \model\ devises an efficient \mec\ mechanism, which embeds the specific layers into incremental low-rank adapters with fewer training parameters. Moreover, \mec\ introduces adaptive rank allocation, which makes the LoRA aware of the importance of entities and adjusts its rank scale adaptively. We conduct experiments on four public datasets and two new datasets with a larger initial scale. Experimental results demonstrate that \model\ can reduce training time by 34\%-49\% while still achieving competitive link prediction performance against state-of-the-art models on four public datasets (average MRR score of 21.0\% vs. 21.1\%).Meanwhile, on two newly constructed datasets, \model\ saves 51\%-68\% training time and improves link prediction performance by 1.5\%.
Towards Continual Knowledge Graph Embedding via Incremental Distillation
May 07, 2024



Traditional knowledge graph embedding (KGE) methods typically require preserving the entire knowledge graph (KG) with significant training costs when new knowledge emerges. To address this issue, the continual knowledge graph embedding (CKGE) task has been proposed to train the KGE model by learning emerging knowledge efficiently while simultaneously preserving decent old knowledge. However, the explicit graph structure in KGs, which is critical for the above goal, has been heavily ignored by existing CKGE methods. On the one hand, existing methods usually learn new triples in a random order, destroying the inner structure of new KGs. On the other hand, old triples are preserved with equal priority, failing to alleviate catastrophic forgetting effectively. In this paper, we propose a competitive method for CKGE based on incremental distillation (IncDE), which considers the full use of the explicit graph structure in KGs. First, to optimize the learning order, we introduce a hierarchical strategy, ranking new triples for layer-by-layer learning. By employing the inter- and intra-hierarchical orders together, new triples are grouped into layers based on the graph structure features. Secondly, to preserve the old knowledge effectively, we devise a novel incremental distillation mechanism, which facilitates the seamless transfer of entity representations from the previous layer to the next one, promoting old knowledge preservation. Finally, we adopt a two-stage training paradigm to avoid the over-corruption of old knowledge influenced by under-trained new knowledge. Experimental results demonstrate the superiority of IncDE over state-of-the-art baselines. Notably, the incremental distillation mechanism contributes to improvements of 0.2%-6.5% in the mean reciprocal rank (MRR) score.
Empirical Analysis of Dialogue Relation Extraction with Large Language Models
Apr 27, 2024Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction
Apr 27, 2024
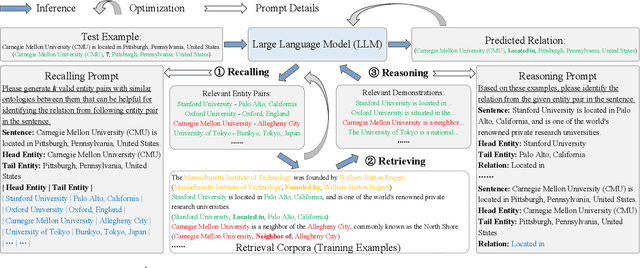
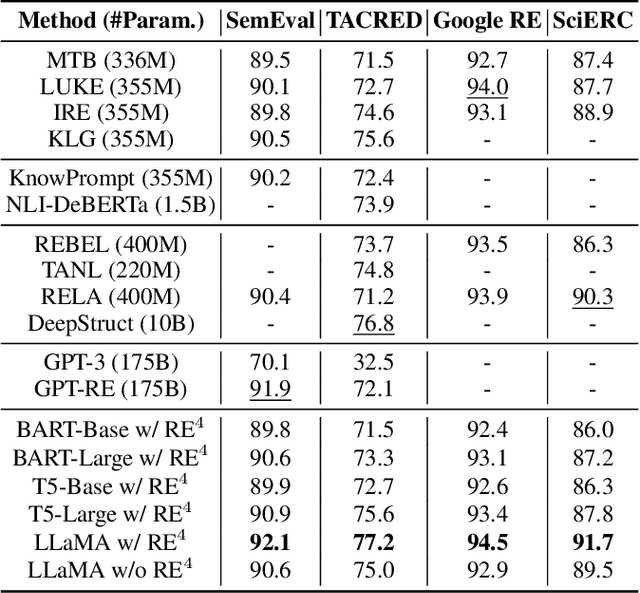
Relation extraction (RE) aims to identify relations between entities mentioned in texts. Although large language models (LLMs) have demonstrated impressive in-context learning (ICL) abilities in various tasks, they still suffer from poor performances compared to most supervised fine-tuned RE methods. Utilizing ICL for RE with LLMs encounters two challenges: (1) retrieving good demonstrations from training examples, and (2) enabling LLMs exhibit strong ICL abilities in RE. On the one hand, retrieving good demonstrations is a non-trivial process in RE, which easily results in low relevance regarding entities and relations. On the other hand, ICL with an LLM achieves poor performance in RE while RE is different from language modeling in nature or the LLM is not large enough. In this work, we propose a novel recall-retrieve-reason RE framework that synergizes LLMs with retrieval corpora (training examples) to enable relevant retrieving and reliable in-context reasoning. Specifically, we distill the consistently ontological knowledge from training datasets to let LLMs generate relevant entity pairs grounded by retrieval corpora as valid queries. These entity pairs are then used to retrieve relevant training examples from the retrieval corpora as demonstrations for LLMs to conduct better ICL via instruction tuning. Extensive experiments on different LLMs and RE datasets demonstrate that our method generates relevant and valid entity pairs and boosts ICL abilities of LLMs, achieving competitive or new state-of-the-art performance on sentence-level RE compared to previous supervised fine-tuning methods and ICL-based methods.
Meta In-Context Learning Makes Large Language Models Better Zero and Few-Shot Relation Extractors
Apr 27, 2024



Relation extraction (RE) is an important task that aims to identify the relationships between entities in texts. While large language models (LLMs) have revealed remarkable in-context learning (ICL) capability for general zero and few-shot learning, recent studies indicate that current LLMs still struggle with zero and few-shot RE. Previous studies are mainly dedicated to design prompt formats and select good examples for improving ICL-based RE. Although both factors are vital for ICL, if one can fundamentally boost the ICL capability of LLMs in RE, the zero and few-shot RE performance via ICL would be significantly improved. To this end, we introduce \textsc{Micre} (\textbf{M}eta \textbf{I}n-\textbf{C}ontext learning of LLMs for \textbf{R}elation \textbf{E}xtraction), a new meta-training framework for zero and few-shot RE where an LLM is tuned to do ICL on a diverse collection of RE datasets (i.e., learning to learn in context for RE). Through meta-training, the model becomes more effectively to learn a new RE task in context by conditioning on a few training examples with no parameter updates or task-specific templates at inference time, enabling better zero and few-shot task generalization. We experiment \textsc{Micre} on various LLMs with different model scales and 12 public RE datasets, and then evaluate it on unseen RE benchmarks under zero and few-shot settings. \textsc{Micre} delivers comparable or superior performance compared to a range of baselines including supervised fine-tuning and typical in-context learning methods. We find that the gains are particular significant for larger model scales, and using a diverse set of the meta-training RE datasets is key to improvements. Empirically, we show that \textsc{Micre} can transfer the relation semantic knowledge via relation label name during inference on target RE datasets.
Cross-Modal and Uni-Modal Soft-Label Alignment for Image-Text Retrieval
Mar 08, 2024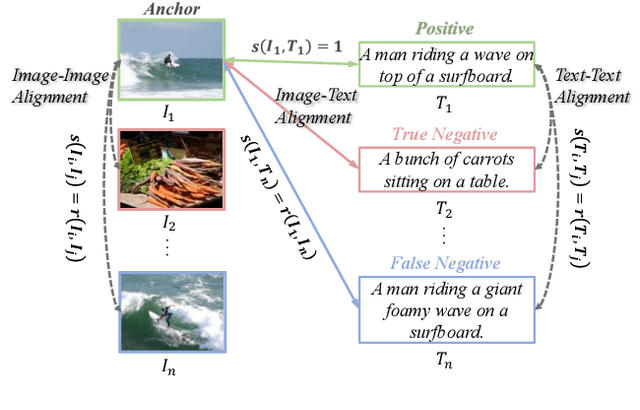
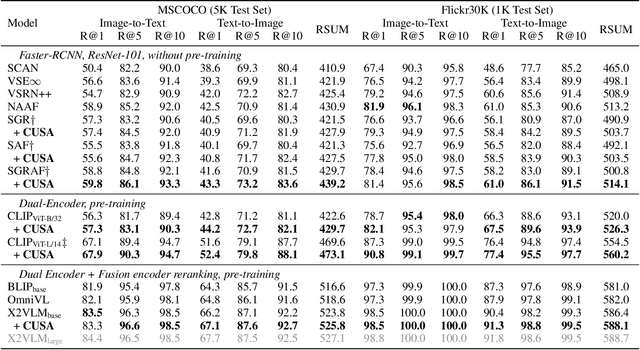
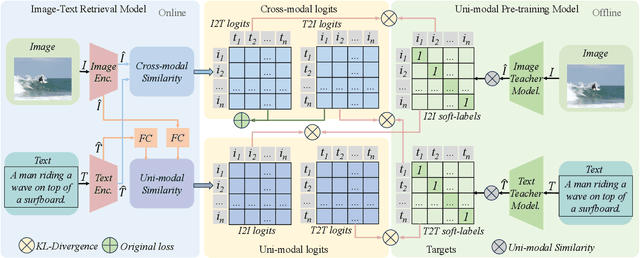
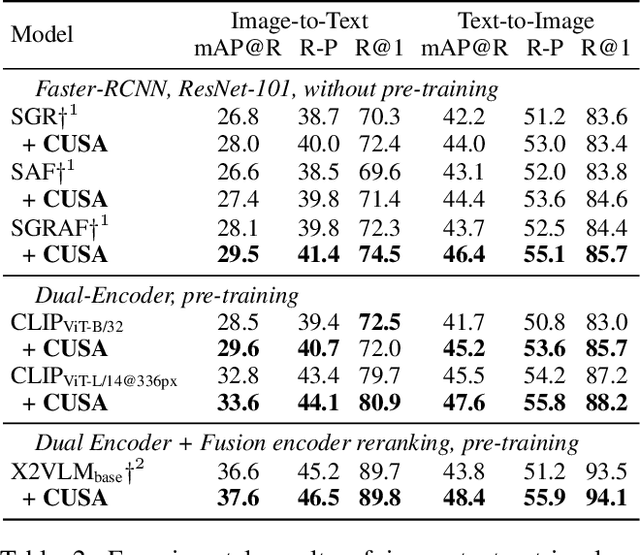
Current image-text retrieval methods have demonstrated impressive performance in recent years. However, they still face two problems: the inter-modal matching missing problem and the intra-modal semantic loss problem. These problems can significantly affect the accuracy of image-text retrieval. To address these challenges, we propose a novel method called Cross-modal and Uni-modal Soft-label Alignment (CUSA). Our method leverages the power of uni-modal pre-trained models to provide soft-label supervision signals for the image-text retrieval model. Additionally, we introduce two alignment techniques, Cross-modal Soft-label Alignment (CSA) and Uni-modal Soft-label Alignment (USA), to overcome false negatives and enhance similarity recognition between uni-modal samples. Our method is designed to be plug-and-play, meaning it can be easily applied to existing image-text retrieval models without changing their original architectures. Extensive experiments on various image-text retrieval models and datasets, we demonstrate that our method can consistently improve the performance of image-text retrieval and achieve new state-of-the-art results. Furthermore, our method can also boost the uni-modal retrieval performance of image-text retrieval models, enabling it to achieve universal retrieval. The code and supplementary files can be found at https://github.com/lerogo/aaai24_itr_cusa.
Unlocking Instructive In-Context Learning with Tabular Prompting for Relational Triple Extraction
Feb 21, 2024

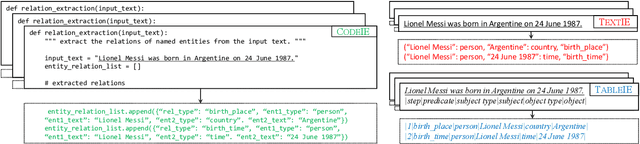
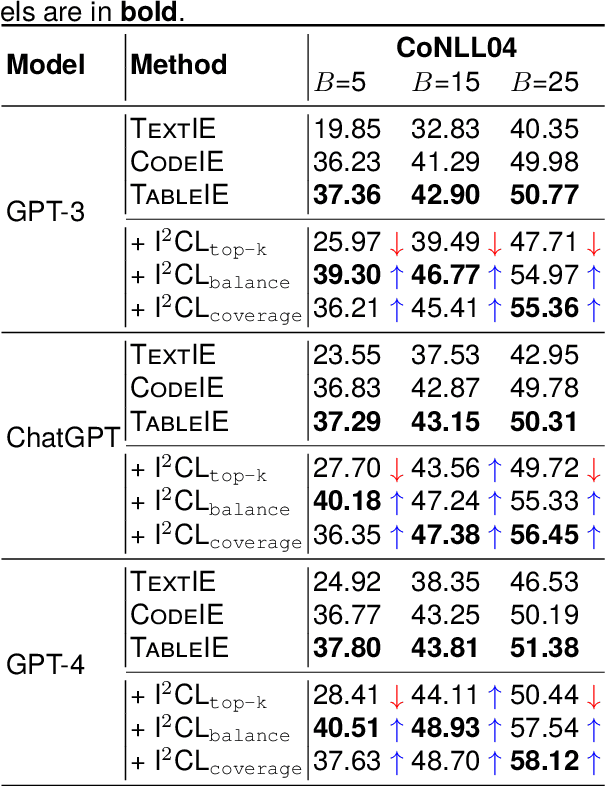
The in-context learning (ICL) for relational triple extraction (RTE) has achieved promising performance, but still encounters two key challenges: (1) how to design effective prompts and (2) how to select proper demonstrations. Existing methods, however, fail to address these challenges appropriately. On the one hand, they usually recast RTE task to text-to-text prompting formats, which is unnatural and results in a mismatch between the output format at the pre-training time and the inference time for large language models (LLMs). On the other hand, they only utilize surface natural language features and lack consideration of triple semantics in sample selection. These issues are blocking improved performance in ICL for RTE, thus we aim to tackle prompt designing and sample selection challenges simultaneously. To this end, we devise a tabular prompting for RTE (\textsc{TableIE}) which frames RTE task into a table generation task to incorporate explicit structured information into ICL, facilitating conversion of outputs to RTE structures. Then we propose instructive in-context learning (I$^2$CL) which only selects and annotates a few samples considering internal triple semantics in massive unlabeled samples.