 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenFusion: Feed-forward Human Performance Capture via Progressive Canonical Space Updates
Mar 30, 2026We present a feed-forward human performance capture method that renders novel views of a performer from a monocular RGB stream. A key challenge in this setting is the lack of sufficient observations, especially for unseen regions. Assuming the subject moves continuously over time, we take advantage of the fact that more body parts become observable by maintaining a canonical space that is progressively updated with each incoming frame. This canonical space accumulates appearance information over time and serves as a context bank when direct observations are missing in the current live frame. To effectively utilize this context while respecting the deformation of the live state, we formulate the rendering process as probabilistic regression. This resolves conflicts between past and current observations, producing sharper reconstructions than deterministic regression approaches. Furthermore, it enables plausible synthesis even in regions with no prior observations. Experiments on in-domain (4D-Dress) and out-of-distribution (MVHumanNet) datasets demonstrate the effectiveness of our approach.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Locomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
Repurposing 2D Diffusion Models for 3D Shape Completion
Dec 16, 2025We present a framework that adapts 2D diffusion models for 3D shape completion from incomplete point clouds. While text-to-image diffusion models have achieved remarkable success with abundant 2D data, 3D diffusion models lag due to the scarcity of high-quality 3D datasets and a persistent modality gap between 3D inputs and 2D latent spaces. To overcome these limitations, we introduce the Shape Atlas, a compact 2D representation of 3D geometry that (1) enables full utilization of the generative power of pretrained 2D diffusion models, and (2) aligns the modalities between the conditional input and output spaces, allowing more effective conditioning. This unified 2D formulation facilitates learning from limited 3D data and produces high-quality, detail-preserving shape completions. We validate the effectiveness of our results on the PCN and ShapeNet-55 datasets. Additionally, we show the downstream application of creating artist-created meshes from our completed point clouds, further demonstrating the practicality of our method.
Artist-Created Mesh Generation from Raw Observation
Sep 15, 2025We present an end-to-end framework for generating artist-style meshes from noisy or incomplete point clouds, such as those captured by real-world sensors like LiDAR or mobile RGB-D cameras. Artist-created meshes are crucial for commercial graphics pipelines due to their compatibility with animation and texturing tools and their efficiency in rendering. However, existing approaches often assume clean, complete inputs or rely on complex multi-stage pipelines, limiting their applicability in real-world scenarios. To address this, we propose an end-to-end method that refines the input point cloud and directly produces high-quality, artist-style meshes. At the core of our approach is a novel reformulation of 3D point cloud refinement as a 2D inpainting task, enabling the use of powerful generative models. Preliminary results on the ShapeNet dataset demonstrate the promise of our framework in producing clean, complete meshes.
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids
Aug 17, 2025Simulation-based reinforcement learning (RL) has significantly advanced humanoid locomotion tasks, yet direct real-world RL from scratch or adapting from pretrained policies remains rare, limiting the full potential of humanoid robots. Real-world learning, despite being crucial for overcoming the sim-to-real gap, faces substantial challenges related to safety, reward design, and learning efficiency. To address these limitations, we propose Robot-Trains-Robot (RTR), a novel framework where a robotic arm teacher actively supports and guides a humanoid robot student. The RTR system provides protection, learning schedule, reward, perturbation, failure detection, and automatic resets. It enables efficient long-term real-world humanoid training with minimal human intervention. Furthermore, we propose a novel RL pipeline that facilitates and stabilizes sim-to-real transfer by optimizing a single dynamics-encoded latent variable in the real world. We validate our method through two challenging real-world humanoid tasks: fine-tuning a walking policy for precise speed tracking and learning a humanoid swing-up task from scratch, illustrating the promising capabilities of real-world humanoid learning realized by RTR-style systems. See https://robot-trains-robot.github.io/ for more info.
Unlearning of Knowledge Graph Embedding via Preference Optimization
Jul 28, 2025



Existing knowledge graphs (KGs) inevitably contain outdated or erroneous knowledge that needs to be removed from knowledge graph embedding (KGE) models. To address this challenge, knowledge unlearning can be applied to eliminate specific information while preserving the integrity of the remaining knowledge in KGs. Existing unlearning methods can generally be categorized into exact unlearning and approximate unlearning. However, exact unlearning requires high training costs while approximate unlearning faces two issues when applied to KGs due to the inherent connectivity of triples: (1) It fails to fully remove targeted information, as forgetting triples can still be inferred from remaining ones. (2) It focuses on local data for specific removal, which weakens the remaining knowledge in the forgetting boundary. To address these issues, we propose GraphDPO, a novel approximate unlearning framework based on direct preference optimization (DPO). Firstly, to effectively remove forgetting triples, we reframe unlearning as a preference optimization problem, where the model is trained by DPO to prefer reconstructed alternatives over the original forgetting triples. This formulation penalizes reliance on forgettable knowledge, mitigating incomplete forgetting caused by KG connectivity. Moreover, we introduce an out-boundary sampling strategy to construct preference pairs with minimal semantic overlap, weakening the connection between forgetting and retained knowledge. Secondly, to preserve boundary knowledge, we introduce a boundary recall mechanism that replays and distills relevant information both within and across time steps. We construct eight unlearning datasets across four popular KGs with varying unlearning rates. Experiments show that GraphDPO outperforms state-of-the-art baselines by up to 10.1% in MRR_Avg and 14.0% in MRR_F1.
Demonstrating ViSafe: Vision-enabled Safety for High-speed Detect and Avoid
May 08, 2025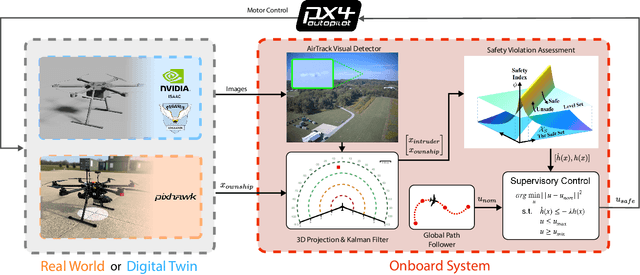
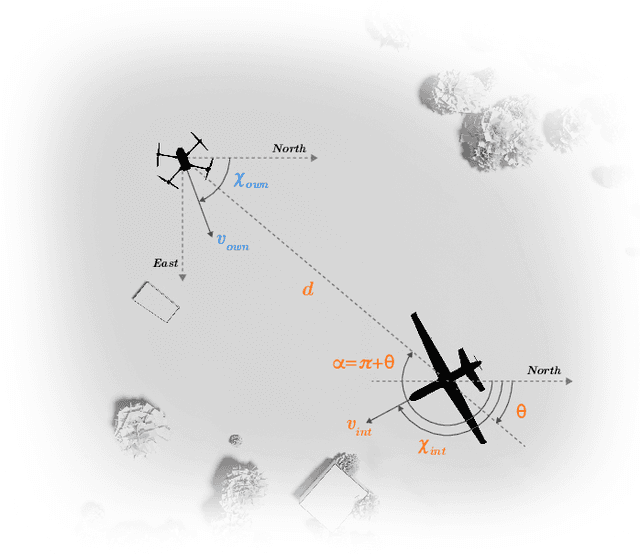

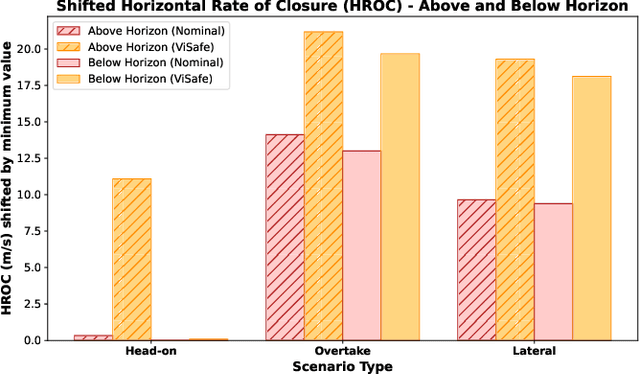
Assured safe-separation is essential for achieving seamless high-density operation of airborne vehicles in a shared airspace. To equip resource-constrained aerial systems with this safety-critical capability, we present ViSafe, a high-speed vision-only airborne collision avoidance system. ViSafe offers a full-stack solution to the Detect and Avoid (DAA) problem by tightly integrating a learning-based edge-AI framework with a custom multi-camera hardware prototype designed under SWaP-C constraints. By leveraging perceptual input-focused control barrier functions (CBF) to design, encode, and enforce safety thresholds, ViSafe can provide provably safe runtime guarantees for self-separation in high-speed aerial operations. We evaluate ViSafe's performance through an extensive test campaign involving both simulated digital twins and real-world flight scenarios. By independently varying agent types, closure rates, interaction geometries, and environmental conditions (e.g., weather and lighting), we demonstrate that ViSafe consistently ensures self-separation across diverse scenarios. In first-of-its-kind real-world high-speed collision avoidance tests with closure rates reaching 144 km/h, ViSafe sets a new benchmark for vision-only autonomous collision avoidance, establishing a new standard for safety in high-speed aerial navigation.
Towards Improved Text-Aligned Codebook Learning: Multi-Hierarchical Codebook-Text Alignment with Long Text
Mar 03, 2025Image quantization is a crucial technique in image generation, aimed at learning a codebook that encodes an image into a discrete token sequence. Recent advancements have seen researchers exploring learning multi-modal codebook (i.e., text-aligned codebook) by utilizing image caption semantics, aiming to enhance codebook performance in cross-modal tasks. However, existing image-text paired datasets exhibit a notable flaw in that the text descriptions tend to be overly concise, failing to adequately describe the images and provide sufficient semantic knowledge, resulting in limited alignment of text and codebook at a fine-grained level. In this paper, we propose a novel Text-Augmented Codebook Learning framework, named TA-VQ, which generates longer text for each image using the visual-language model for improved text-aligned codebook learning. However, the long text presents two key challenges: how to encode text and how to align codebook and text. To tackle two challenges, we propose to split the long text into multiple granularities for encoding, i.e., word, phrase, and sentence, so that the long text can be fully encoded without losing any key semantic knowledge. Following this, a hierarchical encoder and novel sampling-based alignment strategy are designed to achieve fine-grained codebook-text alignment. Additionally, our method can be seamlessly integrated into existing VQ models. Extensive experiments in reconstruction and various downstream tasks demonstrate its effectiveness compared to previous state-of-the-art approaches.
MCVO: A Generic Visual Odometry for Arbitrarily Arranged Multi-Cameras
Dec 04, 2024



Making multi-camera visual SLAM systems easier to set up and more robust to the environment is always one of the focuses of vision robots. Existing monocular and binocular vision SLAM systems have narrow FoV and are fragile in textureless environments with degenerated accuracy and limited robustness. Thus multi-camera SLAM systems are gaining attention because they can provide redundancy for texture degeneration with wide FoV. However, current multi-camera SLAM systems face massive data processing pressure and elaborately designed camera configurations, leading to estimation failures for arbitrarily arranged multi-camera systems. To address these problems, we propose a generic visual odometry for arbitrarily arranged multi-cameras, which can achieve metric-scale state estimation with high flexibility in the cameras' arrangement. Specifically, we first design a learning-based feature extraction and tracking framework to shift the pressure of CPU processing of multiple video streams. Then we use the rigid constraints between cameras to estimate the metric scale poses for robust SLAM system initialization. Finally, we fuse the features of the multi-cameras in the SLAM back-end to achieve robust pose estimation and online scale optimization. Additionally, multi-camera features help improve the loop detection for pose graph optimization. Experiments on KITTI-360 and MultiCamData datasets validate the robustness of our method over arbitrarily placed cameras. Compared with other stereo and multi-camera visual SLAM systems, our method obtains higher pose estimation accuracy with better generalization ability. Our codes and online demos are available at \url{https://github.com/JunhaoWang615/MCVO}