 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuntime Monitoring of Perception-Based Autonomous Systems via Embedding Temporal Logic
May 14, 2026Runtime monitoring of autonomous systems traditionally relies on mapping continuous sensor observations to discrete logical propositions defined over low-dimensional state variables. This abstraction breaks down in perception-driven settings, where such mappings require additional learned modules that are often computationally expensive, brittle, and semantically misaligned. In this work, we propose Embedding Temporal Logic (ETL), a temporal logic that performs monitoring directly in learned embedding spaces. ETL defines predicates through distances between observed embeddings and target embeddings derived from reference observations. This formulation allows specifications to capture high-level perceptual concepts, such as similarity to visual goals or avoidance of semantic regions, that are difficult or impossible to express using traditional predicates. By composing these predicates with temporal operators, ETL naturally expresses temporally extended and sequential perceptual behaviors. We introduce ETL monitors for evaluating specifications over bounded embedding traces, along with a conformal calibration procedure that provides reliable and safety-oriented predicate evaluation. We evaluate our approach across multiple manipulation environments to show that ETL achieves strong empirical agreement with ground-truth semantics, including accurate monitoring of temporally composed behaviors.
Demonstrating ViSafe: Vision-enabled Safety for High-speed Detect and Avoid
May 08, 2025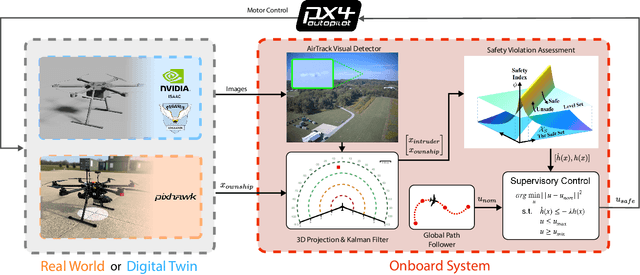
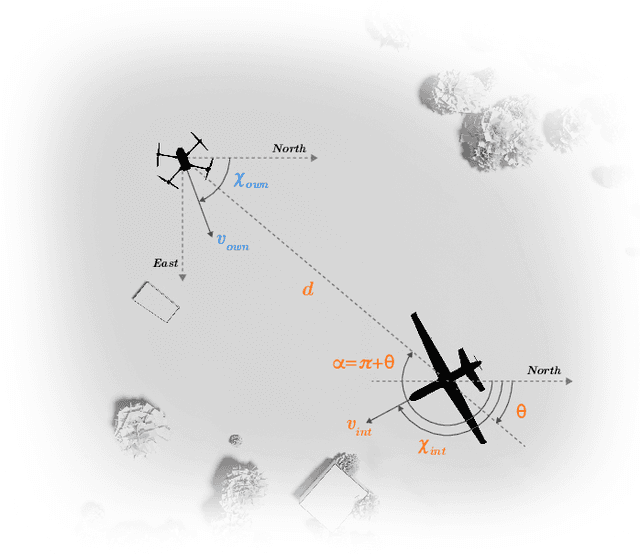

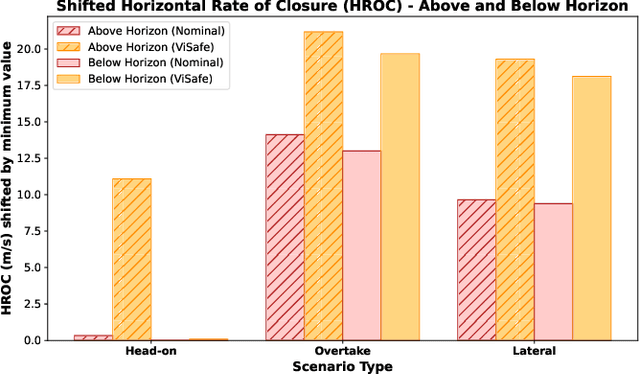
Assured safe-separation is essential for achieving seamless high-density operation of airborne vehicles in a shared airspace. To equip resource-constrained aerial systems with this safety-critical capability, we present ViSafe, a high-speed vision-only airborne collision avoidance system. ViSafe offers a full-stack solution to the Detect and Avoid (DAA) problem by tightly integrating a learning-based edge-AI framework with a custom multi-camera hardware prototype designed under SWaP-C constraints. By leveraging perceptual input-focused control barrier functions (CBF) to design, encode, and enforce safety thresholds, ViSafe can provide provably safe runtime guarantees for self-separation in high-speed aerial operations. We evaluate ViSafe's performance through an extensive test campaign involving both simulated digital twins and real-world flight scenarios. By independently varying agent types, closure rates, interaction geometries, and environmental conditions (e.g., weather and lighting), we demonstrate that ViSafe consistently ensures self-separation across diverse scenarios. In first-of-its-kind real-world high-speed collision avoidance tests with closure rates reaching 144 km/h, ViSafe sets a new benchmark for vision-only autonomous collision avoidance, establishing a new standard for safety in high-speed aerial navigation.
Pretrained Embeddings as a Behavior Specification Mechanism
Mar 03, 2025We propose an approach to formally specifying the behavioral properties of systems that rely on a perception model for interactions with the physical world. The key idea is to introduce embeddings -- mathematical representations of a real-world concept -- as a first-class construct in a specification language, where properties are expressed in terms of distances between a pair of ideal and observed embeddings. To realize this approach, we propose a new type of temporal logic called Embedding Temporal Logic (ETL), and describe how it can be used to express a wider range of properties about AI-enabled systems than previously possible. We demonstrate the applicability of ETL through a preliminary evaluation involving planning tasks in robots that are driven by foundation models; the results are promising, showing that embedding-based specifications can be used to steer a system towards desirable behaviors.
STLCG++: A Masking Approach for Differentiable Signal Temporal Logic Specification
Jan 08, 2025



Signal Temporal Logic (STL) offers a concise yet expressive framework for specifying and reasoning about spatio-temporal behaviors of robotic systems. Attractively, STL admits the notion of robustness, the degree to which an input signal satisfies or violates an STL specification, thus providing a nuanced evaluation of system performance. Notably, the differentiability of STL robustness enables direct integration to robotics workflows that rely on gradient-based optimization, such as trajectory optimization and deep learning. However, existing approaches to evaluating and differentiating STL robustness rely on recurrent computations, which become inefficient with longer sequences, limiting their use in time-sensitive applications. In this paper, we present STLCG++, a masking-based approach that parallelizes STL robustness evaluation and backpropagation across timesteps, achieving more than 1000x faster computation time than the recurrent approach. We also introduce a smoothing technique for differentiability through time interval bounds, expanding STL's applicability in gradient-based optimization tasks over spatial and temporal variables. Finally, we demonstrate STLCG++'s benefits through three robotics use cases and provide open-source Python libraries in JAX and PyTorch for seamless integration into modern robotics workflows.
Logically Constrained Robotics Transformers for Enhanced Perception-Action Planning
Aug 09, 2024


With the advent of large foundation model based planning, there is a dire need to ensure their output aligns with the stakeholder's intent. When these models are deployed in the real world, the need for alignment is magnified due to the potential cost to life and infrastructure due to unexpected faliures. Temporal Logic specifications have long provided a way to constrain system behaviors and are a natural fit for these use cases. In this work, we propose a novel approach to factor in signal temporal logic specifications while using autoregressive transformer models for trajectory planning. We also provide a trajectory dataset for pretraining and evaluating foundation models. Our proposed technique acheives 74.3 % higher specification satisfaction over the baselines.
Tolerance of Reinforcement Learning Controllers against Deviations in Cyber Physical Systems
Jun 24, 2024



Cyber-physical systems (CPS) with reinforcement learning (RL)-based controllers are increasingly being deployed in complex physical environments such as autonomous vehicles, the Internet-of-Things(IoT), and smart cities. An important property of a CPS is tolerance; i.e., its ability to function safely under possible disturbances and uncertainties in the actual operation. In this paper, we introduce a new, expressive notion of tolerance that describes how well a controller is capable of satisfying a desired system requirement, specified using Signal Temporal Logic (STL), under possible deviations in the system. Based on this definition, we propose a novel analysis problem, called the tolerance falsification problem, which involves finding small deviations that result in a violation of the given requirement. We present a novel, two-layer simulation-based analysis framework and a novel search heuristic for finding small tolerance violations. To evaluate our approach, we construct a set of benchmark problems where system parameters can be configured to represent different types of uncertainties and disturbancesin the system. Our evaluation shows that our falsification approach and heuristic can effectively find small tolerance violations.
Safe Planning through Incremental Decomposition of Signal Temporal Logic Specifications
Mar 19, 2024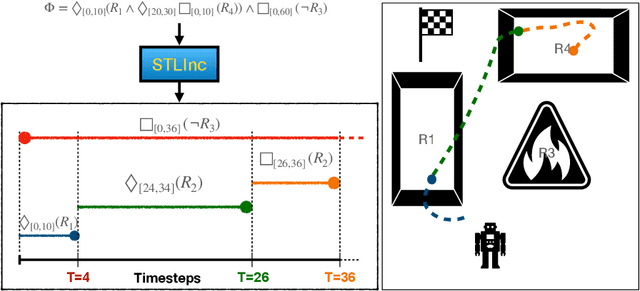



Trajectory planning is a critical process that enables autonomous systems to safely navigate complex environments. Signal temporal logic (STL) specifications are an effective way to encode complex temporally extended objectives for trajectory planning in cyber-physical systems (CPS). However, planning from these specifications using existing techniques scale exponentially with the number of nested operators and the horizon of specification. Additionally, performance is exacerbated at runtime due to limited computational budgets and compounding modeling errors. Decomposing a complex specification into smaller subtasks and incrementally planning for them can remedy these issues. In this work, we present a way to decompose STL requirements temporally to improve planning efficiency and performance. The key insight in our work is to encode all specifications as a set of reachability and invariance constraints and scheduling these constraints sequentially at runtime. Our proposed technique outperforms the state-of-the-art trajectory synthesis techniques for both linear and non linear dynamical systems.
"Do it my way!": Impact of Customizations on Trust perceptions in Human-Robot Collaboration
Oct 28, 2023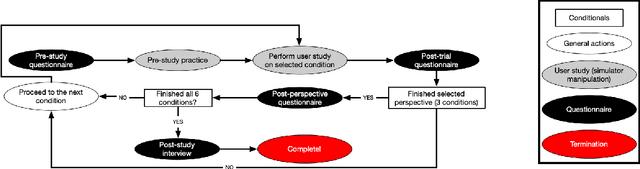
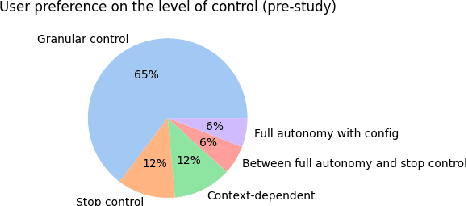


Trust has been shown to be a key factor in effective human-robot collaboration. In the context of assistive robotics, the effect of trust factors on human experience is further pronounced. Personalization of assistive robots is an orthogonal factor positively correlated with robot adoption and user perceptions. In this work, we investigate the relationship between these factors through a within-subjects study (N=17). We provide different levels of customization possibilities over baseline autonomous robot behavior and investigate its impact on trust. Our findings indicate that increased levels of customization was associated with higher trust and comfort perceptions. The assistive robot design process can benefit significantly from our insights for designing trustworthy and customized robots.
FoundLoc: Vision-based Onboard Aerial Localization in the Wild
Oct 25, 2023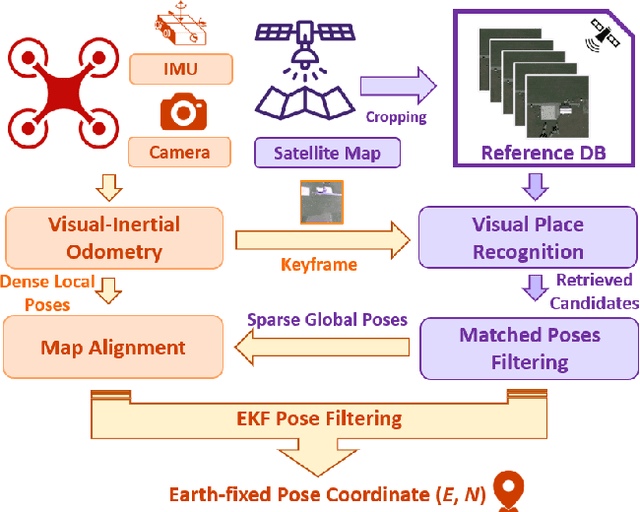
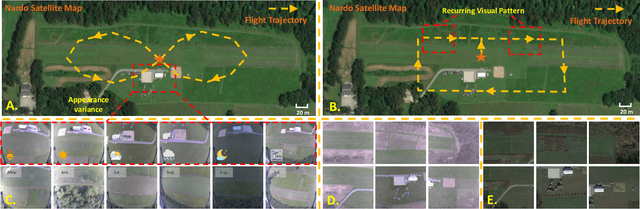

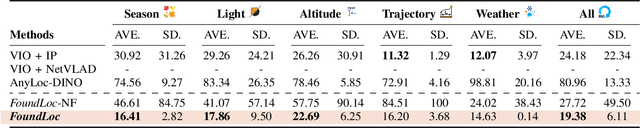
Robust and accurate localization for Unmanned Aerial Vehicles (UAVs) is an essential capability to achieve autonomous, long-range flights. Current methods either rely heavily on GNSS, face limitations in visual-based localization due to appearance variances and stylistic dissimilarities between camera and reference imagery, or operate under the assumption of a known initial pose. In this paper, we developed a GNSS-denied localization approach for UAVs that harnesses both Visual-Inertial Odometry (VIO) and Visual Place Recognition (VPR) using a foundation model. This paper presents a novel vision-based pipeline that works exclusively with a nadir-facing camera, an Inertial Measurement Unit (IMU), and pre-existing satellite imagery for robust, accurate localization in varied environments and conditions. Our system demonstrated average localization accuracy within a $20$-meter range, with a minimum error below $1$ meter, under real-world conditions marked by drastic changes in environmental appearance and with no assumption of the vehicle's initial pose. The method is proven to be effective and robust, addressing the crucial need for reliable UAV localization in GNSS-denied environments, while also being computationally efficient enough to be deployed on resource-constrained platforms.
Challenges in Close-Proximity Safe and Seamless Operation of Manned and Unmanned Aircraft in Shared Airspace
Nov 13, 2022
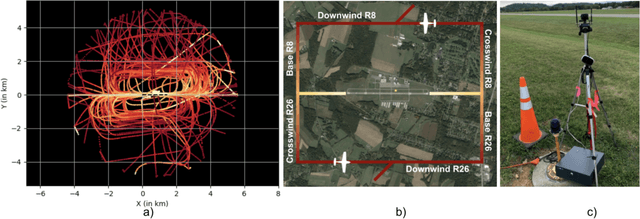


We propose developing an integrated system to keep autonomous unmanned aircraft safely separated and behave as expected in conjunction with manned traffic. The main goal is to achieve safe manned-unmanned vehicle teaming to improve system performance, have each (robot/human) teammate learn from each other in various aircraft operations, and reduce the manning needs of manned aircraft. The proposed system anticipates and reacts to other aircraft using natural language instructions and can serve as a co-pilot or operate entirely autonomously. We point out the main technical challenges where improvements on current state-of-the-art are needed to enable Visual Flight Rules to fully autonomous aerial operations, bringing insights to these critical areas. Furthermore, we present an interactive demonstration in a prototypical scenario with one AI pilot and one human pilot sharing the same terminal airspace, interacting with each other using language, and landing safely on the same runway. We also show a demonstration of a vision-only aircraft detection system.