 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow The Rules: Online Signal Temporal Logic Tree Search for Guided Imitation Learning in Stochastic Domains
Paper and Code
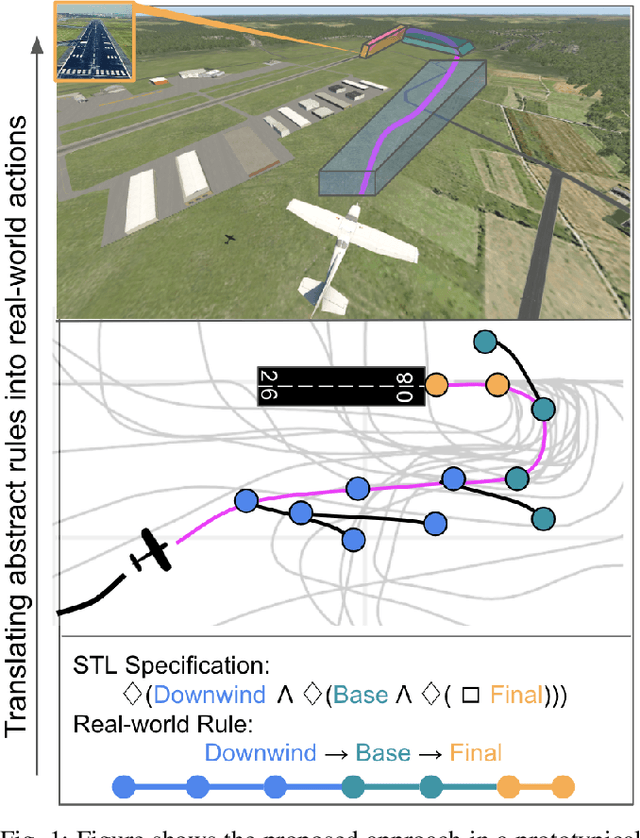

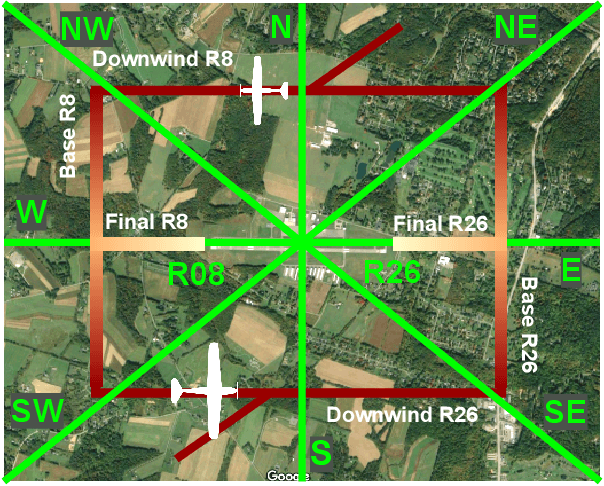

Seamlessly integrating rules in Learning-from-Demonstrations (LfD) policies is a critical requirement to enable the real-world deployment of AI agents. Recently Signal Temporal Logic (STL) has been shown to be an effective language for encoding rules as spatio-temporal constraints. This work uses Monte Carlo Tree Search (MCTS) as a means of integrating STL specification into a vanilla LfD policy to improve constraint satisfaction. We propose augmenting the MCTS heuristic with STL robustness values to bias the tree search towards branches with higher constraint satisfaction. While the domain-independent method can be applied to integrate STL rules online into any pre-trained LfD algorithm, we choose goal-conditioned Generative Adversarial Imitation Learning as the offline LfD policy. We apply the proposed method to the domain of planning trajectories for General Aviation aircraft around a non-towered airfield. Results using the simulator trained on real-world data showcase 60% improved performance over baseline LfD methods that do not use STL heuristics.