 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Conflicting Constraints in Multi-Agent Reinforcement Learning with Layered Safety
May 04, 2025Preventing collisions in multi-robot navigation is crucial for deployment. This requirement hinders the use of learning-based approaches, such as multi-agent reinforcement learning (MARL), on their own due to their lack of safety guarantees. Traditional control methods, such as reachability and control barrier functions, can provide rigorous safety guarantees when interactions are limited only to a small number of robots. However, conflicts between the constraints faced by different agents pose a challenge to safe multi-agent coordination. To overcome this challenge, we propose a method that integrates multiple layers of safety by combining MARL with safety filters. First, MARL is used to learn strategies that minimize multiple agent interactions, where multiple indicates more than two. Particularly, we focus on interactions likely to result in conflicting constraints within the engagement distance. Next, for agents that enter the engagement distance, we prioritize pairs requiring the most urgent corrective actions. Finally, a dedicated safety filter provides tactical corrective actions to resolve these conflicts. Crucially, the design decisions for all layers of this framework are grounded in reachability analysis and a control barrier-value function-based filtering mechanism. We validate our Layered Safe MARL framework in 1) hardware experiments using Crazyflie drones and 2) high-density advanced aerial mobility (AAM) operation scenarios, where agents navigate to designated waypoints while avoiding collisions. The results show that our method significantly reduces conflict while maintaining safety without sacrificing much efficiency (i.e., shorter travel time and distance) compared to baselines that do not incorporate layered safety. The project website is available at \href{https://dinamo-mit.github.io/Layered-Safe-MARL/}{[this https URL]}
Cooperation and Fairness in Multi-Agent Reinforcement Learning
Oct 19, 2024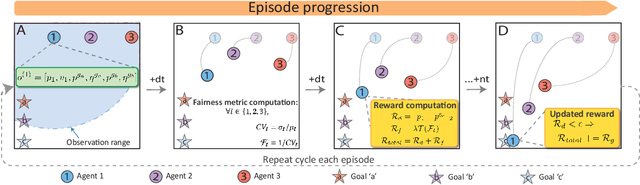

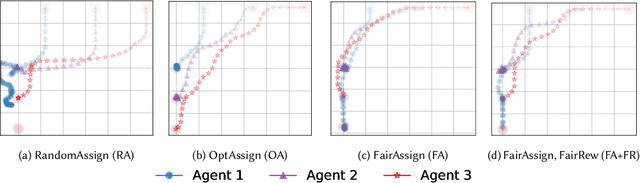
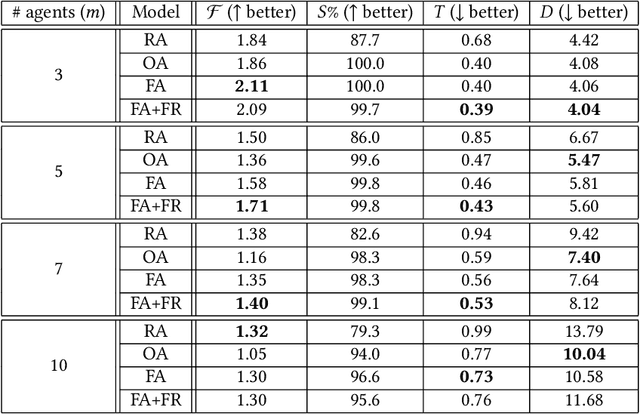
Multi-agent systems are trained to maximize shared cost objectives, which typically reflect system-level efficiency. However, in the resource-constrained environments of mobility and transportation systems, efficiency may be achieved at the expense of fairness -- certain agents may incur significantly greater costs or lower rewards compared to others. Tasks could be distributed inequitably, leading to some agents receiving an unfair advantage while others incur disproportionately high costs. It is important to consider the tradeoffs between efficiency and fairness. We consider the problem of fair multi-agent navigation for a group of decentralized agents using multi-agent reinforcement learning (MARL). We consider the reciprocal of the coefficient of variation of the distances traveled by different agents as a measure of fairness and investigate whether agents can learn to be fair without significantly sacrificing efficiency (i.e., increasing the total distance traveled). We find that by training agents using min-max fair distance goal assignments along with a reward term that incentivizes fairness as they move towards their goals, the agents (1) learn a fair assignment of goals and (2) achieve almost perfect goal coverage in navigation scenarios using only local observations. For goal coverage scenarios, we find that, on average, our model yields a 14% improvement in efficiency and a 5% improvement in fairness over a baseline trained using random assignments. Furthermore, an average of 21% improvement in fairness can be achieved compared to a model trained on optimally efficient assignments; this increase in fairness comes at the expense of only a 7% decrease in efficiency. Finally, we extend our method to environments in which agents must complete coverage tasks in prescribed formations and show that it is possible to do so without tailoring the models to specific formation shapes.
Follow The Rules: Online Signal Temporal Logic Tree Search for Guided Imitation Learning in Stochastic Domains
Sep 27, 2022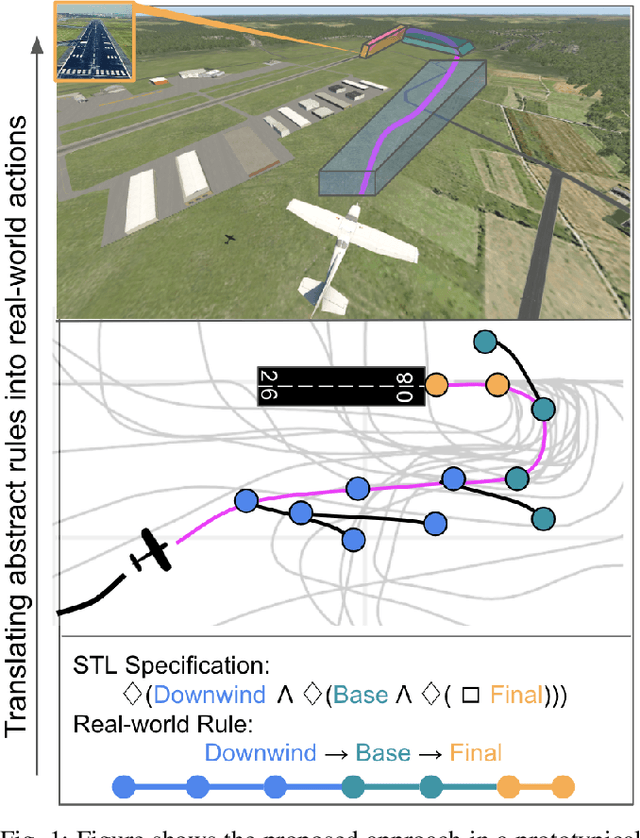

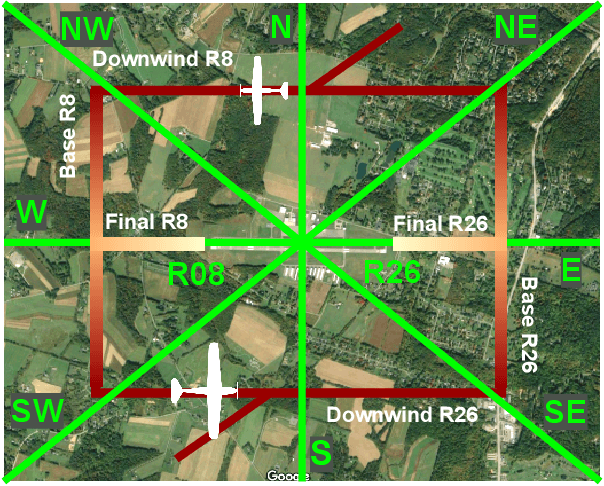

Seamlessly integrating rules in Learning-from-Demonstrations (LfD) policies is a critical requirement to enable the real-world deployment of AI agents. Recently Signal Temporal Logic (STL) has been shown to be an effective language for encoding rules as spatio-temporal constraints. This work uses Monte Carlo Tree Search (MCTS) as a means of integrating STL specification into a vanilla LfD policy to improve constraint satisfaction. We propose augmenting the MCTS heuristic with STL robustness values to bias the tree search towards branches with higher constraint satisfaction. While the domain-independent method can be applied to integrate STL rules online into any pre-trained LfD algorithm, we choose goal-conditioned Generative Adversarial Imitation Learning as the offline LfD policy. We apply the proposed method to the domain of planning trajectories for General Aviation aircraft around a non-towered airfield. Results using the simulator trained on real-world data showcase 60% improved performance over baseline LfD methods that do not use STL heuristics.
UAV Formation Preservation for Target Tracking Applications
Dec 06, 2021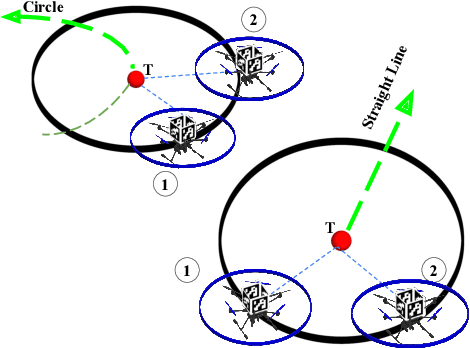
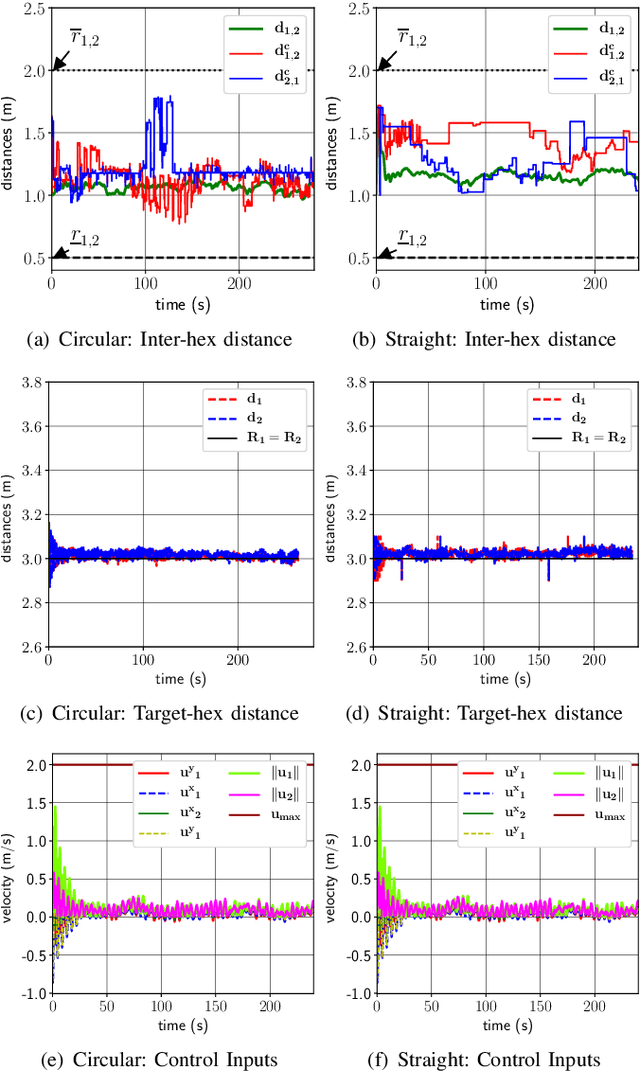
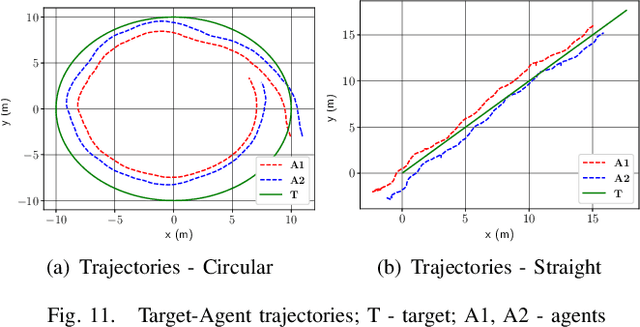
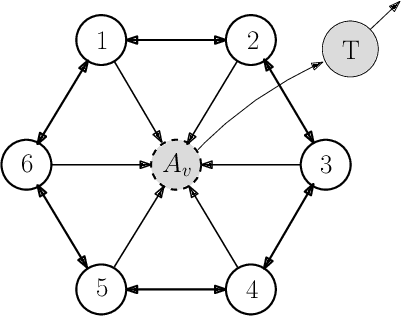
This paper presents a collaborative target tracking application with multiple agents and a formulation of an agent-formation problem with desired inter-agent distances and specified bounds. We propose a barrier Lyapunov function-based distributed control law to preserve the formation for target-tracking and assess its stability using a kinematic model. Numerical results with this model are presented to demonstrate the advantages of the proposed control over a quadratic Lyapunov function-based control. A concluding evaluation using experimental ROS simulations is presented to illustrate the applicability of the proposed control approach to a multi-rotor system and a target executing straight line and circular motion.