 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperation and Fairness in Multi-Agent Reinforcement Learning
Oct 19, 2024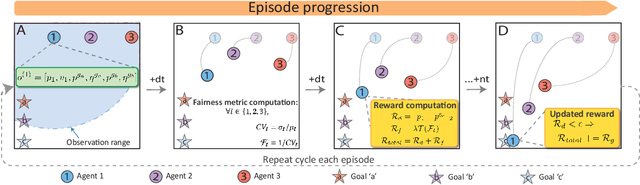

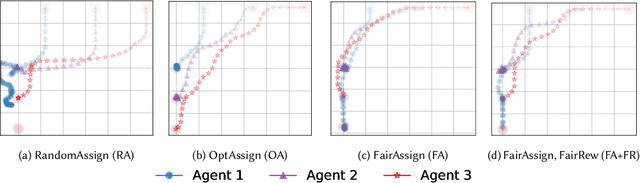
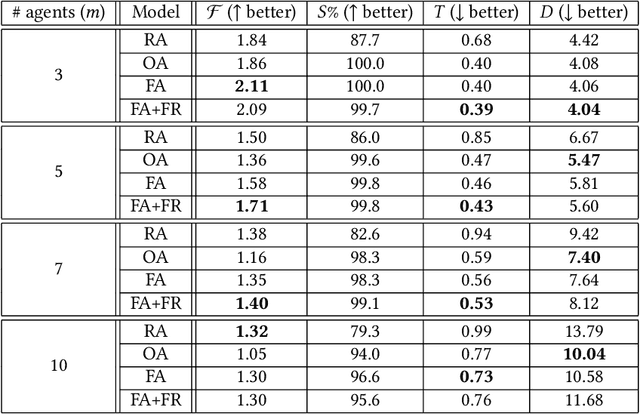
Multi-agent systems are trained to maximize shared cost objectives, which typically reflect system-level efficiency. However, in the resource-constrained environments of mobility and transportation systems, efficiency may be achieved at the expense of fairness -- certain agents may incur significantly greater costs or lower rewards compared to others. Tasks could be distributed inequitably, leading to some agents receiving an unfair advantage while others incur disproportionately high costs. It is important to consider the tradeoffs between efficiency and fairness. We consider the problem of fair multi-agent navigation for a group of decentralized agents using multi-agent reinforcement learning (MARL). We consider the reciprocal of the coefficient of variation of the distances traveled by different agents as a measure of fairness and investigate whether agents can learn to be fair without significantly sacrificing efficiency (i.e., increasing the total distance traveled). We find that by training agents using min-max fair distance goal assignments along with a reward term that incentivizes fairness as they move towards their goals, the agents (1) learn a fair assignment of goals and (2) achieve almost perfect goal coverage in navigation scenarios using only local observations. For goal coverage scenarios, we find that, on average, our model yields a 14% improvement in efficiency and a 5% improvement in fairness over a baseline trained using random assignments. Furthermore, an average of 21% improvement in fairness can be achieved compared to a model trained on optimally efficient assignments; this increase in fairness comes at the expense of only a 7% decrease in efficiency. Finally, we extend our method to environments in which agents must complete coverage tasks in prescribed formations and show that it is possible to do so without tailoring the models to specific formation shapes.
Scalable Multi-Agent Reinforcement Learning through Intelligent Information Aggregation
Nov 03, 2022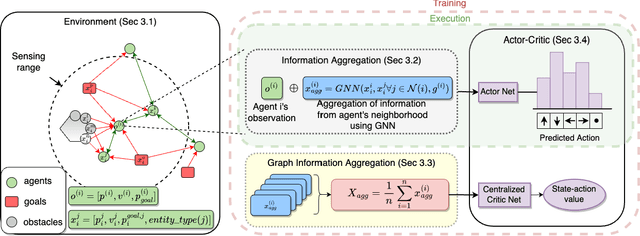
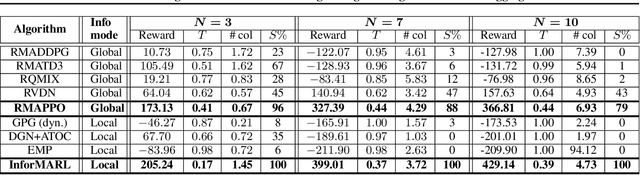
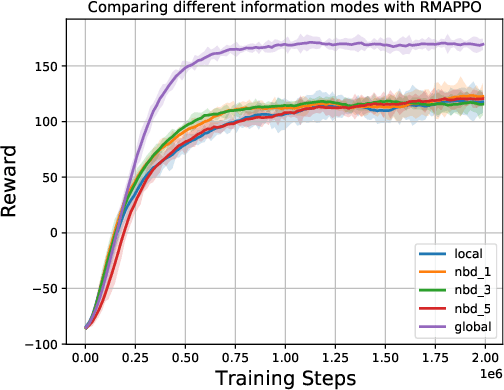
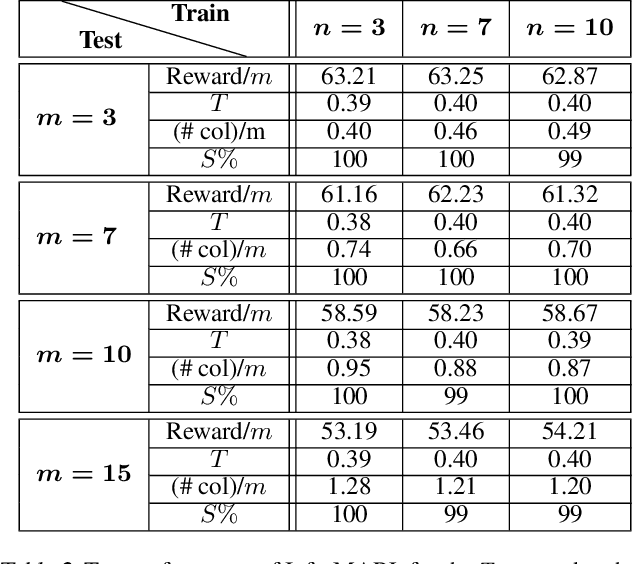
We consider the problem of multi-agent navigation and collision avoidance when observations are limited to the local neighborhood of each agent. We propose InforMARL, a novel architecture for multi-agent reinforcement learning (MARL) which uses local information intelligently to compute paths for all the agents in a decentralized manner. Specifically, InforMARL aggregates information about the local neighborhood of agents for both the actor and the critic using a graph neural network and can be used in conjunction with any standard MARL algorithm. We show that (1) in training, InforMARL has better sample efficiency and performance than baseline approaches, despite using less information, and (2) in testing, it scales well to environments with arbitrary numbers of agents and obstacles.