 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Conflicting Constraints in Multi-Agent Reinforcement Learning with Layered Safety
May 04, 2025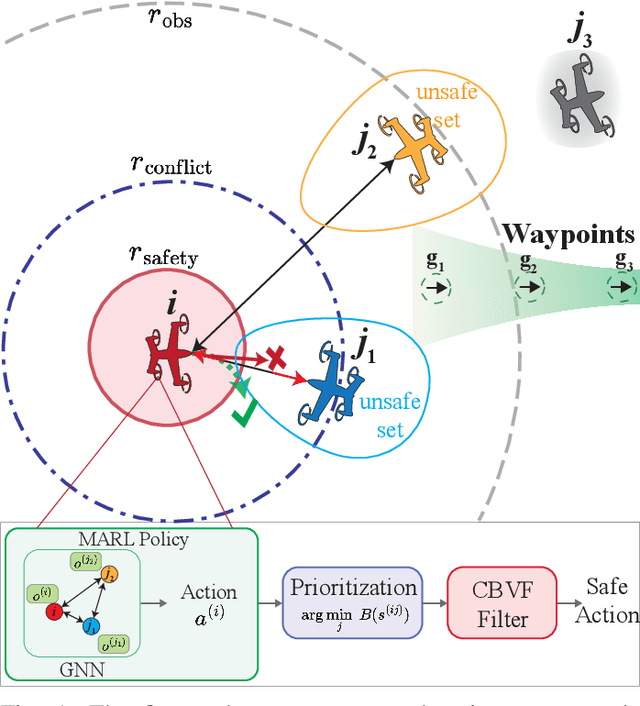
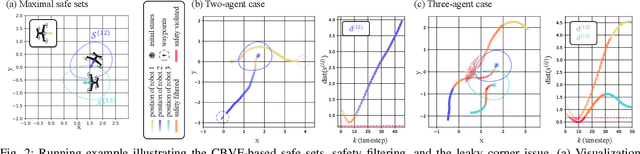
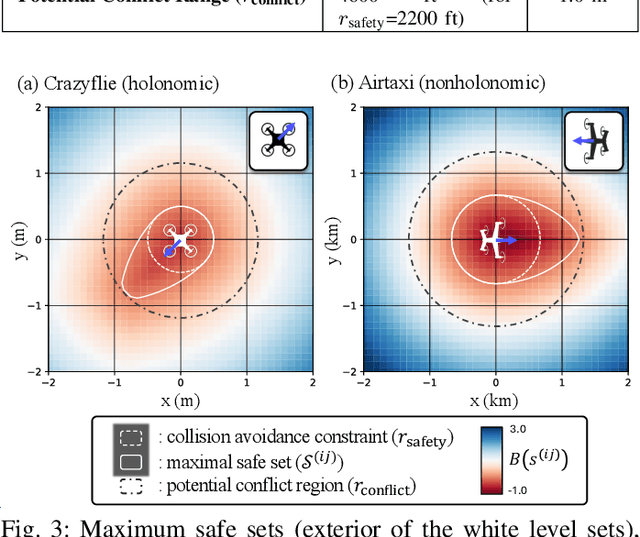

Preventing collisions in multi-robot navigation is crucial for deployment. This requirement hinders the use of learning-based approaches, such as multi-agent reinforcement learning (MARL), on their own due to their lack of safety guarantees. Traditional control methods, such as reachability and control barrier functions, can provide rigorous safety guarantees when interactions are limited only to a small number of robots. However, conflicts between the constraints faced by different agents pose a challenge to safe multi-agent coordination. To overcome this challenge, we propose a method that integrates multiple layers of safety by combining MARL with safety filters. First, MARL is used to learn strategies that minimize multiple agent interactions, where multiple indicates more than two. Particularly, we focus on interactions likely to result in conflicting constraints within the engagement distance. Next, for agents that enter the engagement distance, we prioritize pairs requiring the most urgent corrective actions. Finally, a dedicated safety filter provides tactical corrective actions to resolve these conflicts. Crucially, the design decisions for all layers of this framework are grounded in reachability analysis and a control barrier-value function-based filtering mechanism. We validate our Layered Safe MARL framework in 1) hardware experiments using Crazyflie drones and 2) high-density advanced aerial mobility (AAM) operation scenarios, where agents navigate to designated waypoints while avoiding collisions. The results show that our method significantly reduces conflict while maintaining safety without sacrificing much efficiency (i.e., shorter travel time and distance) compared to baselines that do not incorporate layered safety. The project website is available at \href{https://dinamo-mit.github.io/Layered-Safe-MARL/}{[this https URL]}
Cooperation and Fairness in Multi-Agent Reinforcement Learning
Oct 19, 2024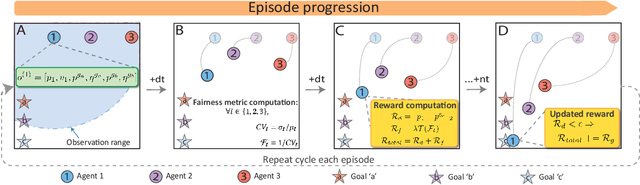

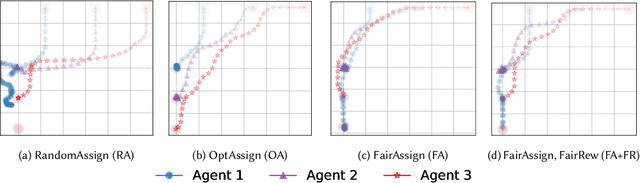
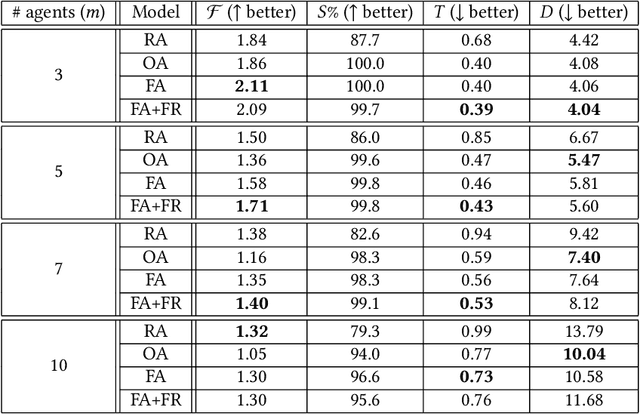
Multi-agent systems are trained to maximize shared cost objectives, which typically reflect system-level efficiency. However, in the resource-constrained environments of mobility and transportation systems, efficiency may be achieved at the expense of fairness -- certain agents may incur significantly greater costs or lower rewards compared to others. Tasks could be distributed inequitably, leading to some agents receiving an unfair advantage while others incur disproportionately high costs. It is important to consider the tradeoffs between efficiency and fairness. We consider the problem of fair multi-agent navigation for a group of decentralized agents using multi-agent reinforcement learning (MARL). We consider the reciprocal of the coefficient of variation of the distances traveled by different agents as a measure of fairness and investigate whether agents can learn to be fair without significantly sacrificing efficiency (i.e., increasing the total distance traveled). We find that by training agents using min-max fair distance goal assignments along with a reward term that incentivizes fairness as they move towards their goals, the agents (1) learn a fair assignment of goals and (2) achieve almost perfect goal coverage in navigation scenarios using only local observations. For goal coverage scenarios, we find that, on average, our model yields a 14% improvement in efficiency and a 5% improvement in fairness over a baseline trained using random assignments. Furthermore, an average of 21% improvement in fairness can be achieved compared to a model trained on optimally efficient assignments; this increase in fairness comes at the expense of only a 7% decrease in efficiency. Finally, we extend our method to environments in which agents must complete coverage tasks in prescribed formations and show that it is possible to do so without tailoring the models to specific formation shapes.
Long-Horizon Planning for Multi-Agent Robots in Partially Observable Environments
Jul 14, 2024



The ability of Language Models (LMs) to understand natural language makes them a powerful tool for parsing human instructions into task plans for autonomous robots. Unlike traditional planning methods that rely on domain-specific knowledge and handcrafted rules, LMs generalize from diverse data and adapt to various tasks with minimal tuning, acting as a compressed knowledge base. However, LMs in their standard form face challenges with long-horizon tasks, particularly in partially observable multi-agent settings. We propose an LM-based Long-Horizon Planner for Multi-Agent Robotics (LLaMAR), a cognitive architecture for planning that achieves state-of-the-art results in long-horizon tasks within partially observable environments. LLaMAR employs a plan-act-correct-verify framework, allowing self-correction from action execution feedback without relying on oracles or simulators. Additionally, we present MAP-THOR, a comprehensive test suite encompassing household tasks of varying complexity within the AI2-THOR environment. Experiments show that LLaMAR achieves a 30% higher success rate compared to other state-of-the-art LM-based multi-agent planners.
Scalable Multi-Agent Reinforcement Learning through Intelligent Information Aggregation
Nov 03, 2022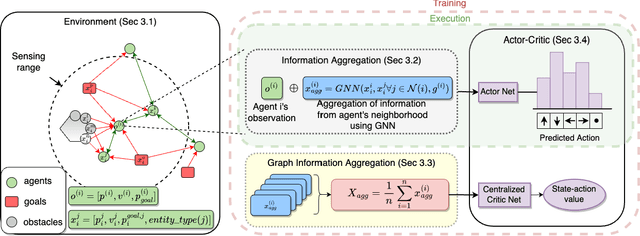
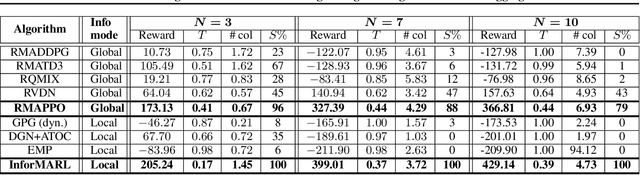
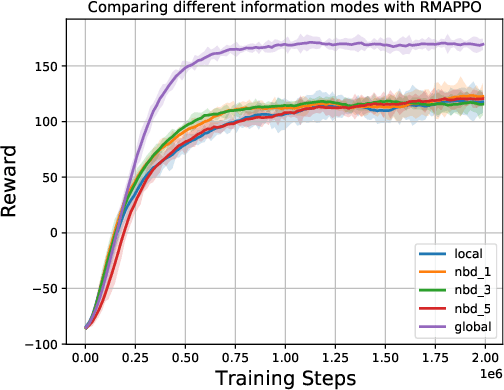
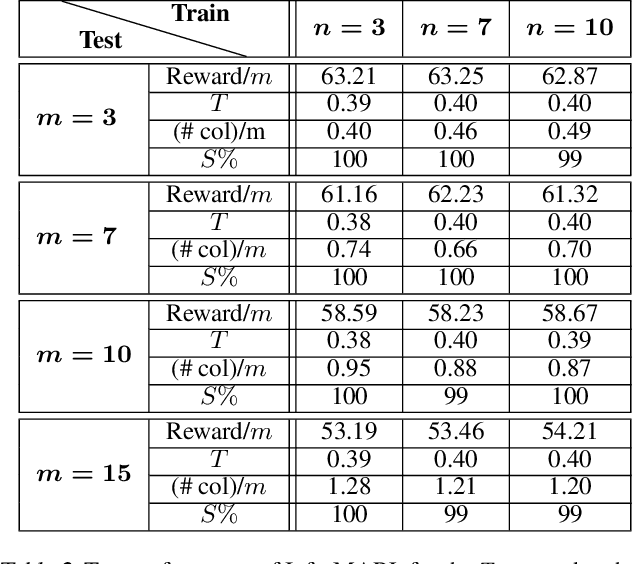
We consider the problem of multi-agent navigation and collision avoidance when observations are limited to the local neighborhood of each agent. We propose InforMARL, a novel architecture for multi-agent reinforcement learning (MARL) which uses local information intelligently to compute paths for all the agents in a decentralized manner. Specifically, InforMARL aggregates information about the local neighborhood of agents for both the actor and the critic using a graph neural network and can be used in conjunction with any standard MARL algorithm. We show that (1) in training, InforMARL has better sample efficiency and performance than baseline approaches, despite using less information, and (2) in testing, it scales well to environments with arbitrary numbers of agents and obstacles.
NICE: Robust Scheduling through Reinforcement Learning-Guided Integer Programming
Sep 24, 2021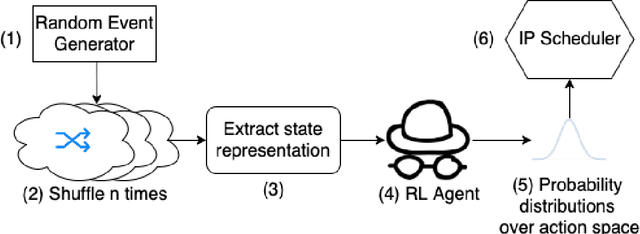
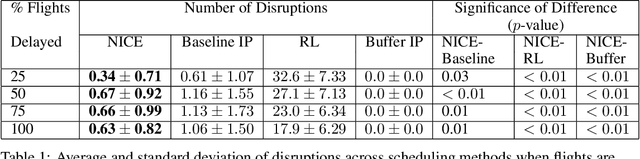
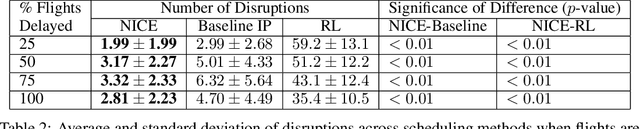
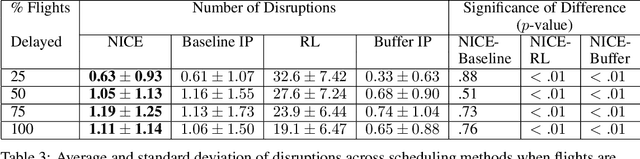
Integer programs provide a powerful abstraction for representing a wide range of real-world scheduling problems. Despite their ability to model general scheduling problems, solving large-scale integer programs (IP) remains a computational challenge in practice. The incorporation of more complex objectives such as robustness to disruptions further exacerbates the computational challenge. We present NICE (Neural network IP Coefficient Extraction), a novel technique that combines reinforcement learning and integer programming to tackle the problem of robust scheduling. More specifically, NICE uses reinforcement learning to approximately represent complex objectives in an integer programming formulation. We use NICE to determine assignments of pilots to a flight crew schedule so as to reduce the impact of disruptions. We compare NICE with (1) a baseline integer programming formulation that produces a feasible crew schedule, and (2) a robust integer programming formulation that explicitly tries to minimize the impact of disruptions. Our experiments show that, across a variety of scenarios, NICE produces schedules resulting in 33\% to 48\% fewer disruptions than the baseline formulation. Moreover, in more severely constrained scheduling scenarios in which the robust integer program fails to produce a schedule within 90 minutes, NICE is able to build robust schedules in less than 2 seconds on average.
Throughput-Fairness Tradeoffs in Mobility Platforms
May 25, 2021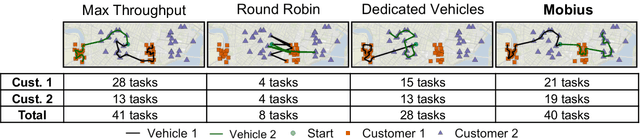
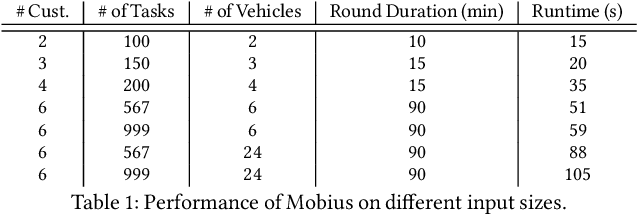
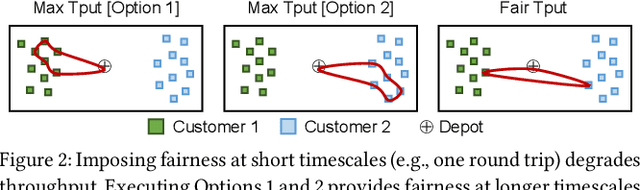
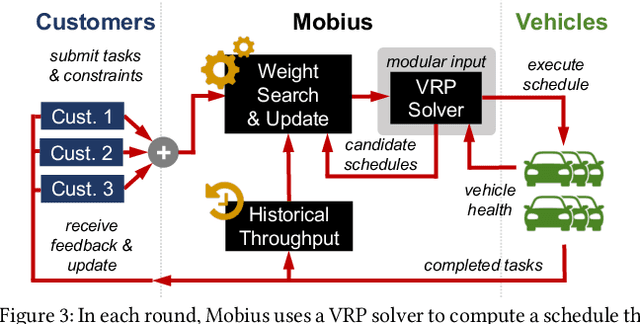
This paper studies the problem of allocating tasks from different customers to vehicles in mobility platforms, which are used for applications like food and package delivery, ridesharing, and mobile sensing. A mobility platform should allocate tasks to vehicles and schedule them in order to optimize both throughput and fairness across customers. However, existing approaches to scheduling tasks in mobility platforms ignore fairness. We introduce Mobius, a system that uses guided optimization to achieve both high throughput and fairness across customers. Mobius supports spatiotemporally diverse and dynamic customer demands. It provides a principled method to navigate inherent tradeoffs between fairness and throughput caused by shared mobility. Our evaluation demonstrates these properties, along with the versatility and scalability of Mobius, using traces gathered from ridesharing and aerial sensing applications. Our ridesharing case study shows that Mobius can schedule more than 16,000 tasks across 40 customers and 200 vehicles in an online manner.