 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Manipulation Strategy Learning by Making Contact Analogies
Nov 14, 2024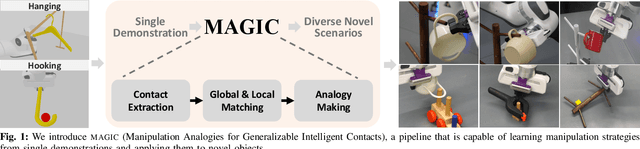

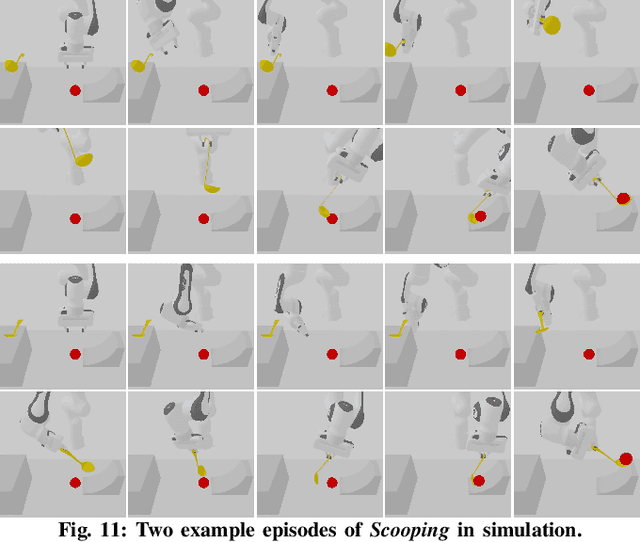
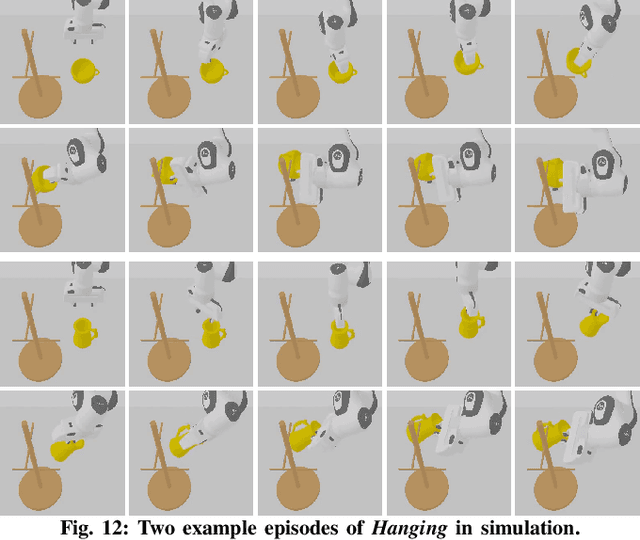
We present a novel approach, MAGIC (manipulation analogies for generalizable intelligent contacts), for one-shot learning of manipulation strategies with fast and extensive generalization to novel objects. By leveraging a reference action trajectory, MAGIC effectively identifies similar contact points and sequences of actions on novel objects to replicate a demonstrated strategy, such as using different hooks to retrieve distant objects of different shapes and sizes. Our method is based on a two-stage contact-point matching process that combines global shape matching using pretrained neural features with local curvature analysis to ensure precise and physically plausible contact points. We experiment with three tasks including scooping, hanging, and hooking objects. MAGIC demonstrates superior performance over existing methods, achieving significant improvements in runtime speed and generalization to different object categories. Website: https://magic-2024.github.io/ .
Stem-OB: Generalizable Visual Imitation Learning with Stem-Like Convergent Observation through Diffusion Inversion
Nov 07, 2024


Visual imitation learning methods demonstrate strong performance, yet they lack generalization when faced with visual input perturbations, including variations in lighting and textures, impeding their real-world application. We propose Stem-OB that utilizes pretrained image diffusion models to suppress low-level visual differences while maintaining high-level scene structures. This image inversion process is akin to transforming the observation into a shared representation, from which other observations stem, with extraneous details removed. Stem-OB contrasts with data-augmentation approaches as it is robust to various unspecified appearance changes without the need for additional training. Our method is a simple yet highly effective plug-and-play solution. Empirical results confirm the effectiveness of our approach in simulated tasks and show an exceptionally significant improvement in real-world applications, with an average increase of 22.2% in success rates compared to the best baseline. See https://hukz18.github.io/Stem-Ob/ for more info.
Rethinking Transformers in Solving POMDPs
May 30, 2024



Sequential decision-making algorithms such as reinforcement learning (RL) in real-world scenarios inevitably face environments with partial observability. This paper scrutinizes the effectiveness of a popular architecture, namely Transformers, in Partially Observable Markov Decision Processes (POMDPs) and reveals its theoretical limitations. We establish that regular languages, which Transformers struggle to model, are reducible to POMDPs. This poses a significant challenge for Transformers in learning POMDP-specific inductive biases, due to their lack of inherent recurrence found in other models like RNNs. This paper casts doubt on the prevalent belief in Transformers as sequence models for RL and proposes to introduce a point-wise recurrent structure. The Deep Linear Recurrent Unit (LRU) emerges as a well-suited alternative for Partially Observable RL, with empirical results highlighting the sub-optimal performance of the Transformer and considerable strength of LRU.
Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning
Nov 07, 2023
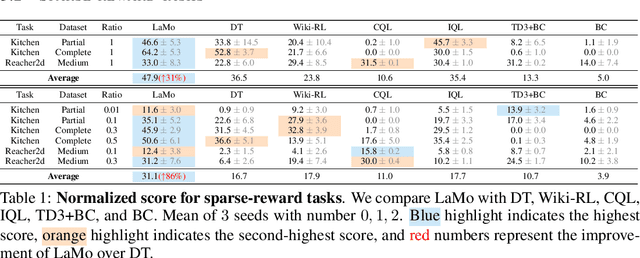
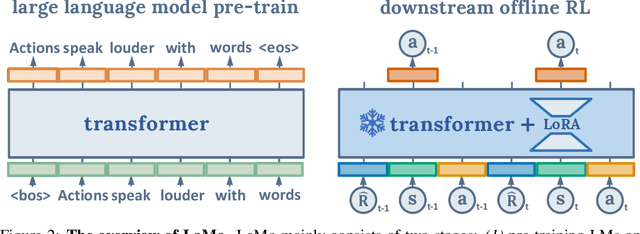
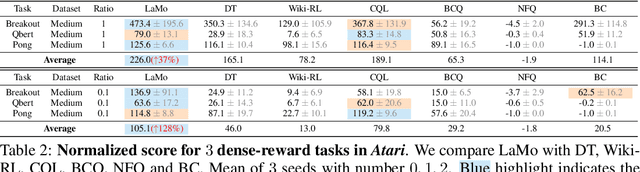
Offline reinforcement learning (RL) aims to find a near-optimal policy using pre-collected datasets. In real-world scenarios, data collection could be costly and risky; therefore, offline RL becomes particularly challenging when the in-domain data is limited. Given recent advances in Large Language Models (LLMs) and their few-shot learning prowess, this paper introduces $\textbf{La}$nguage Models for $\textbf{Mo}$tion Control ($\textbf{LaMo}$), a general framework based on Decision Transformers to effectively use pre-trained Language Models (LMs) for offline RL. Our framework highlights four crucial components: (1) Initializing Decision Transformers with sequentially pre-trained LMs, (2) employing the LoRA fine-tuning method, in contrast to full-weight fine-tuning, to combine the pre-trained knowledge from LMs and in-domain knowledge effectively, (3) using the non-linear MLP transformation instead of linear projections, to generate embeddings, and (4) integrating an auxiliary language prediction loss during fine-tuning to stabilize the LMs and retain their original abilities on languages. Empirical results indicate $\textbf{LaMo}$ achieves state-of-the-art performance in sparse-reward tasks and closes the gap between value-based offline RL methods and decision transformers in dense-reward tasks. In particular, our method demonstrates superior performance in scenarios with limited data samples. Our project website is $\href{https://lamo2023.github.io}{\text{this https URL}}$.
H-InDex: Visual Reinforcement Learning with Hand-Informed Representations for Dexterous Manipulation
Oct 13, 2023Human hands possess remarkable dexterity and have long served as a source of inspiration for robotic manipulation. In this work, we propose a human $\textbf{H}$and$\textbf{-In}$formed visual representation learning framework to solve difficult $\textbf{Dex}$terous manipulation tasks ($\textbf{H-InDex}$) with reinforcement learning. Our framework consists of three stages: (i) pre-training representations with 3D human hand pose estimation, (ii) offline adapting representations with self-supervised keypoint detection, and (iii) reinforcement learning with exponential moving average BatchNorm. The last two stages only modify $0.36\%$ parameters of the pre-trained representation in total, ensuring the knowledge from pre-training is maintained to the full extent. We empirically study 12 challenging dexterous manipulation tasks and find that H-InDex largely surpasses strong baseline methods and the recent visual foundation models for motor control. Code is available at https://yanjieze.com/H-InDex .