 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVine: Reality-Aligned Evaluation for Agentic Search
Jul 22, 2025

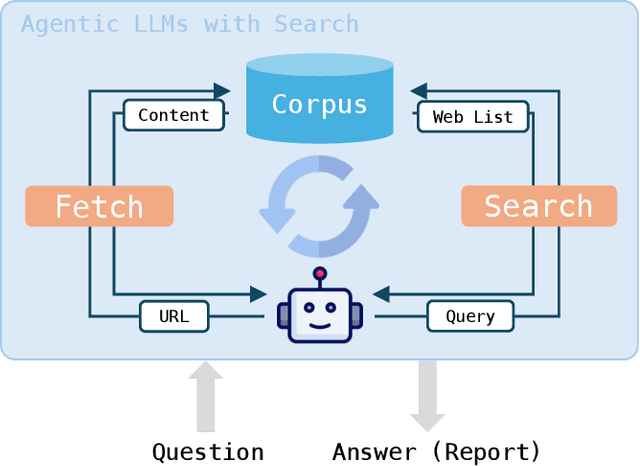
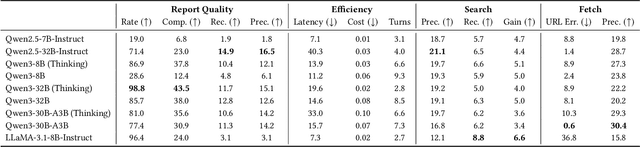
Agentic search, as a more autonomous and adaptive paradigm of retrieval augmentation, is driving the evolution of intelligent search systems. However, existing evaluation frameworks fail to align well with the goals of agentic search. First, the complex queries commonly used in current benchmarks often deviate from realistic user search scenarios. Second, prior approaches tend to introduce noise when extracting ground truth for end-to-end evaluations, leading to distorted assessments at a fine-grained level. Third, most current frameworks focus solely on the quality of final answers, neglecting the evaluation of the iterative process inherent to agentic search. To address these limitations, we propose RAVine -- a Reality-Aligned eValuation framework for agentic LLMs with search. RAVine targets multi-point queries and long-form answers that better reflect user intents, and introduces an attributable ground truth construction strategy to enhance the accuracy of fine-grained evaluation. Moreover, RAVine examines model's interaction with search tools throughout the iterative process, and accounts for factors of efficiency. We benchmark a series of models using RAVine and derive several insights, which we hope will contribute to advancing the development of agentic search systems. The code and datasets are available at https://github.com/SwordFaith/RAVine.
Training a Utility-based Retriever Through Shared Context Attribution for Retrieval-Augmented Language Models
Apr 01, 2025Retrieval-Augmented Language Models boost task performance, owing to the retriever that provides external knowledge. Although crucial, the retriever primarily focuses on semantics relevance, which may not always be effective for generation. Thus, utility-based retrieval has emerged as a promising topic, prioritizing passages that provides valid benefits for downstream tasks. However, due to insufficient understanding, capturing passage utility accurately remains unexplored. This work proposes SCARLet, a framework for training utility-based retrievers in RALMs, which incorporates two key factors, multi-task generalization and inter-passage interaction. First, SCARLet constructs shared context on which training data for various tasks is synthesized. This mitigates semantic bias from context differences, allowing retrievers to focus on learning task-specific utility for better task generalization. Next, SCARLet uses a perturbation-based attribution method to estimate passage-level utility for shared context, which reflects interactions between passages and provides more accurate feedback. We evaluate our approach on ten datasets across various tasks, both in-domain and out-of-domain, showing that retrievers trained by SCARLet consistently improve the overall performance of RALMs.
Fast and Continual Knowledge Graph Embedding via Incremental LoRA
Jul 08, 2024



Continual Knowledge Graph Embedding (CKGE) aims to efficiently learn new knowledge and simultaneously preserve old knowledge. Dominant approaches primarily focus on alleviating catastrophic forgetting of old knowledge but neglect efficient learning for the emergence of new knowledge. However, in real-world scenarios, knowledge graphs (KGs) are continuously growing, which brings a significant challenge to fine-tuning KGE models efficiently. To address this issue, we propose a fast CKGE framework (\model), incorporating an incremental low-rank adapter (\mec) mechanism to efficiently acquire new knowledge while preserving old knowledge. Specifically, to mitigate catastrophic forgetting, \model\ isolates and allocates new knowledge to specific layers based on the fine-grained influence between old and new KGs. Subsequently, to accelerate fine-tuning, \model\ devises an efficient \mec\ mechanism, which embeds the specific layers into incremental low-rank adapters with fewer training parameters. Moreover, \mec\ introduces adaptive rank allocation, which makes the LoRA aware of the importance of entities and adjusts its rank scale adaptively. We conduct experiments on four public datasets and two new datasets with a larger initial scale. Experimental results demonstrate that \model\ can reduce training time by 34\%-49\% while still achieving competitive link prediction performance against state-of-the-art models on four public datasets (average MRR score of 21.0\% vs. 21.1\%).Meanwhile, on two newly constructed datasets, \model\ saves 51\%-68\% training time and improves link prediction performance by 1.5\%.
ALiiCE: Evaluating Positional Fine-grained Citation Generation
Jun 19, 2024



Large Language Models (LLMs) can enhance the credibility and verifiability by generating text with citations. However, existing tasks and evaluation methods are predominantly limited to sentence-level statement, neglecting the significance of positional fine-grained citations that can appear anywhere within sentences. To facilitate further exploration of the fine-grained citation generation, we propose ALiiCE, the first automatic evaluation framework for this task. Our framework first parses the sentence claim into atomic claims via dependency analysis and then calculates citation quality at the atomic claim level. ALiiCE introduces three novel metrics for positional fined-grained citation quality assessment, including positional fine-grained citation recall and precision, and coefficient of variation of citation positions. We evaluate the positional fine-grained citation generation performance of several LLMs on two long-form QA datasets. Our experiments and analyses demonstrate the effectiveness and reasonableness of ALiiCE. The results also indicate that existing LLMs still struggle to provide positional fine-grained citations.
Towards Continual Knowledge Graph Embedding via Incremental Distillation
May 07, 2024



Traditional knowledge graph embedding (KGE) methods typically require preserving the entire knowledge graph (KG) with significant training costs when new knowledge emerges. To address this issue, the continual knowledge graph embedding (CKGE) task has been proposed to train the KGE model by learning emerging knowledge efficiently while simultaneously preserving decent old knowledge. However, the explicit graph structure in KGs, which is critical for the above goal, has been heavily ignored by existing CKGE methods. On the one hand, existing methods usually learn new triples in a random order, destroying the inner structure of new KGs. On the other hand, old triples are preserved with equal priority, failing to alleviate catastrophic forgetting effectively. In this paper, we propose a competitive method for CKGE based on incremental distillation (IncDE), which considers the full use of the explicit graph structure in KGs. First, to optimize the learning order, we introduce a hierarchical strategy, ranking new triples for layer-by-layer learning. By employing the inter- and intra-hierarchical orders together, new triples are grouped into layers based on the graph structure features. Secondly, to preserve the old knowledge effectively, we devise a novel incremental distillation mechanism, which facilitates the seamless transfer of entity representations from the previous layer to the next one, promoting old knowledge preservation. Finally, we adopt a two-stage training paradigm to avoid the over-corruption of old knowledge influenced by under-trained new knowledge. Experimental results demonstrate the superiority of IncDE over state-of-the-art baselines. Notably, the incremental distillation mechanism contributes to improvements of 0.2%-6.5% in the mean reciprocal rank (MRR) score.
Few-Shot Stance Detection via Target-Aware Prompt Distillation
Jun 27, 2022



Stance detection aims to identify whether the author of a text is in favor of, against, or neutral to a given target. The main challenge of this task comes two-fold: few-shot learning resulting from the varying targets and the lack of contextual information of the targets. Existing works mainly focus on solving the second issue by designing attention-based models or introducing noisy external knowledge, while the first issue remains under-explored. In this paper, inspired by the potential capability of pre-trained language models (PLMs) serving as knowledge bases and few-shot learners, we propose to introduce prompt-based fine-tuning for stance detection. PLMs can provide essential contextual information for the targets and enable few-shot learning via prompts. Considering the crucial role of the target in stance detection task, we design target-aware prompts and propose a novel verbalizer. Instead of mapping each label to a concrete word, our verbalizer maps each label to a vector and picks the label that best captures the correlation between the stance and the target. Moreover, to alleviate the possible defect of dealing with varying targets with a single hand-crafted prompt, we propose to distill the information learned from multiple prompts. Experimental results show the superior performance of our proposed model in both full-data and few-shot scenarios.
Label-Consistency based Graph Neural Networks for Semi-supervised Node Classification
Jul 27, 2020



Graph neural networks (GNNs) achieve remarkable success in graph-based semi-supervised node classification, leveraging the information from neighboring nodes to improve the representation learning of target node. The success of GNNs at node classification depends on the assumption that connected nodes tend to have the same label. However, such an assumption does not always work, limiting the performance of GNNs at node classification. In this paper, we propose label-consistency based graph neural network(LC-GNN), leveraging node pairs unconnected but with the same labels to enlarge the receptive field of nodes in GNNs. Experiments on benchmark datasets demonstrate the proposed LC-GNN outperforms traditional GNNs in graph-based semi-supervised node classification.We further show the superiority of LC-GNN in sparse scenarios with only a handful of labeled nodes.
Coupled Graph Neural Networks for Predicting the Popularity of Online Content
Jun 21, 2019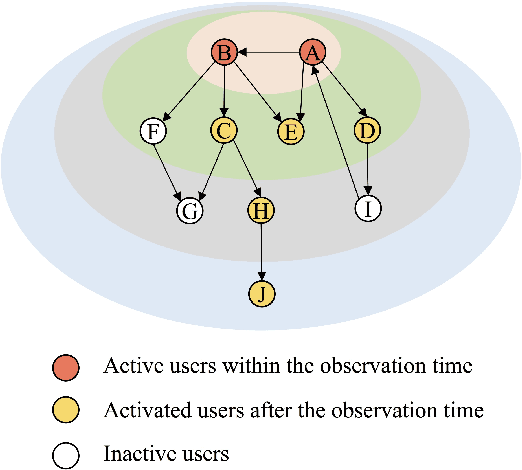

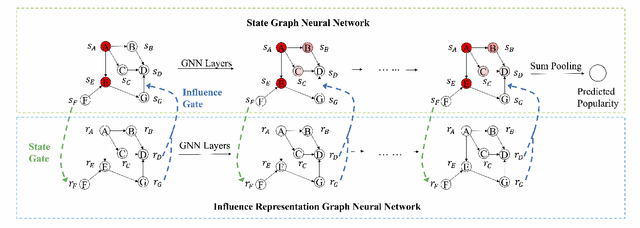
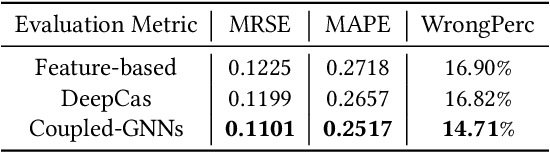
Predicting the popularity of online content in social network is an important problem for the practice of information dissemination, advertising, and recommendation. Previous methods mainly leverage demographics, temporal and structural patterns of early adopters for popularity prediction. These methods ignore the interaction between early adopters and potential adopters or the interactions among potential adopters over social networks. Consequently, they fail to capture the cascading effect triggered by early adopters in social networks, and thus have limited predictive power. In this paper, we consider the problem of network-aware popularity prediction, leveraging both early adopters and social networks among users for popularity prediction. We propose a novel method, namely Coupled-GNNs, which use two coupled graph neural networks to capture the cascading effect in information diffusion. One graph neural network models the interpersonal influence, gated by the adoption state of users. The other graph neural network models the adoption state of users via interpersonal influence from their neighbors. Through such an iterative aggregation of the neighborhood, the proposed method naturally captures the cascading effect of information diffusion in social networks. Experiments conducted on both synthetic data and real-world Sina Weibo data demonstrate that our method significantly outperforms the state-of-the-art methods for popularity prediction.
A Graph Auto-Encoder for Attributed Network Embedding
Jun 20, 2019
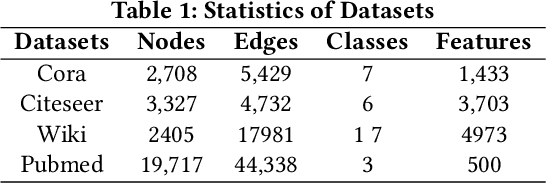

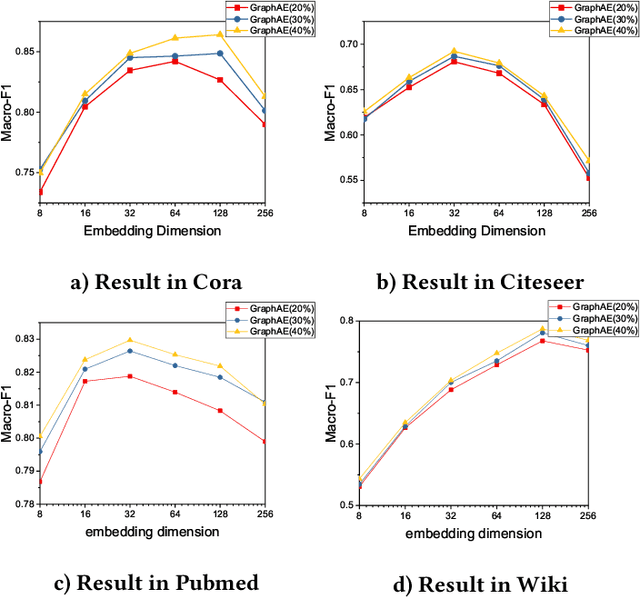
Attributed network embedding aims to learn low-dimensional node representations from both network structure and node attributes. Existing methods can be categorized into two groups: (1) the first group learns two separated node representations from network structure and node attribute respectively and concatenating them together; (2) the other group obtains node representations by translating node attributes into network structure or vice versa. However, both groups have their drawbacks. The first group neglects the correlation between these two types of information, while the second group assumes strong dependence between network structure and node attributes. In this paper, we address attributed network embedding from a novel perspective, i.e., learning representation of a target node via modeling its attributed local subgraph. To achieve this goal, we propose a novel graph auto-encoder framework, namely GraphAE. For a target node, GraphAE first aggregates the attribute information from its attributed local subgrah, obtaining its low-dimensional representation. Next, GraphAE diffuses its representation to nodes in its local subgraph to reconstruct their attribute information. Our proposed perspective transfroms the problem of learning node representations into the problem of modeling the context information manifested in both network structure and node attributes, thus having high capacity to learn good node representations for attributed network. Extensive experimental results on real-world datasets demonstrate that the proposed framework outperforms the state-of-the-art network approaches at the tasks of link prediction and node classification.