 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Hierarchy Adaptation via Chain of Iterative Reasoning for Few-shot Hierarchical Text Classification
Paper and Code
Jul 12, 2024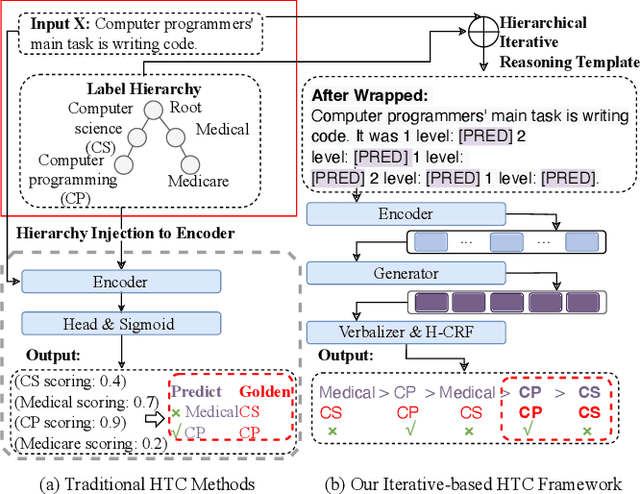
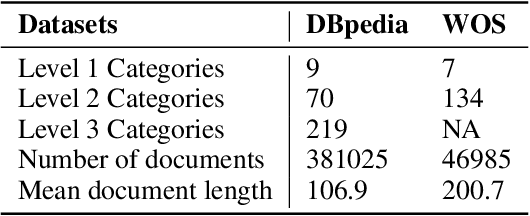
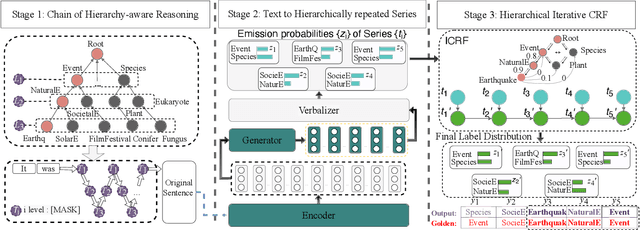
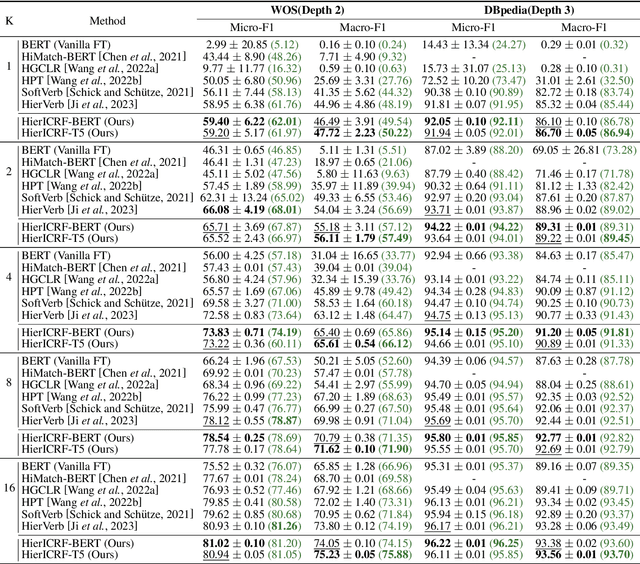
Recently, various pre-trained language models (PLMs) have been proposed to prove their impressive performances on a wide range of few-shot tasks. However, limited by the unstructured prior knowledge in PLMs, it is difficult to maintain consistent performance on complex structured scenarios, such as hierarchical text classification (HTC), especially when the downstream data is extremely scarce. The main challenge is how to transfer the unstructured semantic space in PLMs to the downstream domain hierarchy. Unlike previous work on HTC which directly performs multi-label classification or uses graph neural network (GNN) to inject label hierarchy, in this work, we study the HTC problem under a few-shot setting to adapt knowledge in PLMs from an unstructured manner to the downstream hierarchy. Technically, we design a simple yet effective method named Hierarchical Iterative Conditional Random Field (HierICRF) to search the most domain-challenging directions and exquisitely crafts domain-hierarchy adaptation as a hierarchical iterative language modeling problem, and then it encourages the model to make hierarchical consistency self-correction during the inference, thereby achieving knowledge transfer with hierarchical consistency preservation. We perform HierICRF on various architectures, and extensive experiments on two popular HTC datasets demonstrate that prompt with HierICRF significantly boosts the few-shot HTC performance with an average Micro-F1 by 28.80% to 1.50% and Macro-F1 by 36.29% to 1.5% over the previous state-of-the-art (SOTA) baselines under few-shot settings, while remaining SOTA hierarchical consistency performance.