 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCuRL: Adaptive Curriculum Reinforcement Learning with Invalid Sample Mitigation and Historical Revisiting
Nov 12, 2025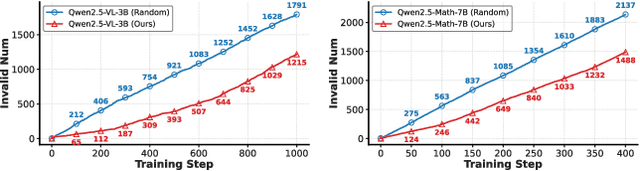
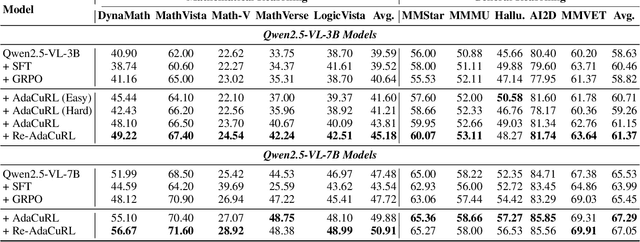
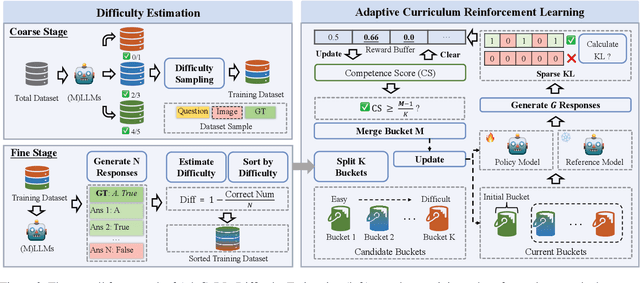
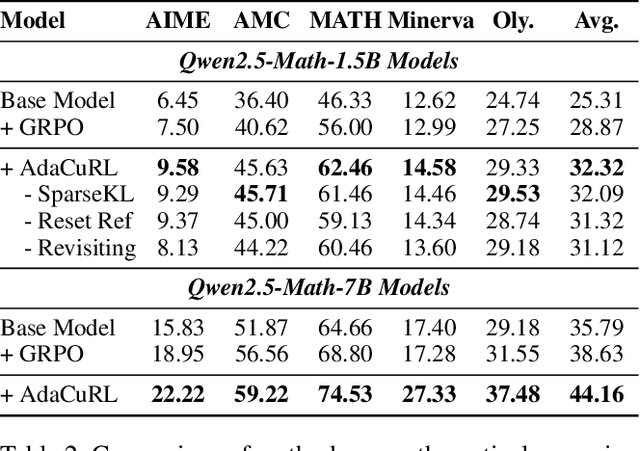
Reinforcement learning (RL) has demonstrated considerable potential for enhancing reasoning in large language models (LLMs). However, existing methods suffer from Gradient Starvation and Policy Degradation when training directly on samples with mixed difficulty. To mitigate this, prior approaches leverage Chain-of-Thought (CoT) data, but the construction of high-quality CoT annotations remains labor-intensive. Alternatively, curriculum learning strategies have been explored but frequently encounter challenges, such as difficulty mismatch, reliance on manual curriculum design, and catastrophic forgetting. To address these issues, we propose AdaCuRL, a Adaptive Curriculum Reinforcement Learning framework that integrates coarse-to-fine difficulty estimation with adaptive curriculum scheduling. This approach dynamically aligns data difficulty with model capability and incorporates a data revisitation mechanism to mitigate catastrophic forgetting. Furthermore, AdaCuRL employs adaptive reference and sparse KL strategies to prevent Policy Degradation. Extensive experiments across diverse reasoning benchmarks demonstrate that AdaCuRL consistently achieves significant performance improvements on both LLMs and MLLMs.
GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
Apr 03, 2025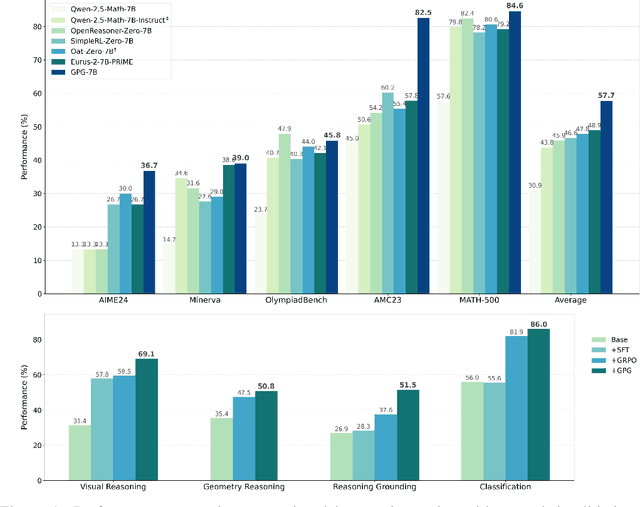
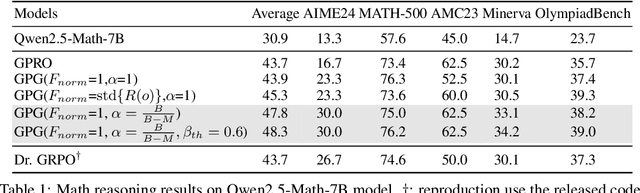
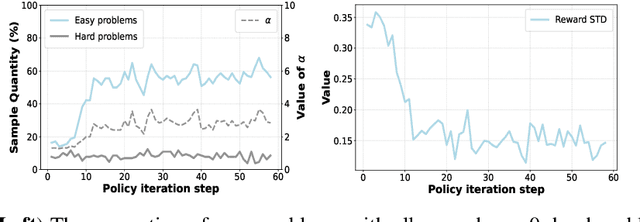

Reinforcement Learning (RL) can directly enhance the reasoning capabilities of large language models without extensive reliance on Supervised Fine-Tuning (SFT). In this work, we revisit the traditional Policy Gradient (PG) mechanism and propose a minimalist RL approach termed Group Policy Gradient (GPG). Unlike conventional methods, GPG directly optimize the original RL objective, thus obviating the need for surrogate loss functions. As illustrated in our paper, by eliminating both the critic and reference models, and avoiding KL divergence constraints, our approach significantly simplifies the training process when compared to Group Relative Policy Optimization (GRPO). Our approach achieves superior performance without relying on auxiliary techniques or adjustments. Extensive experiments demonstrate that our method not only reduces computational costs but also consistently outperforms GRPO across various unimodal and multimodal tasks. Our code is available at https://github.com/AMAP-ML/GPG.
MMGenBench: Evaluating the Limits of LMMs from the Text-to-Image Generation Perspective
Nov 21, 2024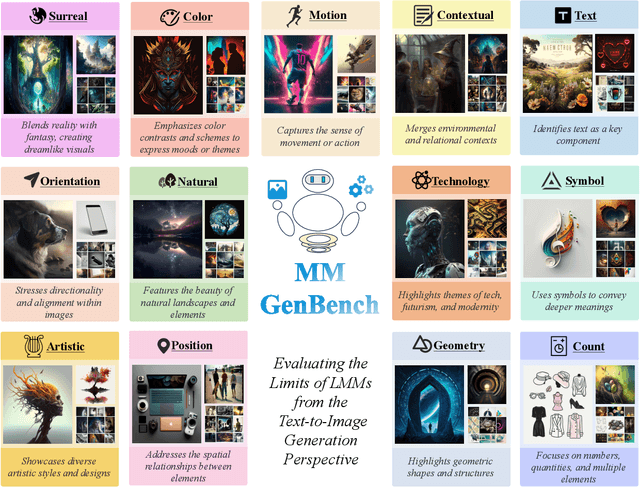
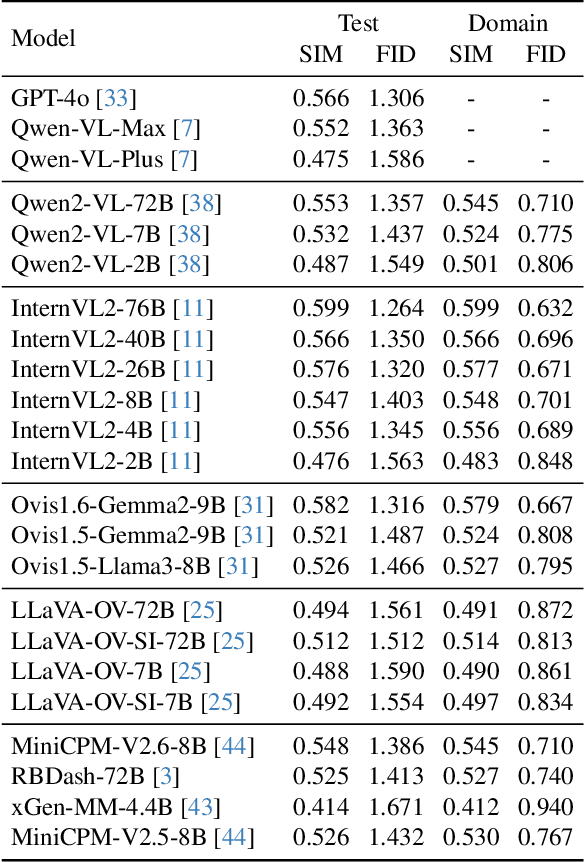
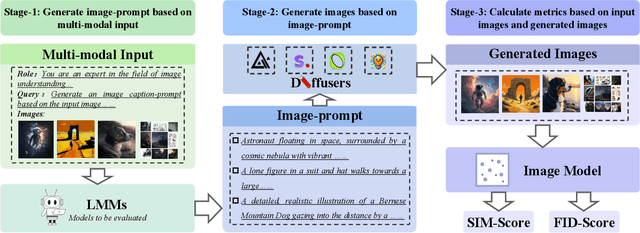
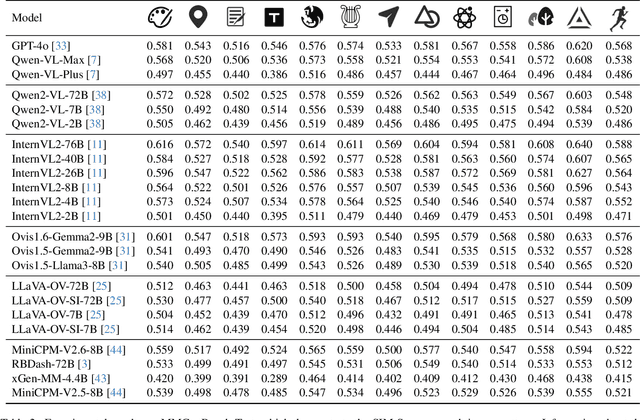
Large Multimodal Models (LMMs) have demonstrated remarkable capabilities. While existing benchmarks for evaluating LMMs mainly focus on image comprehension, few works evaluate them from the image generation perspective. To address this issue, we propose a straightforward automated evaluation pipeline. Specifically, this pipeline requires LMMs to generate an image-prompt from a given input image. Subsequently, it employs text-to-image generative models to create a new image based on these generated prompts. Finally, we evaluate the performance of LMMs by comparing the original image with the generated one. Furthermore, we introduce MMGenBench-Test, a comprehensive benchmark developed to evaluate LMMs across 13 distinct image patterns, and MMGenBench-Domain, targeting the performance evaluation of LMMs within the generative image domain. A thorough evaluation involving over 50 popular LMMs demonstrates the effectiveness and reliability in both the pipeline and benchmark. Our observations indicate that numerous LMMs excelling in existing benchmarks fail to adequately complete the basic tasks, related to image understanding and description. This finding highlights the substantial potential for performance improvement in current LMMs and suggests avenues for future model optimization. Concurrently, our pipeline facilitates the efficient assessment of LMMs performance across diverse domains by using solely image inputs.
Improving the Consistency in Cross-Lingual Cross-Modal Retrieval with 1-to-K Contrastive Learning
Jun 26, 2024Cross-lingual Cross-modal Retrieval (CCR) is an essential task in web search, which aims to break the barriers between modality and language simultaneously and achieves image-text retrieval in the multi-lingual scenario with a single model. In recent years, excellent progress has been made based on cross-lingual cross-modal pre-training; particularly, the methods based on contrastive learning on large-scale data have significantly improved retrieval tasks. However, these methods directly follow the existing pre-training methods in the cross-lingual or cross-modal domain, leading to two problems of inconsistency in CCR: The methods with cross-lingual style suffer from the intra-modal error propagation, resulting in inconsistent recall performance across languages in the whole dataset. The methods with cross-modal style suffer from the inter-modal optimization direction bias, resulting in inconsistent rank across languages within each instance, which cannot be reflected by Recall@K. To solve these problems, we propose a simple but effective 1-to-K contrastive learning method, which treats each language equally and eliminates error propagation and optimization bias. In addition, we propose a new evaluation metric, Mean Rank Variance (MRV), to reflect the rank inconsistency across languages within each instance. Extensive experiments on four CCR datasets show that our method improves both recall rates and MRV with smaller-scale pre-trained data, achieving the new state-of-art.
Cross-Modal and Uni-Modal Soft-Label Alignment for Image-Text Retrieval
Mar 08, 2024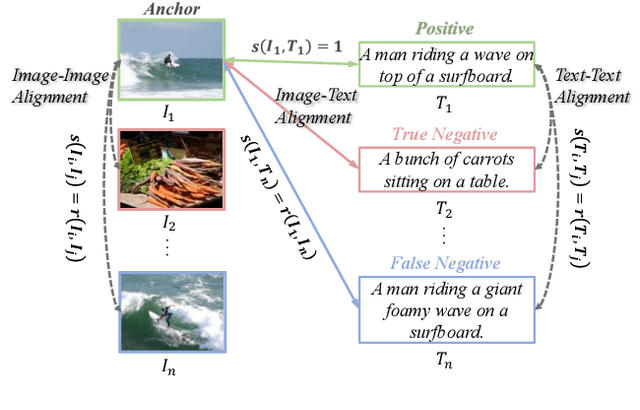
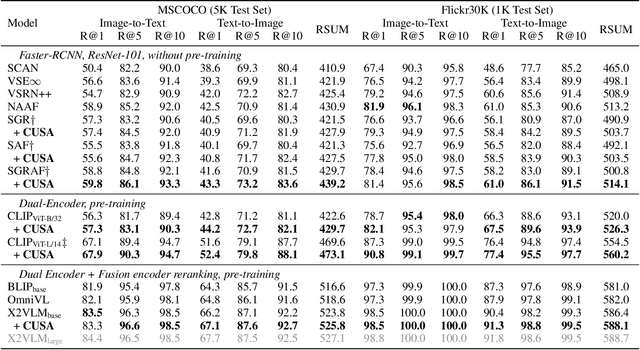
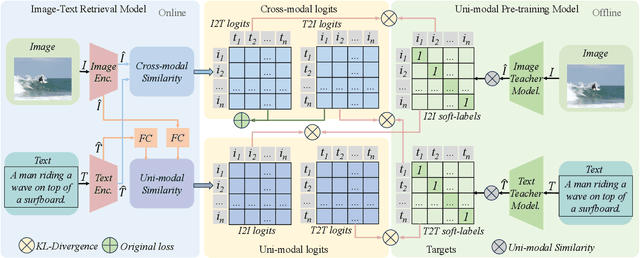
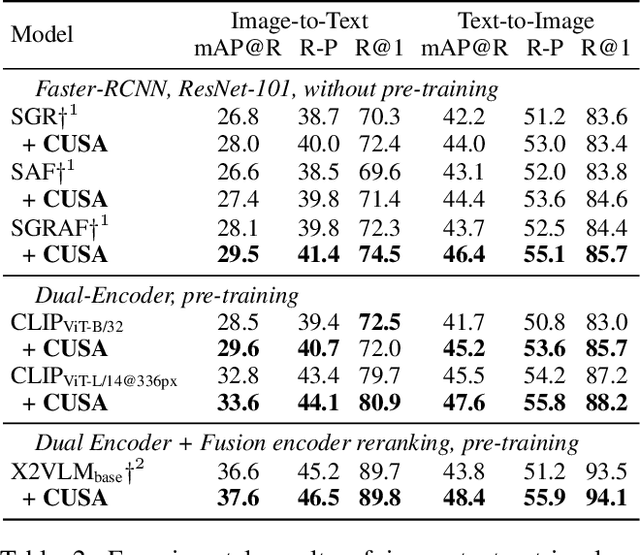
Current image-text retrieval methods have demonstrated impressive performance in recent years. However, they still face two problems: the inter-modal matching missing problem and the intra-modal semantic loss problem. These problems can significantly affect the accuracy of image-text retrieval. To address these challenges, we propose a novel method called Cross-modal and Uni-modal Soft-label Alignment (CUSA). Our method leverages the power of uni-modal pre-trained models to provide soft-label supervision signals for the image-text retrieval model. Additionally, we introduce two alignment techniques, Cross-modal Soft-label Alignment (CSA) and Uni-modal Soft-label Alignment (USA), to overcome false negatives and enhance similarity recognition between uni-modal samples. Our method is designed to be plug-and-play, meaning it can be easily applied to existing image-text retrieval models without changing their original architectures. Extensive experiments on various image-text retrieval models and datasets, we demonstrate that our method can consistently improve the performance of image-text retrieval and achieve new state-of-the-art results. Furthermore, our method can also boost the uni-modal retrieval performance of image-text retrieval models, enabling it to achieve universal retrieval. The code and supplementary files can be found at https://github.com/lerogo/aaai24_itr_cusa.