 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSifterNet: A Generalized and Model-Agnostic Trigger Purification Approach
May 20, 2025Aiming at resisting backdoor attacks in convolution neural networks and vision Transformer-based large model, this paper proposes a generalized and model-agnostic trigger-purification approach resorting to the classic Ising model. To date, existing trigger detection/removal studies usually require to know the detailed knowledge of target model in advance, access to a large number of clean samples or even model-retraining authorization, which brings the huge inconvenience for practical applications, especially inaccessible to target model. An ideal countermeasure ought to eliminate the implanted trigger without regarding whatever the target models are. To this end, a lightweight and black-box defense approach SifterNet is proposed through leveraging the memorization-association functionality of Hopfield network, by which the triggers of input samples can be effectively purified in a proper manner. The main novelty of our proposed approach lies in the introduction of ideology of Ising model. Extensive experiments also validate the effectiveness of our approach in terms of proper trigger purification and high accuracy achievement, and compared to the state-of-the-art baselines under several commonly-used datasets, our SiferNet has a significant superior performance.
CausalTAD: Causal Implicit Generative Model for Debiased Online Trajectory Anomaly Detection
Dec 25, 2024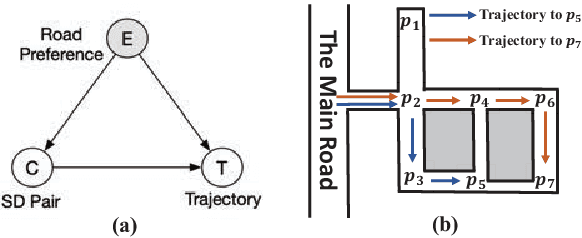
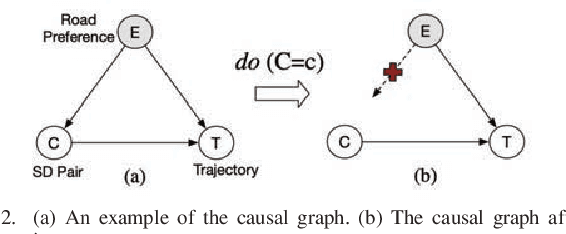
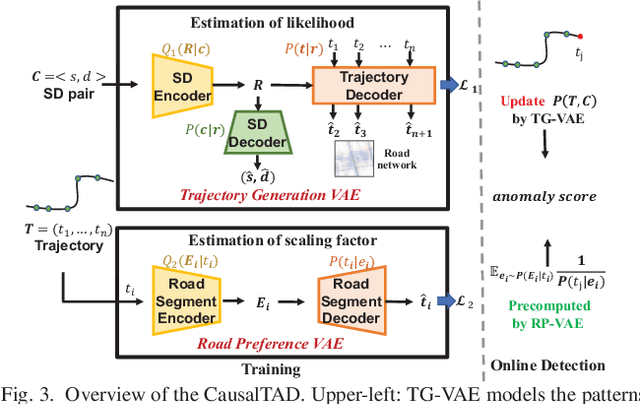
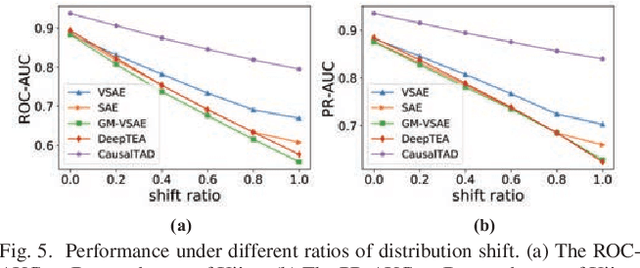
Trajectory anomaly detection, aiming to estimate the anomaly risk of trajectories given the Source-Destination (SD) pairs, has become a critical problem for many real-world applications. Existing solutions directly train a generative model for observed trajectories and calculate the conditional generative probability $P({T}|{C})$ as the anomaly risk, where ${T}$ and ${C}$ represent the trajectory and SD pair respectively. However, we argue that the observed trajectories are confounded by road network preference which is a common cause of both SD distribution and trajectories. Existing methods ignore this issue limiting their generalization ability on out-of-distribution trajectories. In this paper, we define the debiased trajectory anomaly detection problem and propose a causal implicit generative model, namely CausalTAD, to solve it. CausalTAD adopts do-calculus to eliminate the confounding bias of road network preference and estimates $P({T}|do({C}))$ as the anomaly criterion. Extensive experiments show that CausalTAD can not only achieve superior performance on trained trajectories but also generally improve the performance of out-of-distribution data, with improvements of $2.1\% \sim 5.7\%$ and $10.6\% \sim 32.7\%$ respectively.
STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Jun 27, 2024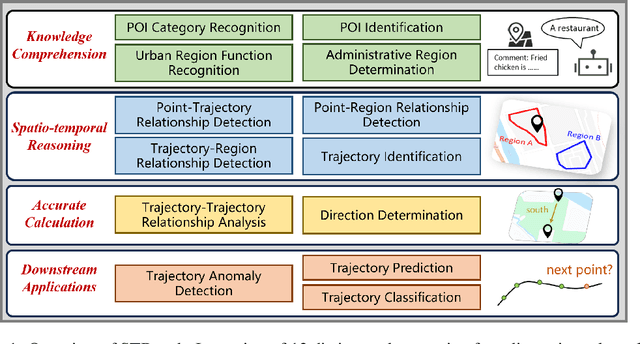

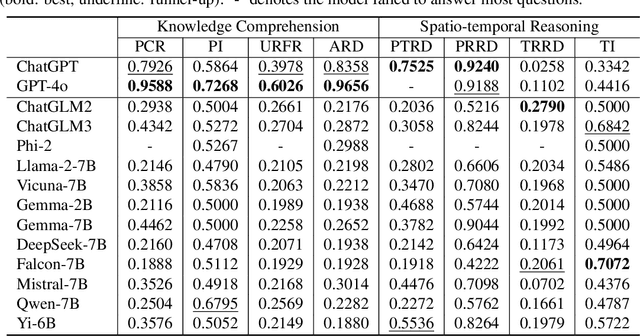
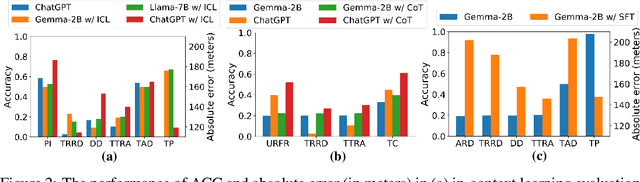
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.