 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalTAD: Causal Implicit Generative Model for Debiased Online Trajectory Anomaly Detection
Dec 25, 2024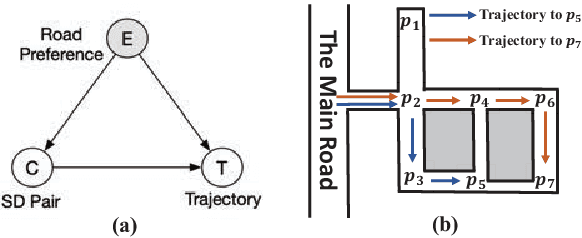
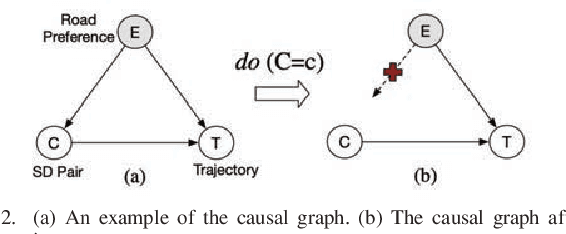
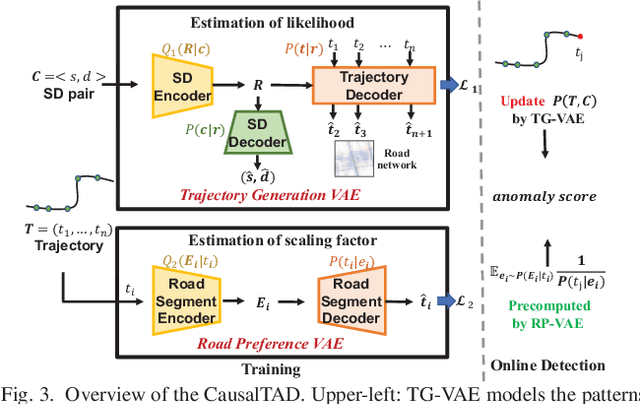
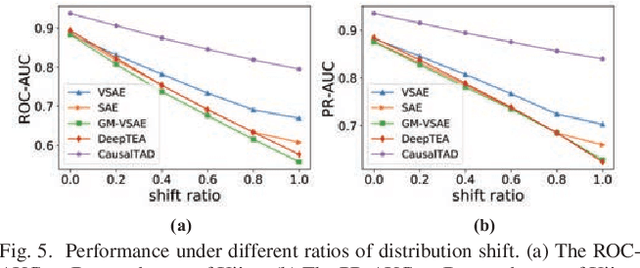
Trajectory anomaly detection, aiming to estimate the anomaly risk of trajectories given the Source-Destination (SD) pairs, has become a critical problem for many real-world applications. Existing solutions directly train a generative model for observed trajectories and calculate the conditional generative probability $P({T}|{C})$ as the anomaly risk, where ${T}$ and ${C}$ represent the trajectory and SD pair respectively. However, we argue that the observed trajectories are confounded by road network preference which is a common cause of both SD distribution and trajectories. Existing methods ignore this issue limiting their generalization ability on out-of-distribution trajectories. In this paper, we define the debiased trajectory anomaly detection problem and propose a causal implicit generative model, namely CausalTAD, to solve it. CausalTAD adopts do-calculus to eliminate the confounding bias of road network preference and estimates $P({T}|do({C}))$ as the anomaly criterion. Extensive experiments show that CausalTAD can not only achieve superior performance on trained trajectories but also generally improve the performance of out-of-distribution data, with improvements of $2.1\% \sim 5.7\%$ and $10.6\% \sim 32.7\%$ respectively.
Multi-Modal Coreference Resolution with the Correlation between Space Structures
Sep 01, 2018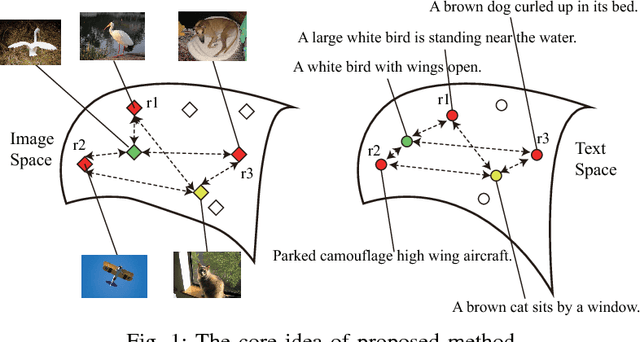
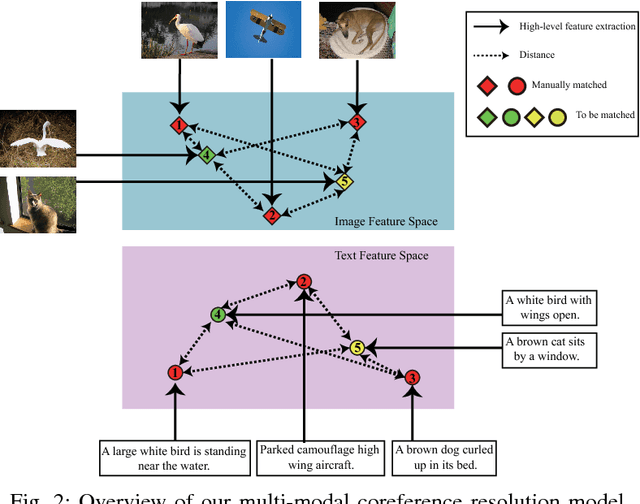
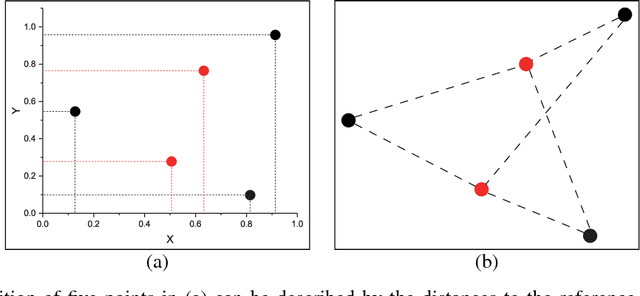
Multi-modal data is becoming more common in big data background. Finding the semantically similar objects from different modality is one of the heart problems of multi-modal learning. Most of the current methods try to learn the inter-modal correlation with extrinsic supervised information, while intrinsic structural information of each modality is neglected. The performance of these methods heavily depends on the richness of training samples. However, obtaining the multi-modal training samples is still a labor and cost intensive work. In this paper, we bring a extrinsic correlation between the space structures of each modalities in coreference resolution. With this correlation, a semi-supervised learning model for multi-modal coreference resolution is proposed. We firstly extract high-level features of images and text, then compute the distances of each object from some reference points to build the space structure of each modality. With a shared reference point set, the space structures of each modality are correlated. We employ the correlation to build a commonly shared space that the semantic distance between multi-modal objects can be computed directly. The experiments on two multi-modal datasets show that our model performs better than the existing methods with insufficient training data.