 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Coreference Resolution with the Correlation between Space Structures
Paper and Code
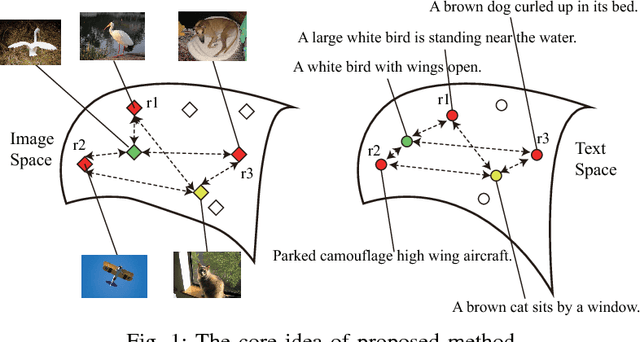
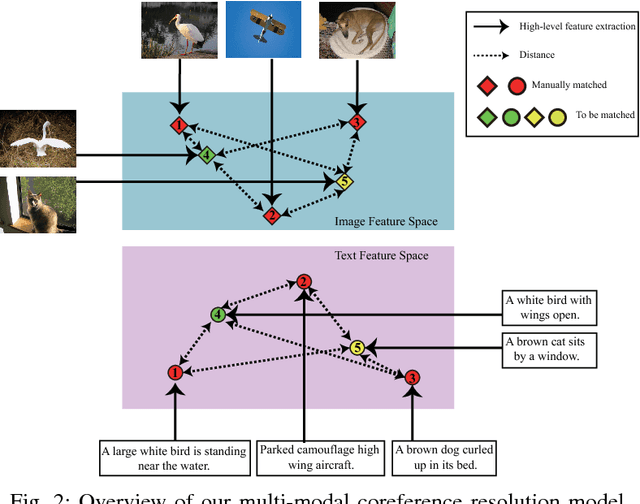
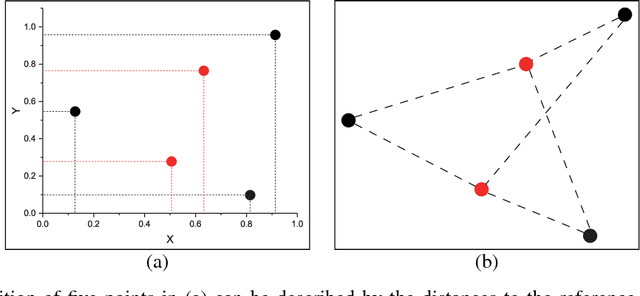
Multi-modal data is becoming more common in big data background. Finding the semantically similar objects from different modality is one of the heart problems of multi-modal learning. Most of the current methods try to learn the inter-modal correlation with extrinsic supervised information, while intrinsic structural information of each modality is neglected. The performance of these methods heavily depends on the richness of training samples. However, obtaining the multi-modal training samples is still a labor and cost intensive work. In this paper, we bring a extrinsic correlation between the space structures of each modalities in coreference resolution. With this correlation, a semi-supervised learning model for multi-modal coreference resolution is proposed. We firstly extract high-level features of images and text, then compute the distances of each object from some reference points to build the space structure of each modality. With a shared reference point set, the space structures of each modality are correlated. We employ the correlation to build a commonly shared space that the semantic distance between multi-modal objects can be computed directly. The experiments on two multi-modal datasets show that our model performs better than the existing methods with insufficient training data.